
What Shapes Do Matrix Multiplications Like? [medium]
Divining order from the chaos| www.thonking.ai
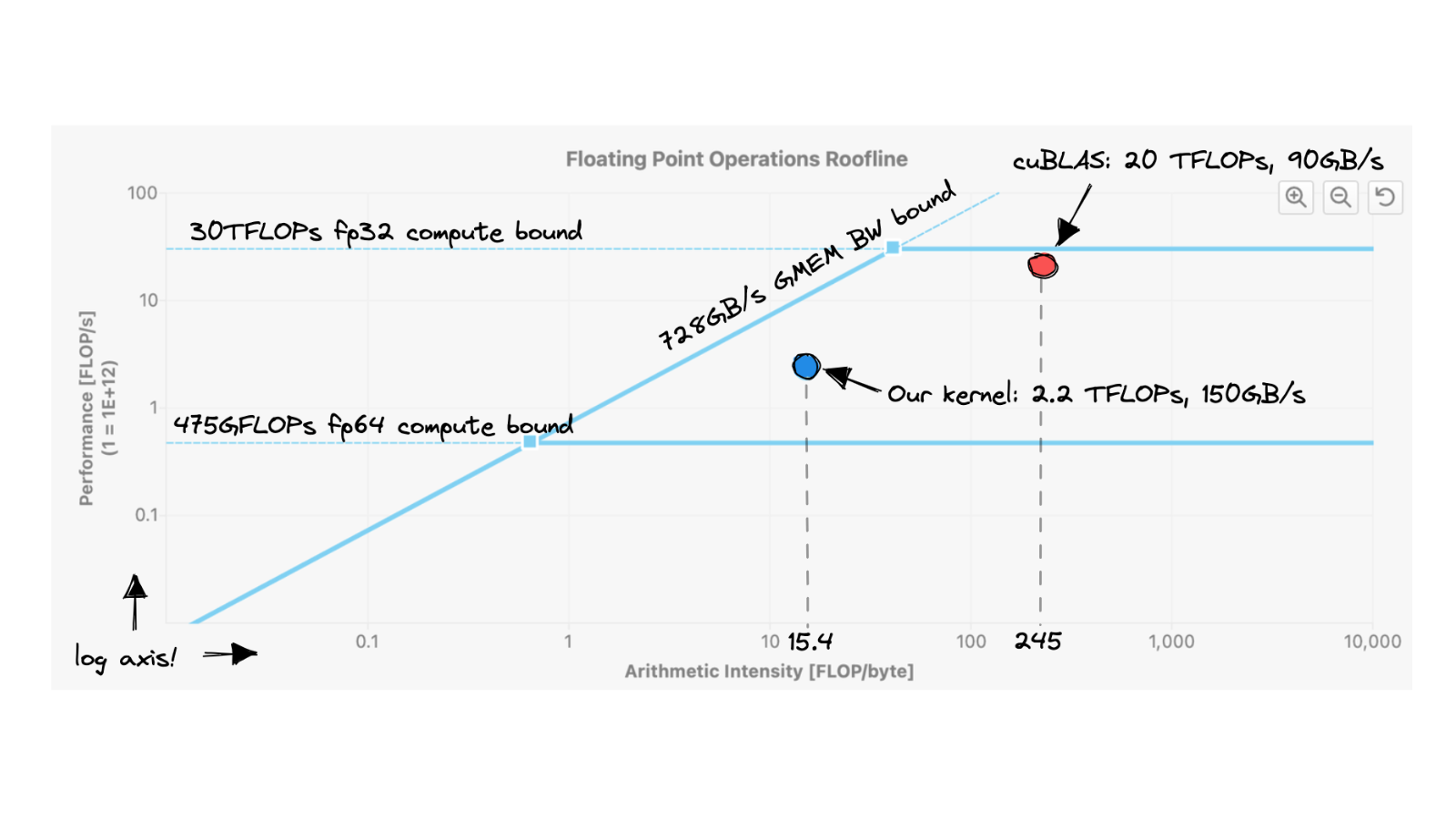
In this post, I’ll iteratively optimize an implementation of matrix multiplication written in CUDA.My goal is not to build a cuBLAS replacement, but to deepl...| siboehm.com

In our AI Scaling Laws article from late last year, we discussed how multiple stacks of AI scaling laws have continued to drive the AI industry forward, enabling greater than Moore’s Law grow…| SemiAnalysis
Making sure I don’t forget what I read.| Damek Davis’ Website
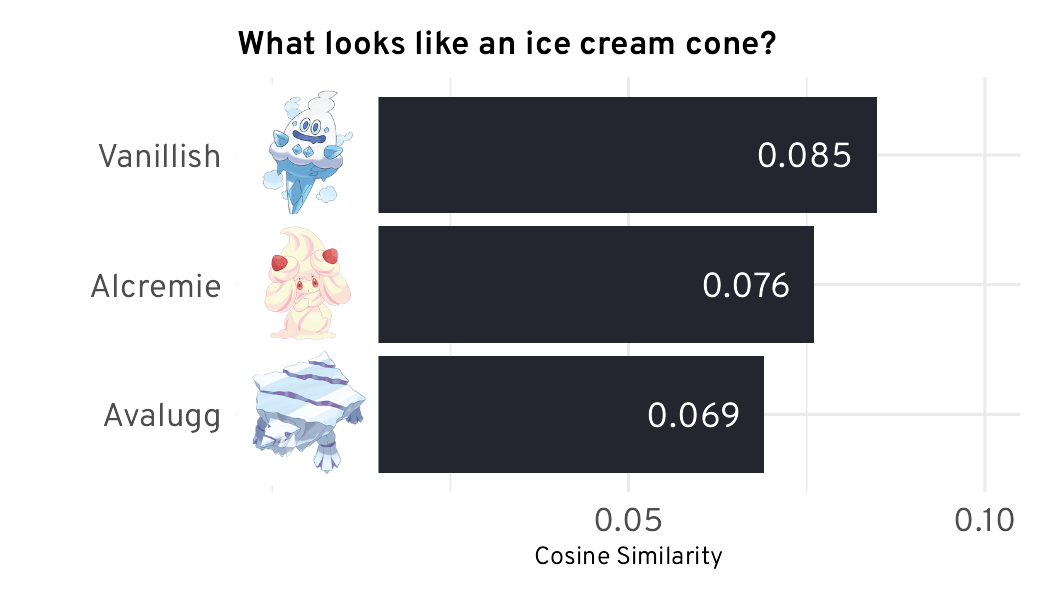
Embeddings encourage engineers to go full YOLO because it’s actually rewarding to do so!| minimaxir.com
GPUs accelerate machine learning operations by performing calculations in parallel. Many operations, especially those representable as matrix multipliers will see good acceleration right out of the box. Even better performance can be