DeepSeek shook the market to start the week, sending AI heavyweight Nvidia down 17% on Monday, wiping out $600 billion in market cap, while other AI hardware names fell up to 30%. This is enough to make any investor panic, and it boiled down to one mission-critical question – did the model’s release fundamentally rewrite the AI capex story? The market’s readthrough is that Big Tech has now been overspending on AI. However, The I/O Fund believes that readthrough is wrong, it’s not that...| IO Fund
Discover how Alibaba's Qwen 2.5-Max AI model with Mixture-of-Experts architecture outperforms DeepSeek V3 in key benchmarks, challenges OpenAI, and revolutionizes healthcare, finance, and content creation. Explore technical breakthroughs and industry implications.| Deepak Gupta | AI & Cybersecurity Innovation Leader | Founder's Journey from ...
AI Mode is transforming Google Search beyond recognition, and SEO isn’t ready. This article explains how generative search works, why traditional tactics are falling short, and what marketers must do to adapt.| iPullRank
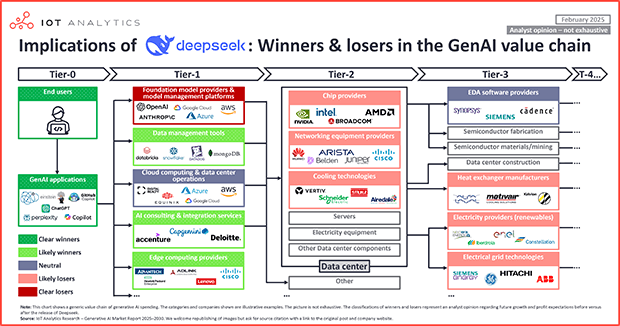
In short The recent release of DeepSeek’s R1 model has shaken tech stocks, with shares of some market participants (e.g., NVIDIA) down ~20% since January 27, 2025. R1 is largely open, on par with leading proprietary models, appears to have been trained at significantly lower cost, and is cheaper to use in terms of API access, all of which point to an innovation that may change competitive dynamics in the field of Generative AI. IoT Analytics sees end users and AI applications providers as t...| IoT Analytics
We propose a Software Product Line approach for expressing and generating combinations of LLMs, e.g. using a Mixture of Experts technique| Modeling Languages
So much has happened in the past 6 months since I first wrote about the open vs closed model race. In this follow-up, I cover how recent developments continue to fan the flames in this heated battle.| nextbigteng.substack.com
Explaining Mixture of Experts LLM (MoE): GPT4 is just 8 smaller Expert models; Mixtral is just 8 Mistral models. See the advantages and disadvantages of MoE. Find out how to calculate their number of parameters.| TensorOps