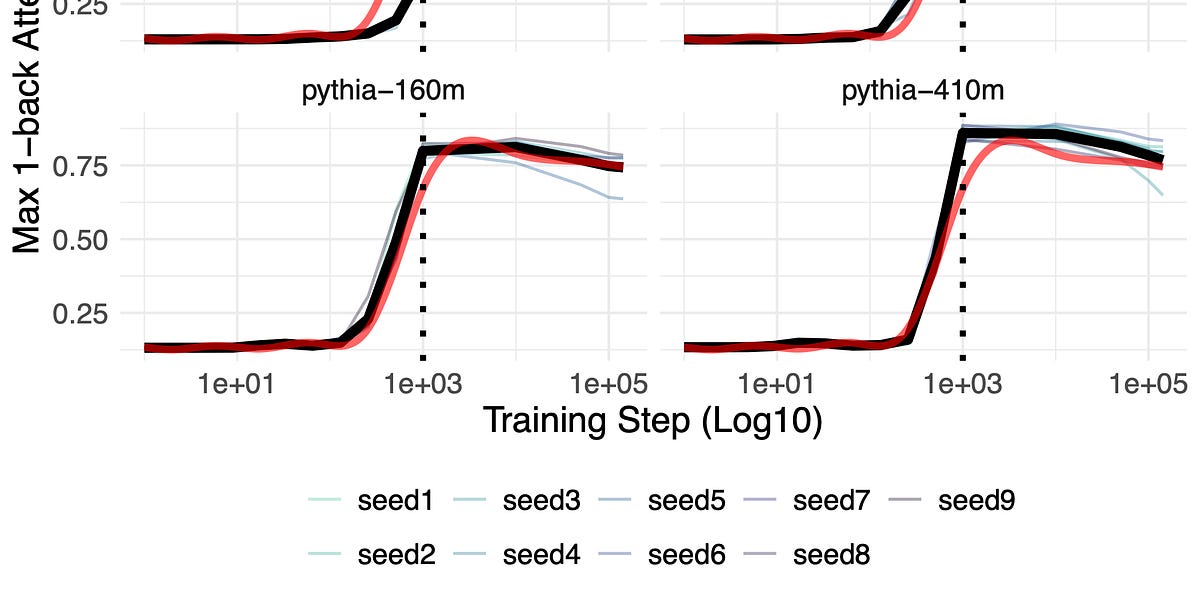
Generalizability in LLM-ology, revisited - by Sean Trott
What does it mean to say two circuits in two different models "do the same thing"?| seantrott.substack.com
What does it mean to say two circuits in two different models "do the same thing"?| seantrott.substack.com
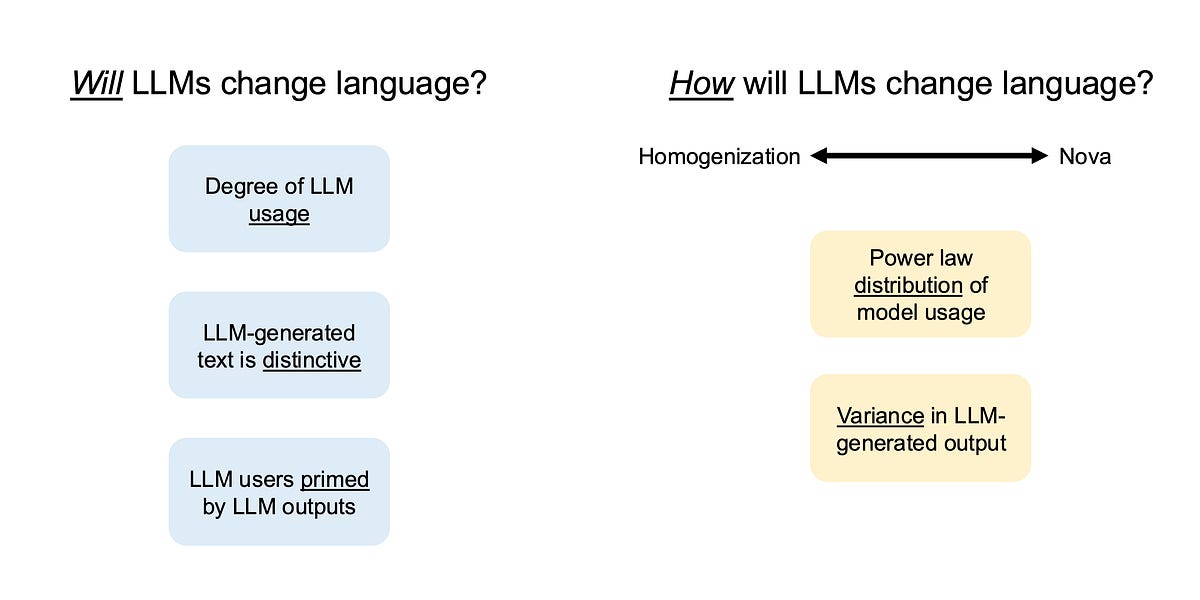
A review of emerging empirical data.| seantrott.substack.com

An update on when and how I use LLM-equipped software tools, and when (and why) I don't.| seantrott.substack.com
