
Vespa Quickstart - How to build an Application with Vespa | Vespa Blog
Get started with Vespa and set up your first application. Build your first Vespa instance using Python.| Vespa Blog
Read the Vespa grouping guide first, for examples and an introduction to grouping -| docs.vespa.ai
An attribute is a schema keyword,| docs.vespa.ai
This tutorial will guide you through setting up a simple text search application. | docs.vespa.ai
This reference documents the full Vespa indexing language.| docs.vespa.ai
The nativeRank text match score is a reasonably good text| docs.vespa.ai
A document summary is the information that is shown for each document in a query result.| docs.vespa.ai
Get started with Vespa and set up your first application. Build your first Vespa instance using Python.| Vespa Blog
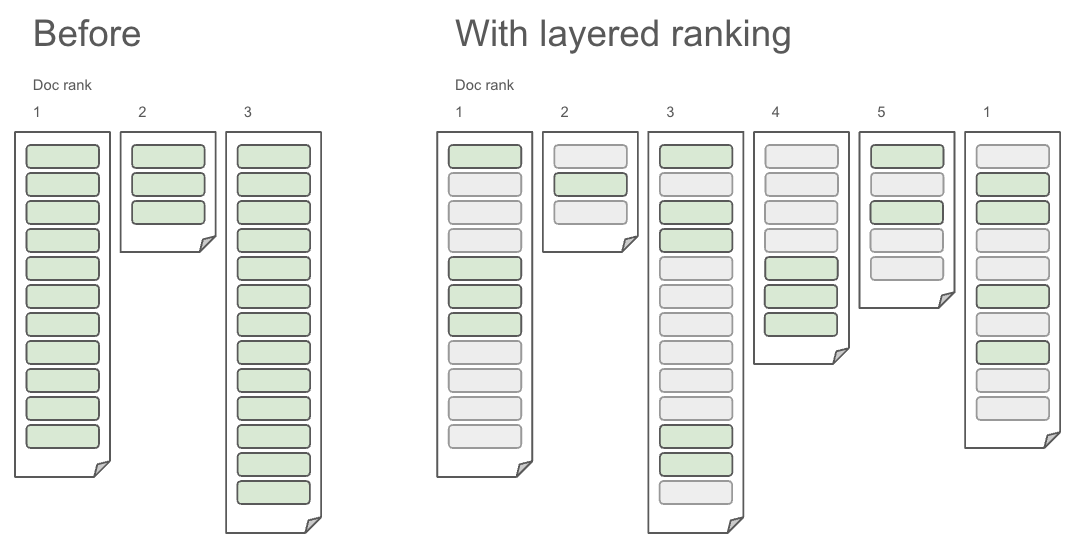
Introducing layered ranking: The missing piece for context engineering at scale.| Vespa Blog
content| docs.vespa.ai
Proton is Vespa's search core and runs on each content node as the vespa-proton-bin process.| docs.vespa.ai
Vespa can scale in multiple scaling dimensions:| docs.vespa.ai

Vespa functionality from a Solr user’s perspective. Where it overlaps and where it differs. Why would you migrate and what challenges to expect.| Vespa Blog
Advances in Vespa features and performance include Lexical Search Query Performance, Pyvespa Relevance Evaluator, Global-phase rank-score-drop-limit, and Compact tensor representation.| Vespa Blog

