1. Executive Summary Our customer, a global telecommunications leader, established a Data Platform team to transform how data improved customer experiences and business operations. Faced with ballooning data growth and legacy storage constraints, they replaced aging legacy data storage systems with a high-performance, cloud-native data lakehouse, built on MinIO’| MinIO Blog
Unleash data collaboration and quality with Nessie! Learn to manage branches, commits, and merges effortlessly. This guide walks you through deploying Dremio, MinIO, and Nessie, transforming your data engineering with collaborative precision. Dive in to revolutionize your workflows!| MinIO Blog
Discover the power of Apache Iceberg and AIStor in transforming data lakehouses! From multi-engine compatibility to time travel, schema evolution, and blazing-fast performance, this guide dives deep into how Iceberg unlocks the full potential of modern AI and analytics workloads.| MinIO Blog
File formats rarely get the spotlight. They sit under layers of query engines, orchestration tools, and machine learning frameworks, quietly doing the heavy lifting. Yet, the way we store and access data has a direct impact on everything from query latency to model accuracy. And right now, the file format space is undergoing one of […] The post Exploring the Evolving File Format Landscape in AI Era: Parquet, Lance, Nimble and Vortex And What It Means for Apache Iceberg appeared first on Dre...| Dremio
The data world is moving fast. AI agents are no longer science fiction; they’re showing up in workflows, automating tasks, generating insights, and acting on behalf of users. But for these agents to be effective, they need more than just good models. They need consistent, fast, and governed access to enterprise data. That’s where Dremio’s […] The post A Guide to Dremio’s Agentic AI, Apache Iceberg and Lakehouse Content appeared first on Dremio.| Dremio
Apache Iceberg provides a powerful foundation for managing large analytical datasets, but like any data system, performance depends heavily on how well the data is organized on disk. Over time, frequent writes, schema evolution, and streaming ingestion can leave tables fragmented with many small files or oversized files that hurt query speed. Left unmanaged, this […] The post Apache Iceberg Table Performance Management with Dremio’s OPTIMIZE appeared first on Dremio.| Dremio
Managing Apache Iceberg tables effectively is often a balancing act between write performance, storage efficiency, and query speed. While Iceberg’s flexibility enables powerful features like time travel and schema evolution, many teams find themselves running frequent OPTIMIZE jobs to compact small files and rebalance partitions. These jobs improve performance but also consume valuable compute resources, […] The post Minimizing Iceberg Table Management with Smart Writing appeared first on...| Dremio
Apache Iceberg’s snapshot-based architecture is one of its greatest strengths, enabling time travel queries, rollbacks, and strong auditability. But with every update, new snapshots are created and old data files linger. Over time, this leads to growing storage costs, expanding metadata, and, perhaps most importantly, questions around regulatory compliance. How do you ensure that data […] The post Apache Iceberg Table Storage Management with Dremio’s VACUUM TABLE appeared first on Dremio.| Dremio
AIStor Tables brings Iceberg catalogs natively into on-prem object storage. It simplifies data organization, enforces table-aware security, and lets AI teams catalog unstructured assets in structured tables, thereby enabling discovery.| MinIO Blog
The format war is over, and Iceberg won. Every major engine now supports it, from Snowflake to Spark. Built for object stores, Iceberg delivers scale, consistency, and simplicity. It is the unified foundation for enterprise AI and analytics. Future-proof your data with Iceberg.| MinIO Blog
Apache Iceberg 1.9.0 closes the gap with Delta Lake, adding row-level ops with lineage, JSON-friendly variant type, geospatial support, REST catalog upgrades, and easier Delta migration. Dropping Hadoop 2 and Spark 3.3 signals a modern focus, driving open table format convergence.| MinIO Blog
The data lake was once heralded as the future, an infinitely scalable reservoir for all our raw data, promising to transform it into actionable insights. This was a logical progression from databases and data warehouses, each step driven by the increasing demand for scalability. Yet, in embracing the data lake's| MinIO Blog
Apache Iceberg is significantly transforming modern data lakes. Its introduction to object storage platforms has been celebrated for delivering ACID transactions, strong schema evolution, and warehouse-like reliability to data lake architectures. The Iceberg Catalog API standard is crucial to this transformation, as it ensures that various tools can consistently discover| MinIO Blog
In data engineering, open standards are foundational for building interoperable, evolvable, and non-proprietary systems. Apache Iceberg, an open table format, is a prime example. Along with compute, Iceberg brings structure and reliability to data lakes. When coupled with high-performance object storage like MinIO AIStor, Iceberg unlocks new avenues for creating| MinIO Blog
Amazon S3 Tables was launched on December 3rd 2024, and provides you “storage that is optimized for tabular data such as daily purchase transactions, streaming sensor data, and ad impressions in Apache Iceberg format”. While S3 Tables can be queried ...| tobilg.com
DuckDB has gained a new feature in preview, that allows querying of Iceberg data in AWS S3 Tables. Setting up a S3 Table There are multiple steps which need to be performed to set up a S3 Table that can be then queried with tools like DuckDB. As the ...| tobilg.com
