Vespa functionality from a Solr user’s perspective. Where it overlaps and where it differs. Why would you migrate and what challenges to expect.| Vespa Blog
Advances in Vespa features and performance include Lexical Search Query Performance, Pyvespa Relevance Evaluator, Global-phase rank-score-drop-limit, and Compact tensor representation.| Vespa Blog
Where should you begin if you plan to implement search functionality but have not yet collected data from user interactions to train ranking models?| Vespa Blog
This blog post describes Vespa’s industry leading support for combining approximate nearest neighbor search, or vector search, with query constraints to solve real-world search and recommendation problems at scale.| Vespa Blog
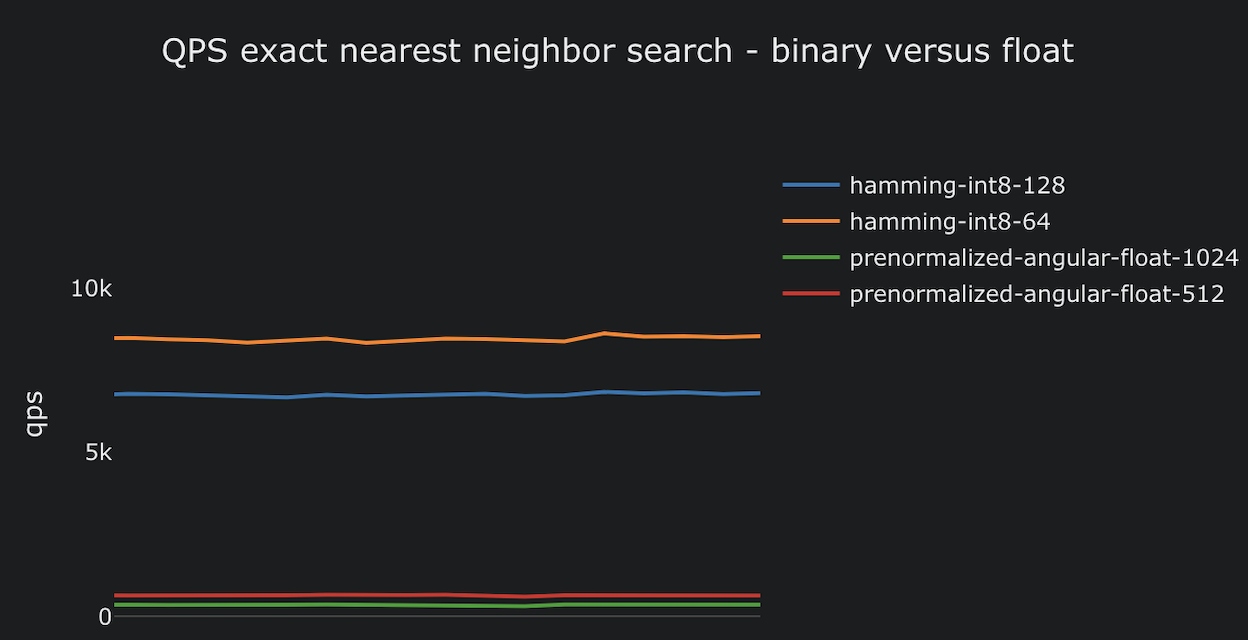
Part one in a blog post series on billion-scale vector search. This post covers using nearest neighbor search with compact binary representations and bitwise hamming distance.| Vespa Blog
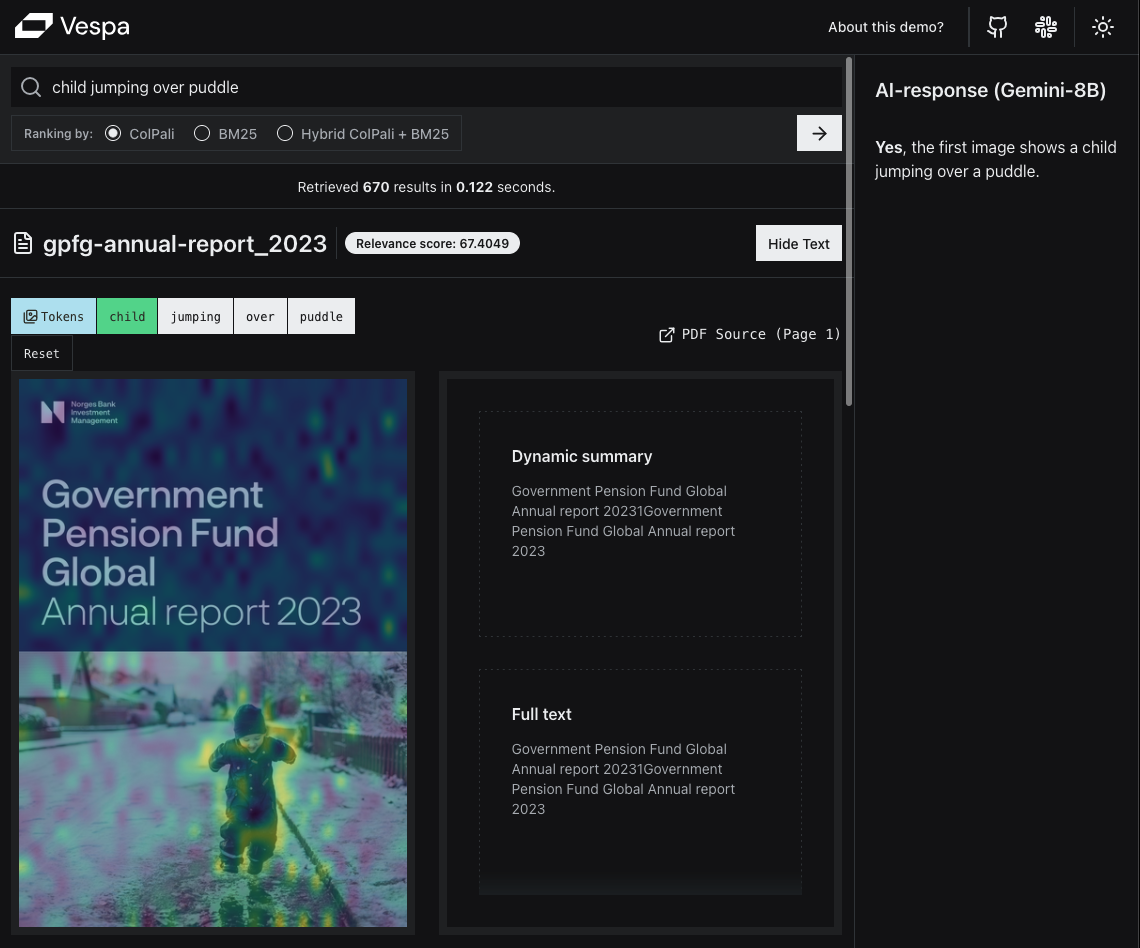
This is a technical blog post on developing an end-to-end Visual RAG application powered by Vespa. It has link to a live demo application, and will walk you through why and how we built it, as well as give you the code to build your own Visual RAG application with your own data.| Vespa Blog
This is the first blog post in a series on hybrid search. This first post focuses on efficient hybrid retrieval and representational approaches in IR| Vespa Blog
Part two in a blog post series on billion-scale vector search with Vespa. This post explores the many trade-offs related to nearest neighbor search.| Vespa Blog