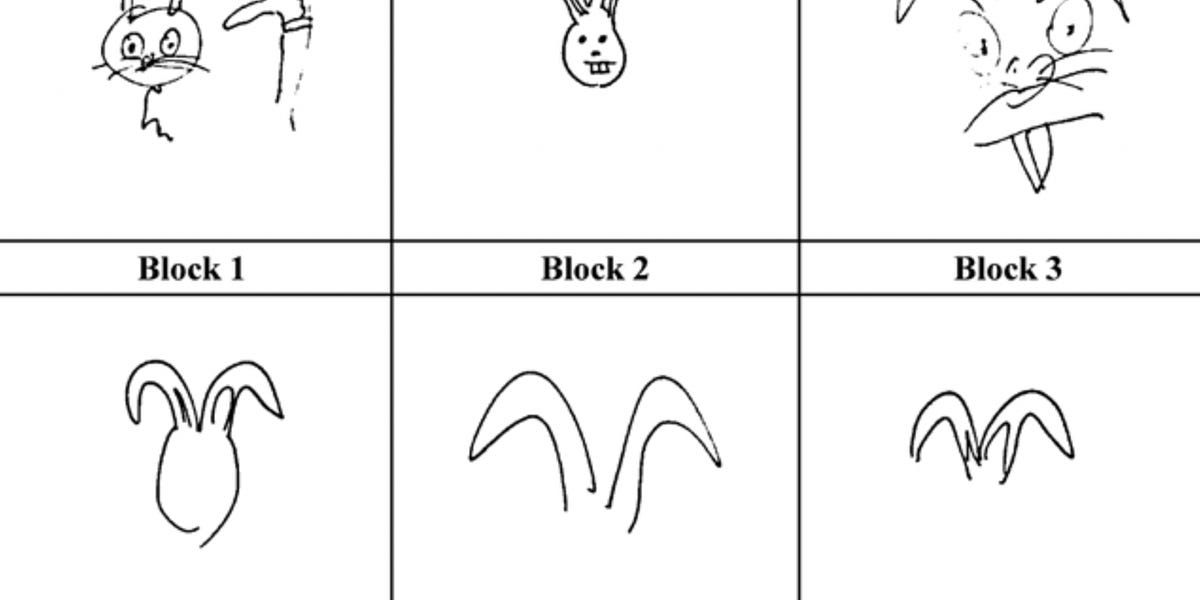
If non-arbitrariness helps with word leaning, why are languages still mostly arbitrary?| seantrott.substack.com
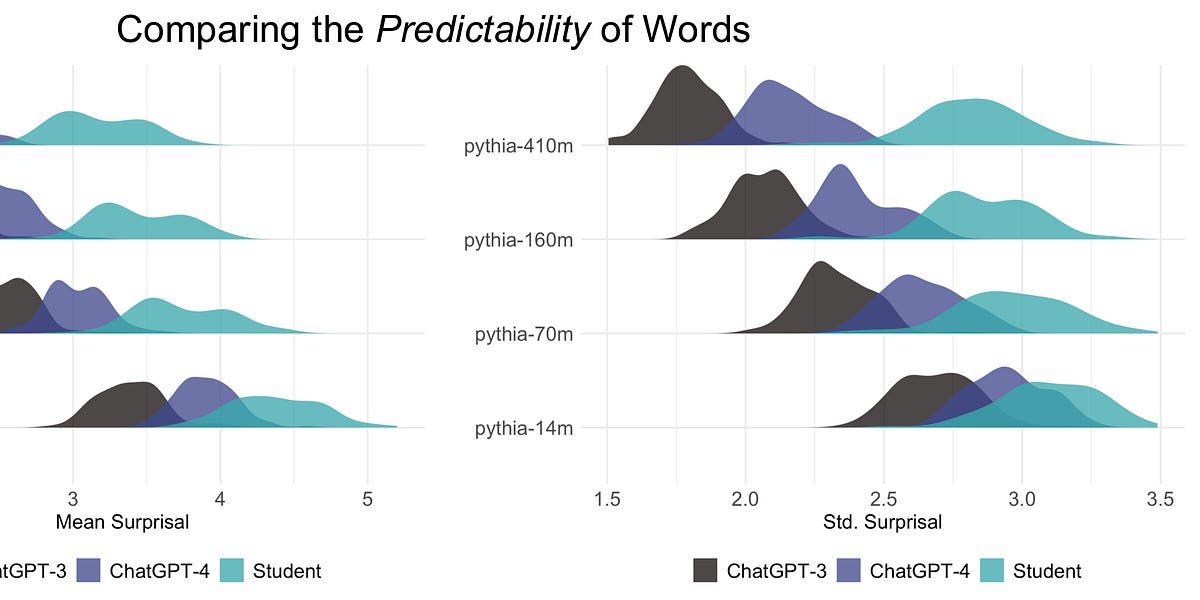
What metrics from open-source LLMs can tell us about the differences between human essays and those written by ChatGPT-3 and ChatGPT-4.| seantrott.substack.com

How can a science of LLMs keep up with technological development?| seantrott.substack.com
