
Introduction to Diffusion Models for Machine Learning | SuperAnnotate
Dive into diffusion models: AI's breakthrough in generating realistic images and reshaping technology's creative front.| SuperAnnotate
Dive into diffusion models: AI's breakthrough in generating realistic images and reshaping technology's creative front.| SuperAnnotate
Diffusion models have demonstrated strong results on image synthesis in past years. Now the research community has started working on a harder task—using it for video generation. The task itself is a superset of the image case, since an image is a video of 1 frame, and it is much more challenging because: It has extra requirements on temporal consistency across frames in time, which naturally demands more world knowledge to be encoded into the model.| lilianweng.github.io

Personal blog of Michal Pándy. Come for the AI, stay for the jokes.| Michal Pándy
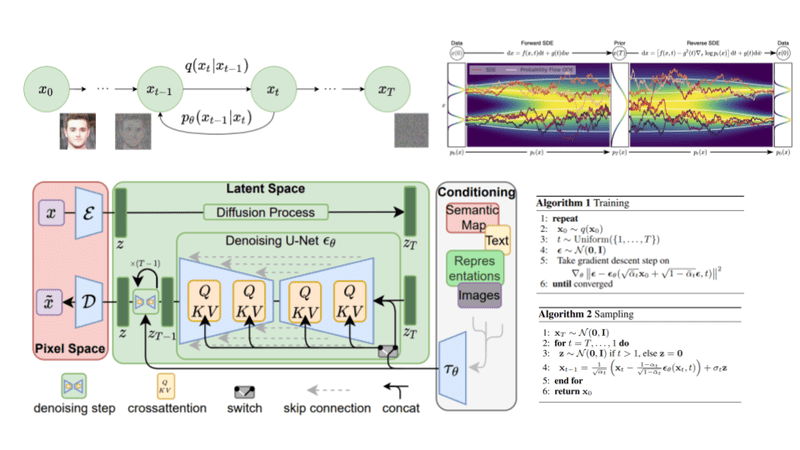
A deep dive into the mathematics and the intuition of diffusion models. Learn how the diffusion process is formulated, how we can guide the diffusion, the main principle behind stable diffusion, and their connections to score-based models.| AI Summer

We’re on a journey to advance and democratize artificial intelligence through open source and open science.| huggingface.co
Translations: Chinese, Vietnamese. (V2 Nov 2022: Updated images for more precise description of forward diffusion. A few more images in this version) AI image generation is the most recent AI capability blowing people’s minds (mine included). The ability to create striking visuals from text descriptions has a magical quality to it and points clearly to a shift in how humans create art. The release of Stable Diffusion is a clear milestone in this development because it made a high-performanc...| jalammar.github.io
Here comes the Part 3 on learning with not enough data (Previous: Part 1 and Part 2). Let’s consider two approaches for generating synthetic data for training. Augmented data. Given a set of existing training samples, we can apply a variety of augmentation, distortion and transformation to derive new data points without losing the key attributes. We have covered a bunch of augmentation methods on text and images in a previous post on contrastive learning.| lilianweng.github.io