Improvements made to triple the query performance of lexical search in Vespa.| Vespa Blog
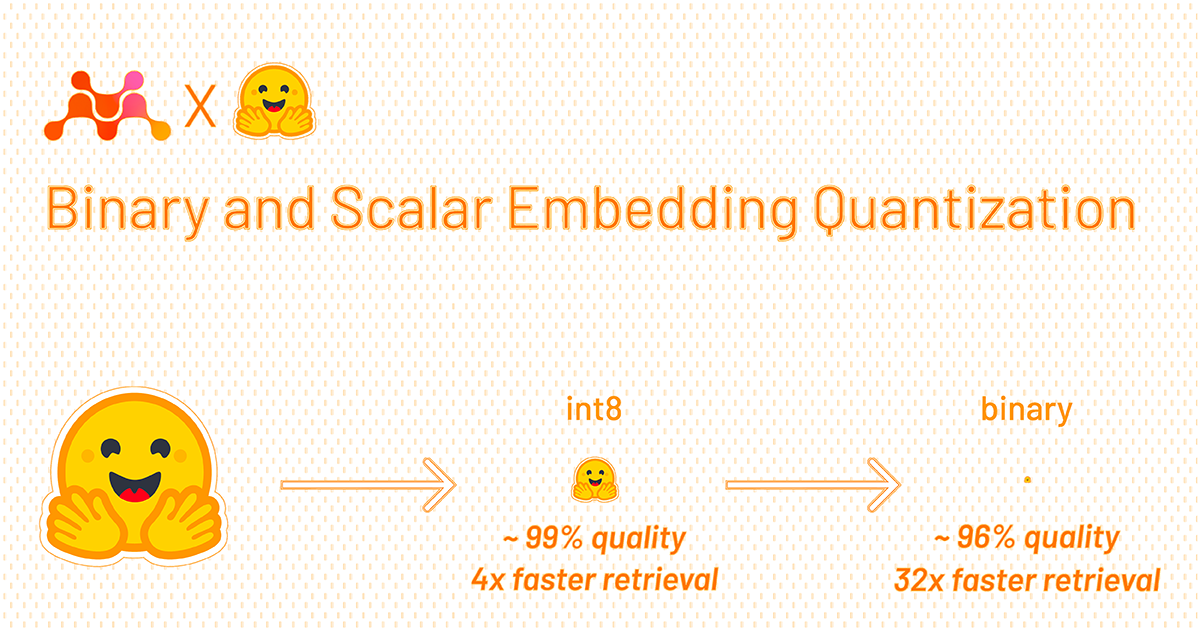
Announcing Matryoshka (dimension flexibility) and binary quantization in Vespa and how these features slashes costs.| Vespa Blog

Where should you begin if you plan to implement search functionality but have not yet collected data from user interactions to train ranking models?| Vespa Blog

Connecting the ColPali model with Vespa for complex document format retrieval.| Vespa Blog

This blog post describes Vespa’s industry leading support for combining approximate nearest neighbor search, or vector search, with query constraints to solve real-world search and recommendation problems at scale.| Vespa Blog