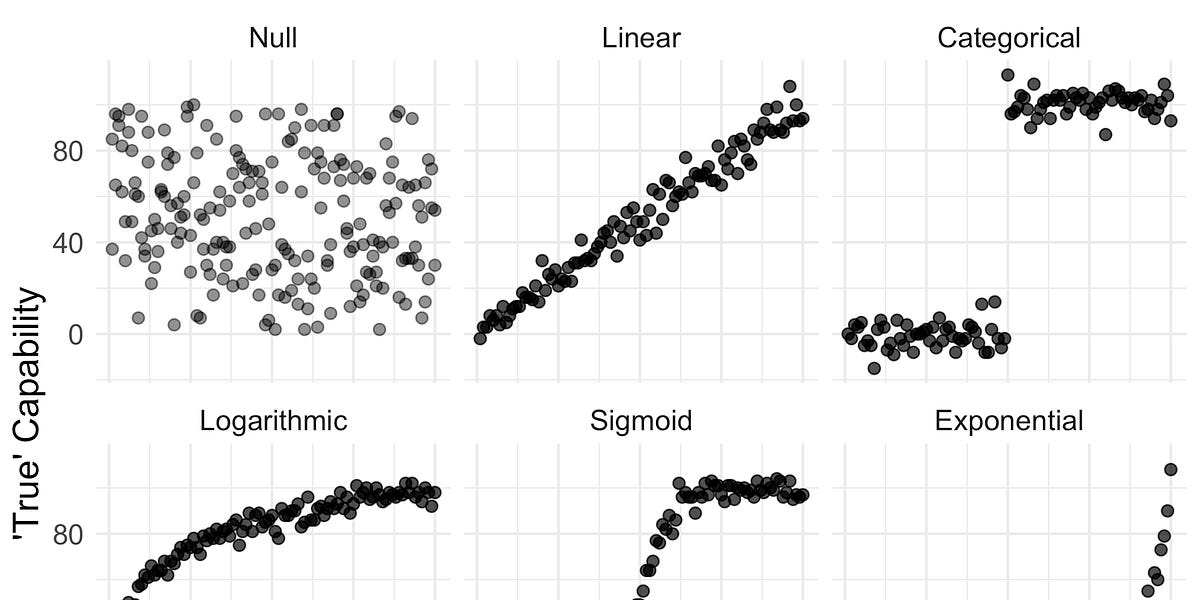
Proxies for a capability may not map linearly onto the capability itself.| seantrott.substack.com
Three hard questions for a new paradigm.| seantrott.substack.com
How to get started studying LLMs.| seantrott.substack.com

A sprawling conversation with cognitive scientist Sean Trott (Part One)| buildcognitiveresonance.substack.com
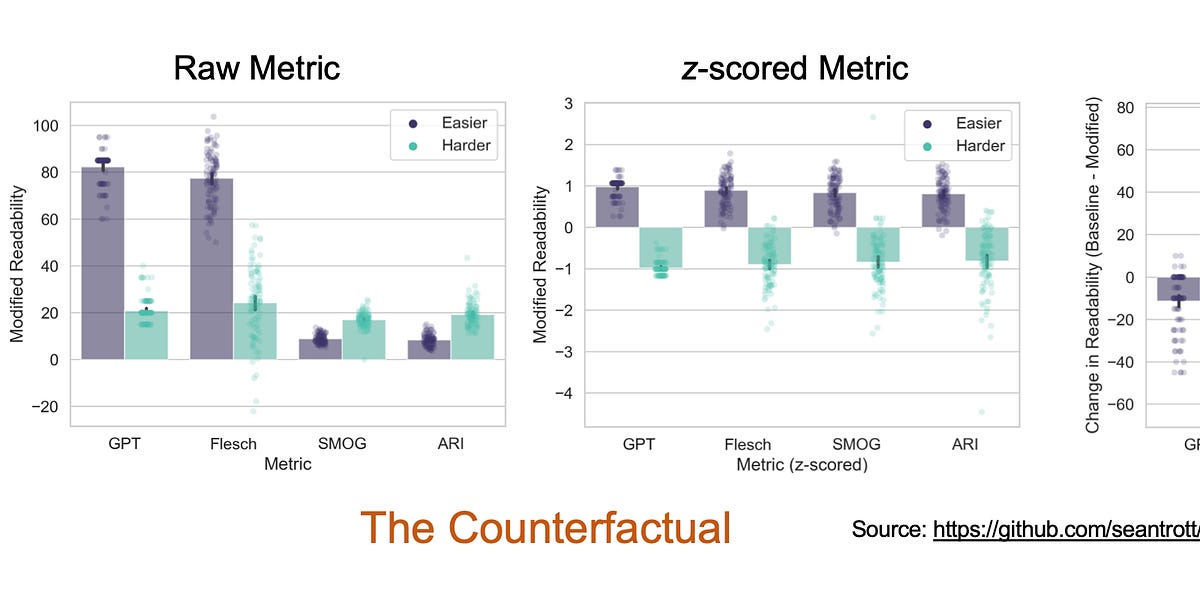
Can GPT-4 Turbo rewrite texts to make them easier or harder to read?| seantrott.substack.com

