
Achieve 23x LLM Inference Throughput & Reduce p50 Latency
In this blog, we discuss continuous batching, a critical systems-level optimization that improves both throughput and latency under load for LLMs.| Anyscale
GPUs accelerate machine learning operations by performing calculations in parallel. Many operations, especially those representable as matrix multipliers will see good acceleration right out of the box. Even better performance can be achieved by tweaking operation parameters to efficiently use GPU resources. The performance documents present the tips that we think are most widely useful.| NVIDIA Docs
GPUs accelerate machine learning operations by performing calculations in parallel. Many operations, especially those representable as matrix multipliers will see good acceleration right out of the box. Even better performance can be achieved by tweaking operation parameters to efficiently use GPU resources. The performance documents present the tips that we think are most widely useful.| NVIDIA Docs
kipply's blog about stuff she does or reads about or observes| kipply's blog
In this blog, we discuss continuous batching, a critical systems-level optimization that improves both throughput and latency under load for LLMs.| Anyscale
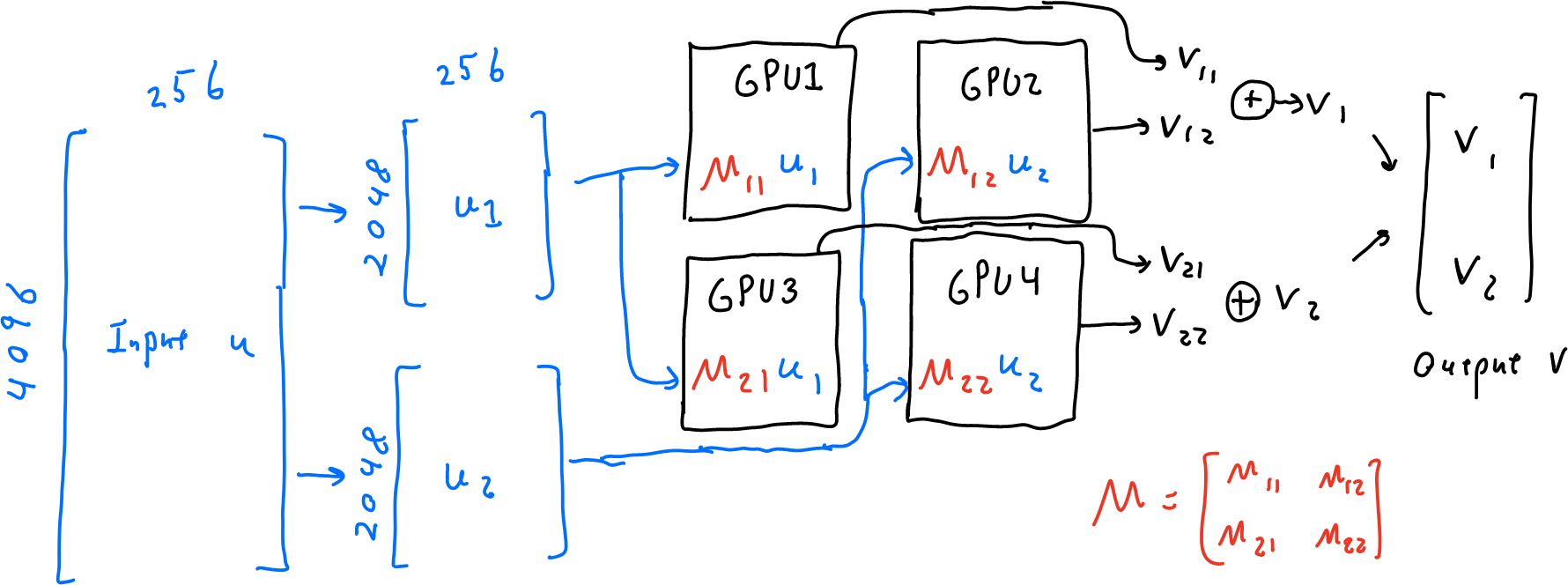
Thanks to Hao Zhang, Kayvon Fatahalian, and Jean-Stanislas Denain for helpful discussions and comments. Addendum and erratum. See here [https://kipp.ly/blog/transformer-inference-arithmetic/] for an excellent discussion of similar ideas by Kipply Chen. In addition, James Bradbury has pointed out to me that some of the constants in this| Bounded Regret