achieved by tweaking operation parameters to efficiently use GPU resources. The performance documents present the tips that we think are most widely useful.| NVIDIA Docs
GPUs accelerate machine learning operations by performing calculations in parallel. Many operations, especially those representable as matrix multipliers will see good acceleration right out of the box. Even better performance can be achieved by tweaking operation parameters to efficiently use GPU resources. The performance documents present the tips that we think are most widely useful.| NVIDIA Docs
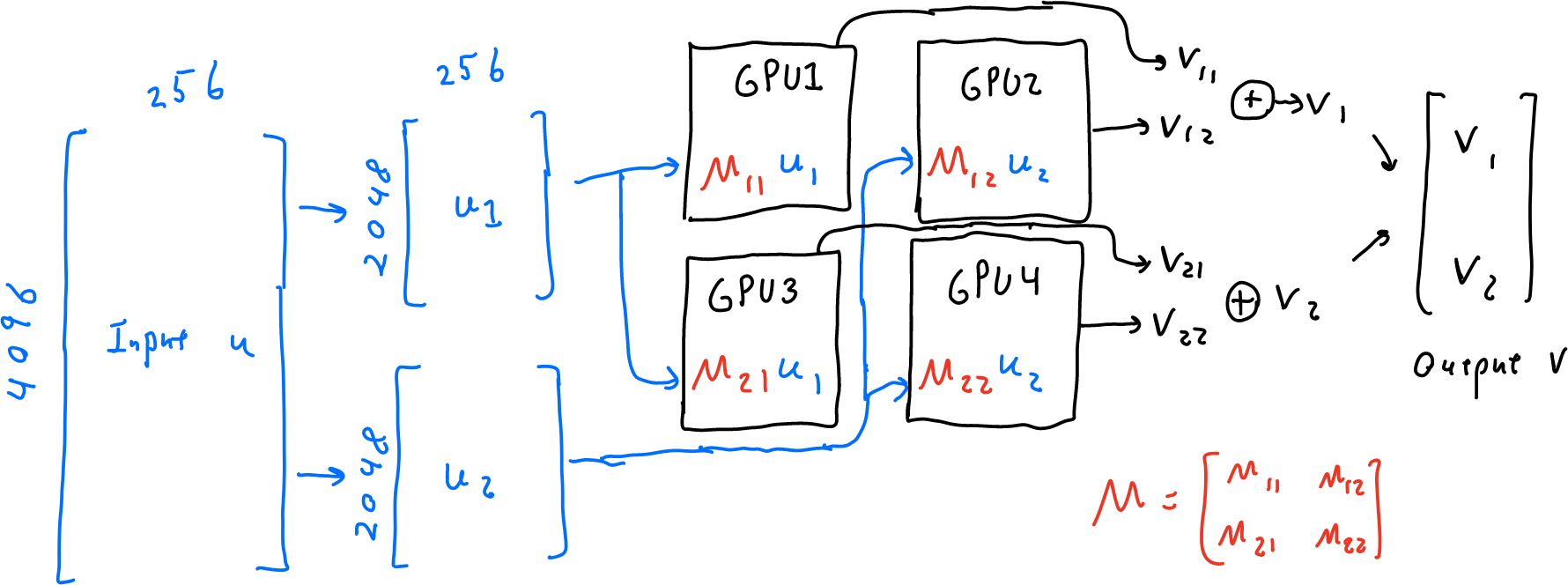
Thanks to Hao Zhang, Kayvon Fatahalian, and Jean-Stanislas Denain for helpful discussions and comments. Addendum and erratum. See here [https://kipp.ly/blog/transformer-inference-arithmetic/] for an excellent discussion of similar ideas by Kipply Chen. In addition, James Bradbury has pointed out to me that some of the constants in this| Bounded Regret