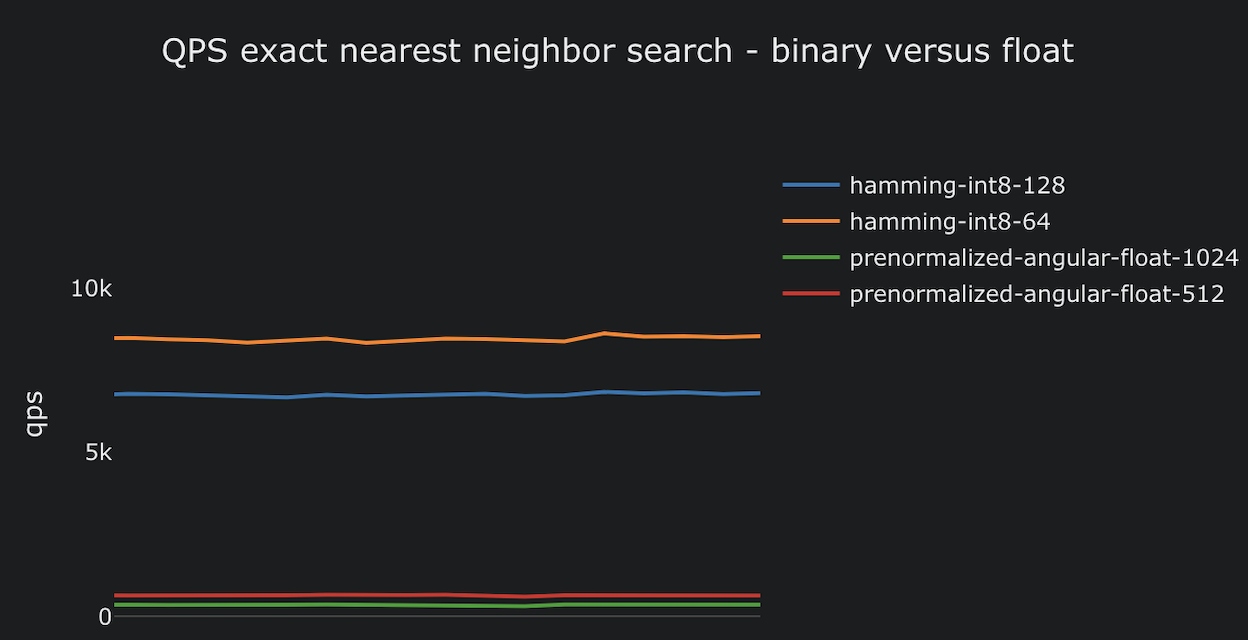
Part one in a blog post series on billion-scale vector search. This post covers using nearest neighbor search with compact binary representations and bitwise hamming distance.| Vespa Blog
Refer to Vespa Support for more support options.| docs.vespa.ai
Using machine-learned models from Vespa Cloud| cloud.vespa.ai
A schema defines a document type and what we want to compute over it, the| docs.vespa.ai
Refer to the overview.| docs.vespa.ai
Vespa models data as documents.| docs.vespa.ai
An application package is a set of files in a specific structure that defines a deployable application.| docs.vespa.ai
This document describes the Vespa Annotations API; its purpose and use cases along with some usage examples.| docs.vespa.ai
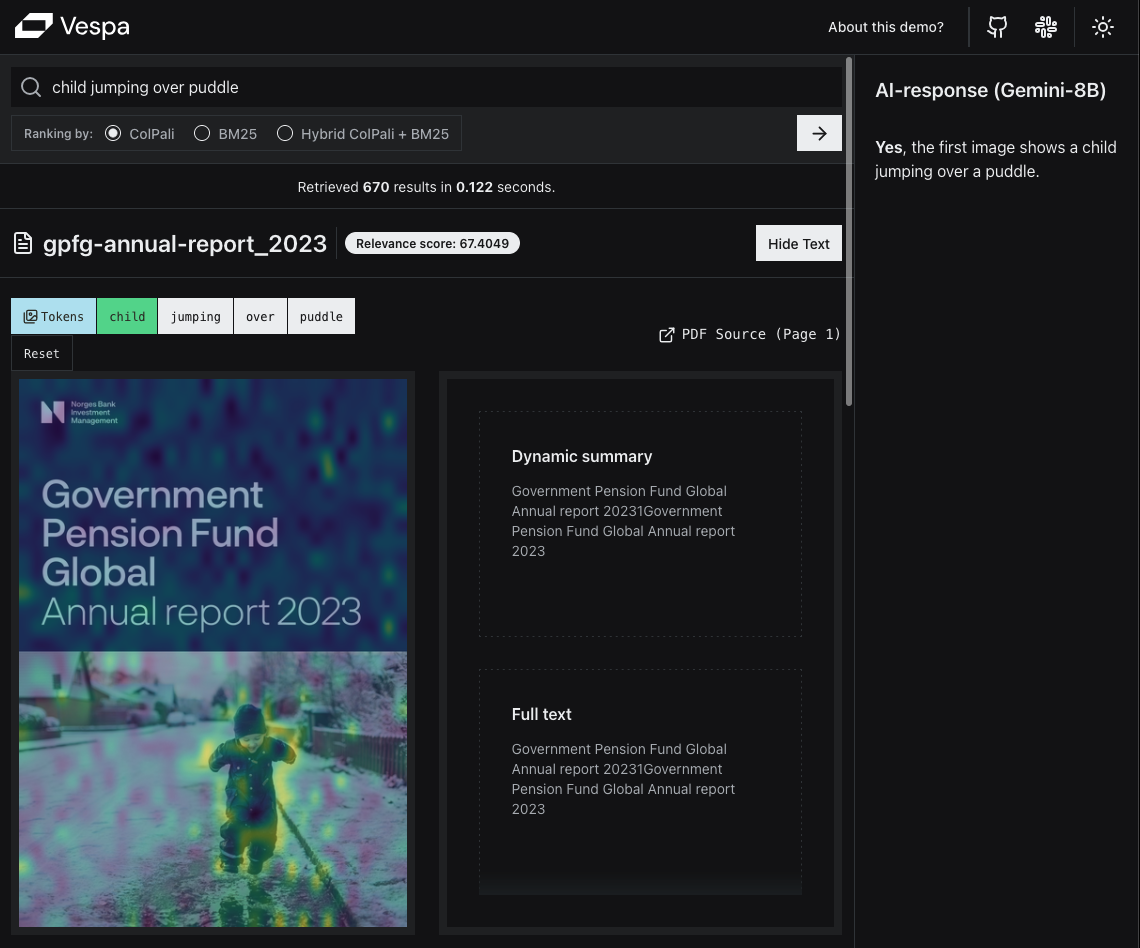
This is a technical blog post on developing an end-to-end Visual RAG application powered by Vespa. It has link to a live demo application, and will walk you through why and how we built it, as well as give you the code to build your own Visual RAG application with your own data.| Vespa Blog
This is the reference for the search part of the container config.| docs.vespa.ai
A Query Profile is a named collection of search request parameters given in the configuration.| docs.vespa.ai
The| docs.vespa.ai
numeric| docs.vespa.ai
This guide is a practical introduction to using Vespa nearest neighbor search query operator and how to combine nearest| docs.vespa.ai

