
Vespa Guide for Solr Users | Vespa Blog
Vespa functionality from a Solr user’s perspective. Where it overlaps and where it differs. Why would you migrate and what challenges to expect.| Vespa Blog
An attribute is a schema keyword,| docs.vespa.ai
Vespa can scale in multiple scaling dimensions:| docs.vespa.ai
Vespa functionality from a Solr user’s perspective. Where it overlaps and where it differs. Why would you migrate and what challenges to expect.| Vespa Blog

Improvements made to triple the query performance of lexical search in Vespa.| Vespa Blog
Announcing Matryoshka (dimension flexibility) and binary quantization in Vespa and how these features slashes costs.| Vespa Blog

A guide on implementing advanced video retrieval at scale using Vespa and TwelveLabs’ multi-modal embedding models.| Vespa Blog

This blog post describes Vespa’s industry leading support for combining approximate nearest neighbor search, or vector search, with query constraints to solve real-world search and recommendation problems at scale.| Vespa Blog

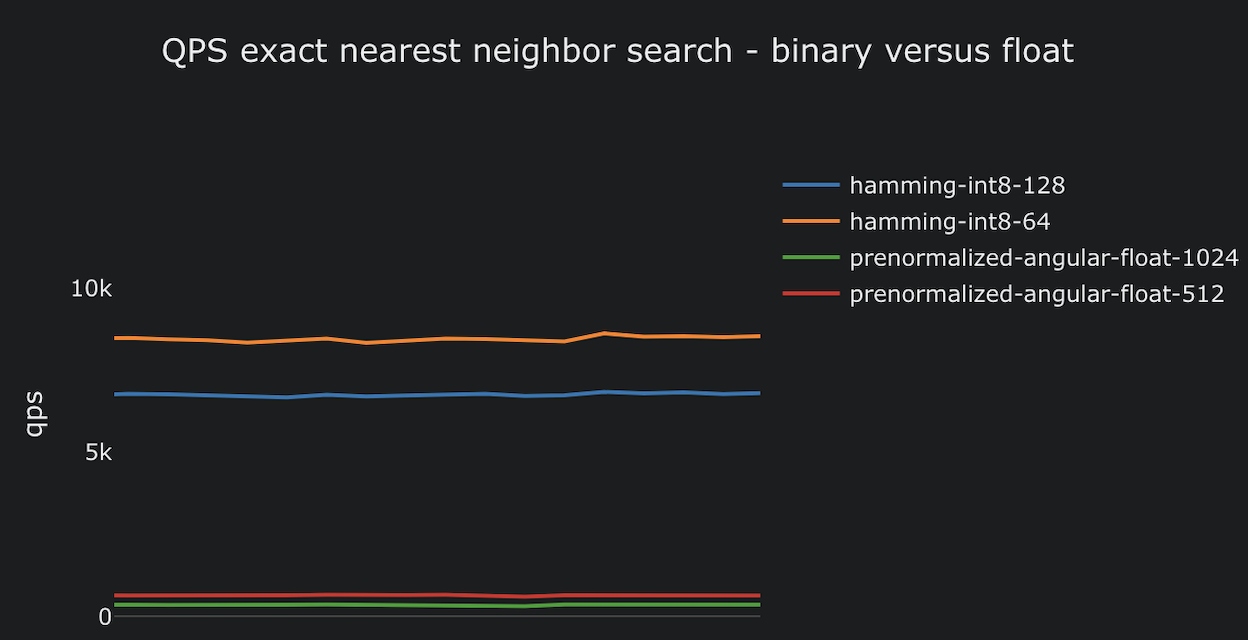
Part one in a blog post series on billion-scale vector search. This post covers using nearest neighbor search with compact binary representations and bitwise hamming distance.| Vespa Blog
numeric| docs.vespa.ai
This guide is a practical introduction to using Vespa nearest neighbor search query operator and how to combine nearest| docs.vespa.ai

Three comprehensive guides to using the Cohere Embed v3 binary embeddings with Vespa.| Vespa Blog

Announcing multi-vector indexing support in Vespa, which allows you to index multiple vectors per document and retrieve documents by the closest vector in each document.| Vespa Blog

Using the “shortening” properties of OpenAI v3 embedding models to greatly reduce latency/cost while retaining near-exact quality| Vespa Blog

This is the first blog post in a series on hybrid search. This first post focuses on efficient hybrid retrieval and representational approaches in IR| Vespa Blog
A new search experience for Vespa-related content - powered by Vespa, LangChain, and OpenAI’s chatGPT model - our motivation for building it, features, limitations, and how we made it.| Vespa Blog
