Posts | Ash's Blog
Posts - Ash's Blog| Ash's Blog
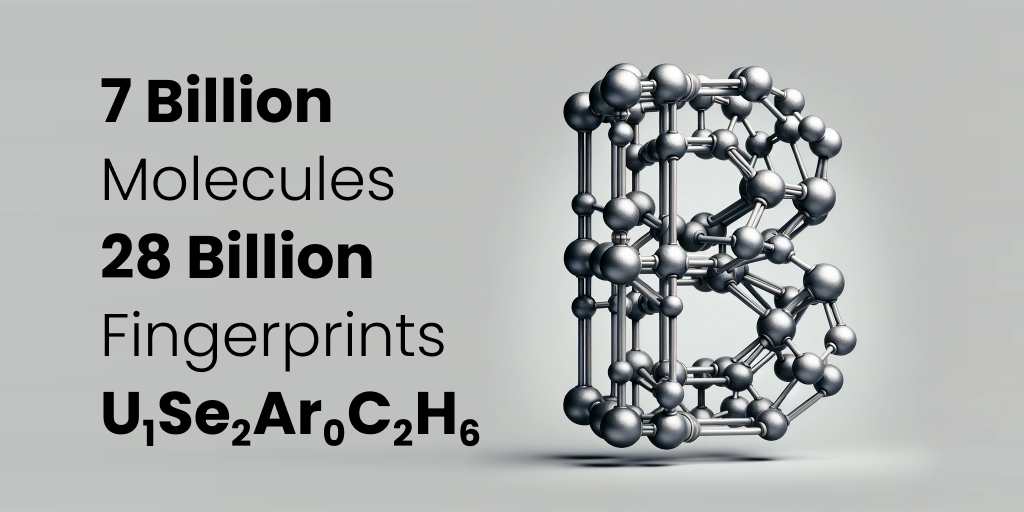
TLDR: I’ve finally finished a project that involved gathering 7 billion small molecules, each represented in SMILES notation and having fewer than 50 “heavy” non-hydrogen atoms. Those molecules were “fingerprinted”, producing 28 billion structural embeddings, using MACCS, PubChem, ECFP4, and FCFP4 techniques. These embeddings were indexed using Unum’s open-source tool USearch, to accelerate molecule search. This extensive dataset is now made available globally for free, thanks to ...| ashvardanian.com

When our Python code is too slow, like most others we switch to C and often get 100x speed boosts, just like when we replaced SciPy distance computations with SimSIMD. But imagine going 100x faster than C code! It sounds crazy, especially for number-crunching tasks that are “data-parallel” and easy for compilers to optimize. In such spots the compiler will typically “unroll” the loop, vectorize the code, and use SIMD instructions to process multiple data elements in parallel.| ashvardanian.com

You’ve probably heard about AI a lot this year. Lately, there’s been talk about something called Retrieval Augmented Generation (RAG). Unlike a regular chat with ChatGPT, RAG lets ChatGPT search through a database for helpful information. This makes the conversation better and the answers more on point. Usually, a Vector Search engine is used as the database. It’s good at finding similar data points in a big pile of data. These data points are often at least 256-dimensional, meaning the...| ashvardanian.com

Python’s not the fastest language out there. Developers often use tools like Boost.Python and SWIG to wrap faster native C/C++ code for Python. PyBind11 is the most popular tool for the job not the quickest. NanoBind offers improvements, but when speed really matters, we turn to pure CPython C API bindings. With StringZilla, I started with PyBind11 but switched to CPython to reduce latency. The switch did demand more coding effort, moving from modern C++17 to more basic C99, but the result ...| ashvardanian.com
