Note: If you’ll forgive the shameless self-promotion, applications for my MATS stream are open until Sept 12. I help people write a mech interp paper…| www.alignmentforum.org
Interpretability provides access to AI systems' internal mechanisms, offering a window into how models process information and make decisions.| www.alignmentforum.org
In the decade that I have been working on AI, I’ve watched it grow from a tiny academic field to arguably the most important economic and geopolitical issue in the world. In all that time, perhaps the most important lesson I’ve learned is this: the progress of the underlying technology is inexorable, driven by forces too powerful to stop, but the way in which it happens—the order in which things are built, the applications we choose, and the details of how it is rolled out to society...| www.darioamodei.com
In a recent paper in Annals of Mathematics and Philosophy, Fields medalist Timothy Gowers asks why mathematicians sometimes believe that unproved statements are likely to be true. For example, it is unknown whether \(\pi\) is a normal number (which, roughly speaking, means that every digit appears in \(\pi\) with equal| Alignment Research Center
Reliably controlling AI systems much smarter than we are is an unsolved technical problem. And while it is a solvable problem, things could very easily go off the rails during a rapid intelligence explosion. Managing this will be extremely tense; failure could easily be catastrophic. The old sorcererHas finally gone away!Now the spirits he controlsShall| SITUATIONAL AWARENESS
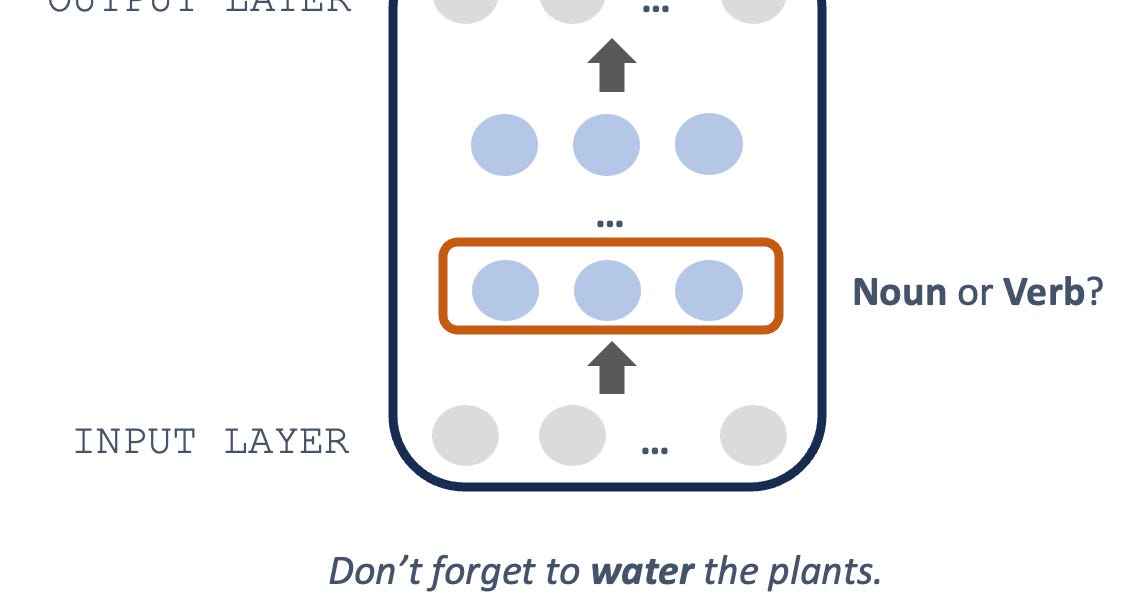
Sparse Autoencoders (SAEs) have recently become popular for interpretability of machine learning models (although sparse dictionary learning has been around since 1997). Machine learning models and LLMs are becoming more powerful and useful, but they are still black boxes, and we don’t understand how they do the things that they are capable of. It seems like it would be useful if we could understand how they work.| Adam Karvonen
Foundation models gesture at a way of interacting with information that’s at once more natural and powerful than “classic” knowledge tools. But to build the kind of rich, directly interactive information interfaces I imagine, current foundation models and embeddings are far too opaque to humans. Models and their raw outputs resist understanding. Even when we go to great lengths to try to surface what the model is “thinking” through black-box methods like prompting or dimensionality ...| thesephist.com
Transcripts of podcast episodes about existential risk from Artificial Intelligence (including AI Alignment, AI Governance, and everything else that could be decision-relevant for thinking about existential risk from AI).| The Inside View



.jpg)