When we use LLMs as "model organisms", which humans are we modeling? And how can we overcome the problem of unrepresentative data?| seantrott.substack.com
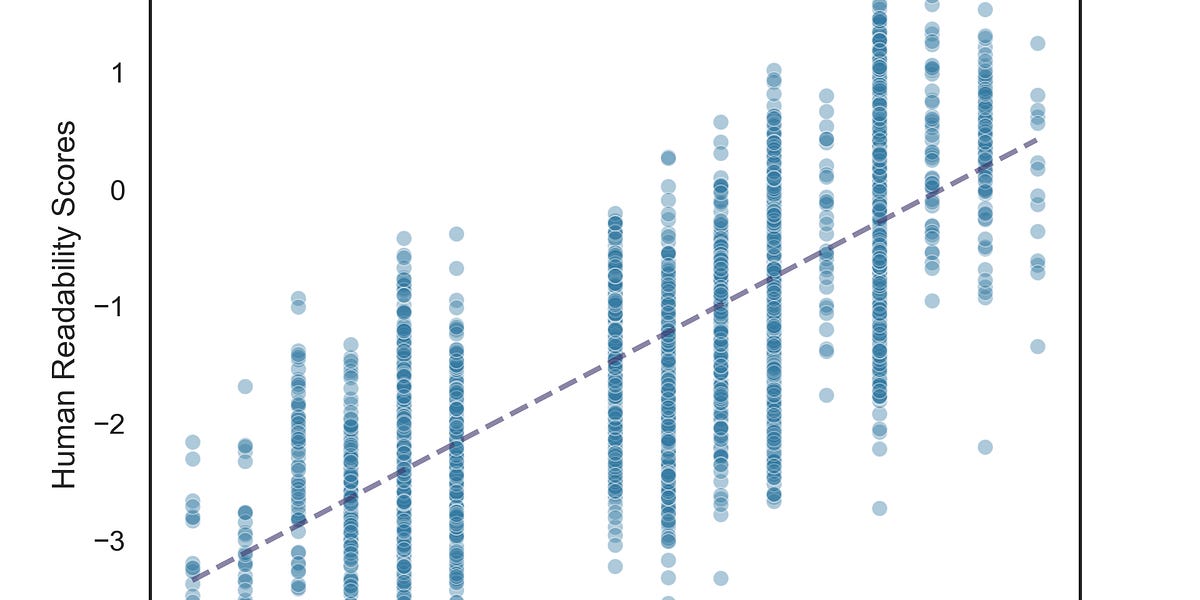
Defining, operationalizing, and measuring readability is a challenge—can LLMs help?| seantrott.substack.com

What I'll be working on this month.| seantrott.substack.com

Trade-offs between the particular and the general.| seantrott.substack.com
