Co-authored by Neel Nanda and Jess Smith Check out Concrete Steps for Getting Started in Mechanistic Interpretability for a better starting point Why does this exist? People often get intimidated when trying to get into AI or AI Alignment research. People often think that the gulf betwee| Neel Nanda
Deprecated, see a much more up-to-date post here Disclaimer : This post mostly links to resources I've made. I feel somewhat bad about this, sorry! Transformer MI is a pretty young and small field and there just aren't many people making educational resources tailored to it. So| Neel Nanda
In any autoregressive model, the prediction of the future tokens is based on some preceding context. However, not all the tokens within this context equally contribute to the prediction, because some…| Medium
Training LLMs often feels like alchemy, but understanding and optimizing the performance of your models doesn't have to. This book aims to demystify the science of scaling language models on TPUs: how TPUs work and how they communicate with each other, how LLMs run on real hardware, and how to parallelize your models during training and inference so they run efficiently at massive scale. If you've ever wondered “how expensive should this LLM be to train” or “how much memory do I need to...| jax-ml.github.io
Just one year after its launch, ChatGPT had more than 100M weekly users. In order to meet this explosive demand, the team at OpenAI had to overcome several scaling challenges. An exclusive deepdive.| newsletter.pragmaticengineer.com
Discussions: Hacker News (98 points, 19 comments), Reddit r/MachineLearning (164 points, 20 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Persian, Russian, Spanish 2021 Update: I created this brief and highly accessible video intro to BERT The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natural Language Processing or NLP for short). Our conceptual understanding of how best to represent words and se...| jalammar.github.io
Discussions: Hacker News (64 points, 3 comments), Reddit r/MachineLearning (219 points, 18 comments) Translations: Simplified Chinese, French, Korean, Russian, Turkish This year, we saw a dazzling application of machine learning. The OpenAI GPT-2 exhibited impressive ability of writing coherent and passionate essays that exceed what we anticipated current language models are able to produce. The GPT-2 wasn’t a particularly novel architecture – it’s architecture is very similar to the de...| jalammar.github.io
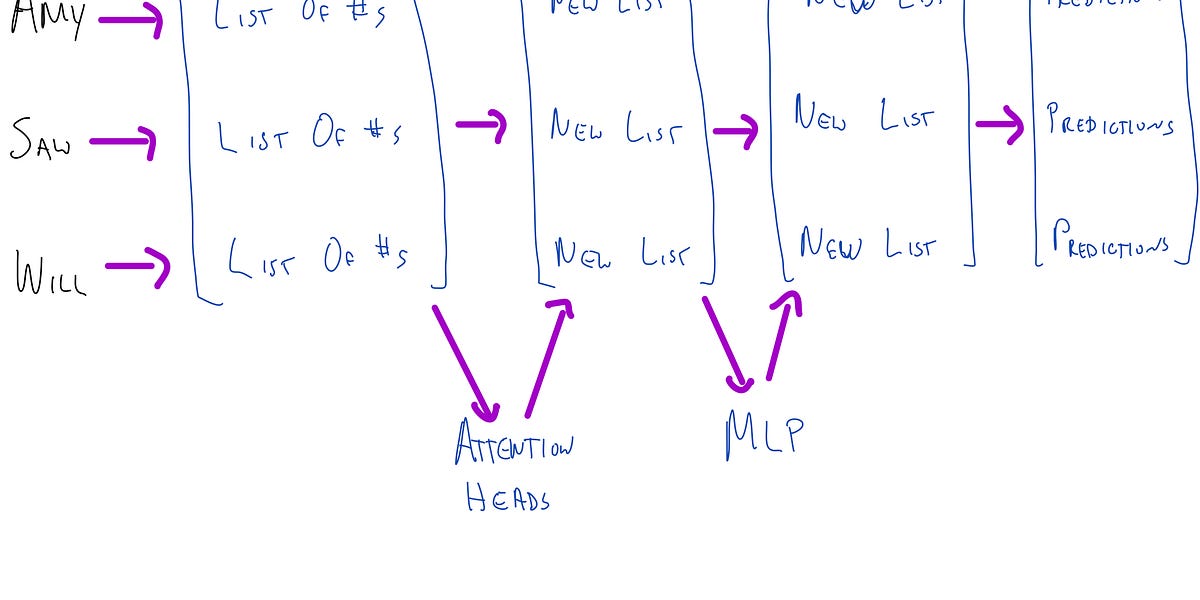
Ever since its introduction in the 2017 paper, Attention is All You Need, the Transformer model architecture has taken the deep-learning world by storm. Initially introduced for machine translation, it has become the tool of choice for a wide range of domains, including text, audio, video, and others. Transformers have also driven most of the massive increases in model scale and capability in the last few years. OpenAI’s GPT-3 and Codex models are Transformers, as are DeepMind’s Gopher mo...| Made of Bugs
Nine philosophers explore the various issues and questions raised by the newly released language model, GPT-3, in this edition of Philosophers On, guest edited by Annette Zimmermann. Introduction Annette Zimmermann, guest editor GPT-3, a powerful, 175 billion parameter language model developed recently by OpenAI, has been galvanizing public debate and controversy. As the MIT Technology Review puts| Daily Nous - news for & about the philosophy profession
Welcome to episode 4: LLMS In this episode we talk about LLMs, the predicted impact they will have on jobs, the kind of work they can help with and how you can go about using them.| Everything Delivery
We take a deep dive into the inner workings of the wildly popular AI chatbot, ChatGPT. If you want to know how its generative AI magic happens, read on.| ZDNET