Three comprehensive guides to using the Cohere Embed v3 binary embeddings with Vespa.| Vespa Blog
We’re on a journey to advance and democratize artificial intelligence through open source and open science.| huggingface.co
add| docs.vespa.ai
Query features| docs.vespa.ai
Lucene Linguistics is a custom linguistics implementation of the| docs.vespa.ai
Vespa uses a linguistics module to process text in queries and documents during indexing and searching.| docs.vespa.ai
Use the Vespa Query API to query, rank and organize data. Example:| docs.vespa.ai
This guide demonstrates tokenization, linguistic processing and matching over string | docs.vespa.ai
This document describes how to tune certain features of an application for high query serving performance,| docs.vespa.ai

Announcing multi-vector indexing support in Vespa, which allows you to index multiple vectors per document and retrieve documents by the closest vector in each document.| Vespa Blog

Announcing long-context ColBERT, giving it larger context for scoring and simplifying long-document RAG applications.| Vespa Blog

The new IN operator is a shorthand for multiple OR conditions, enabling writing more concise queries with better performance| Vespa Blog

This is the first blog post in a series on hybrid search. This first post focuses on efficient hybrid retrieval and representational approaches in IR| Vespa Blog
Vespa allows expressing multi-phased retrieval and ranking of documents. The retrieval phase is done close to the data in the content nodes,| docs.vespa.ai
For an introduction to nearest neighbor search, see nearest neighbor search documentation, | docs.vespa.ai

Part two in a blog post series on billion-scale vector search with Vespa. This post explores the many trade-offs related to nearest neighbor search.| Vespa Blog
Refer to the Query API guide for API examples.| docs.vespa.ai
A new search experience for Vespa-related content - powered by Vespa, LangChain, and OpenAI’s chatGPT model - our motivation for building it, features, limitations, and how we made it.| Vespa Blog