Apache Iceberg has significantly reshaped how organizations manage and interact with massive structured analytical datasets inside object storage. It brings database-like reliability and powerful features such as ACID transactions, schema evolution, and time travel. Although these features are commonly emphasized, the Iceberg Catalog API is what makes these tables accessible.| MinIO Blog
Cloud lakehouses break the bank at scale and compromise control. On-prem Iceberg lakehouses deliver speed, savings, and sovereignty. From cancer research to finance, real-world deployments prove it: petabyte-scale performance, full control, and lower TCO are within reach.| MinIO Blog
Choosing the right open table format—Apache Iceberg, Delta Lake, or Apache Hudi—can make or break your data lakehouse. This guide breaks down their strengths, how they integrate with object storage, and which one is best for AI, analytics, and real-time workloads.| MinIO Blog
Last week marked an Apache Iceberg milestone with the 1st Iceberg Summit. It was an astounding success for a first-time event. Here are some of the key stats from the Summit, plus the most popular talks. The top talks in terms of attendance were The 45 minute sessions that engaged people with the most were: […]| Tabular
Streaming ingestion into Apache Iceberg tables is an exciting topic that brings the worlds of real-time and batch closer together. But it’s important also to think about what we do with the data after it’s ingested. In a recent post, I talked about streaming change data capture (CDC) data into a mirror table in Iceberg using […]| Tabular
A Tabular newsletter revisiting last month in Iceberg ❤️Apache Iceberg? Spread the word by giving it a ⭐ on the apache/iceberg repo! Iceberg Summit – May 14-15, a virtual conference Announcing the first Iceberg Summit, organized by Tabular and Dremio, and sanctioned by the Apache Software Foundation. The event will include dozens of technical talks […]| Tabular
Addressing data duplication and scaling issues in graph databases Authors: Brian Olsen, Danfeng Xu, Jason Reid, and Weimo Liu TL;DR Graph databases are limited in their scalability and interoperability when they rely on specialized storage systems. This post challenges the necessity of graph native storage systems, and proposes an alternative solution that leverages the physical […]| Tabular
A Tabular newsletter revisiting the last month in Apache Iceberg ❤️Apache Iceberg? Spread the word by giving it a ⭐ on the apache/iceberg repo! Project updates Iceberg Java PyIceberg, iceberg-go, and iceberg-rust Iceberg Summit 2024 Apache Software Foundation and Apache Iceberg PMC have agreed to allow Tabular and Dremio to jointly organize the first Iceberg […]| Tabular
Tabular and Dremio have received approval from the Apache Iceberg PMC to organize the inaugural Iceberg Summit, a free-to-attend virtual event to be held May 14 – 15, 2024. Iceberg Summit is an Apache Software Foundation (ASF) sanctioned event. Those wishing to attend can register here. Your information will only be used for event communications […]| Tabular
With the new 0.6.0 PyIceberg release, write support has been added. This blog post will highlight the new features. Write to Apache Iceberg from Python This blog gives an introduction to the Python API to write an Iceberg table, looking at how this is different from writing just Parquet files, and what’s next. PyIceberg writes […]| Tabular
A Tabular newsletter revisiting the last month in Apache Iceberg ❤️Apache Iceberg? Spread the word by giving it a ⭐ on the apache/iceberg repo! Project updates Iceberg Java PyIceberg, iceberg-go, and iceberg-rust Bergy Blogs Ecosystem Updates Vendor Updates Iceberg Resources 🏁 Get Started with Apache Iceberg. 🧑🍳Get cookin’ with recipes from the Apache Iceberg Cookbook. […]| Tabular
An event-driven architecture is an extremely popular use case for streaming data. Using events produced and consumed asynchronously is a great way to allow microservices to communicate with each other while keeping them decoupled. However, the events that power these business applications contain data that can provide even more business value downstream in a data […]| Tabular
❤️ Apache Iceberg? Spread the word by giving it a ⭐ on the apache/iceberg repo! Project updates Iceberg Java Bergy Blogs Ecosystem Updates Vendor Updates Iceberg Resources 🏁 Get Started with Apache Iceberg👩🏫 Learn more about Apache Iceberg on the official Apache site📺 Watch and subscribe to the Iceberg YouTube Channel📰 Read up on some community blog posts🫴🏾 Contribute to Iceberg👥 SELECT * FROM you […]| Tabular
New support for writing to Apache Polaris-managed Apache Iceberg tables enables Datavolo customers to stream transformed data from nearly any source system into Iceberg. Originally created by Snowflake, Polaris allows customers to use any query engine to access the data wherever it lives. These engines leverage Polaris via the REST interface. In addition to the […] The post Streaming Data to Iceberg From Any Source appeared first on Datavolo.| Datavolo
With Dremio and Apache Iceberg, managing partitioning and optimizing queries becomes far simpler and more effective. By leveraging Reflections, Incremental Reflections, and Live Reflections, you can maintain fresh data, reduce the complexity of partitioning strategies, and optimize for different query plans without sacrificing performance. Using Dremio’s flexible approach, you can balance keeping raw tables simple and ensuring that frequently run queries are fully optimized.| Dremio
Maintaining an Apache Iceberg Lakehouse involves strategic optimization and vigilant governance across its core components—storage, data files, table formats, catalogs, and compute engines. Key tasks like partitioning, compaction, and clustering enhance performance, while regular maintenance such as expiring snapshots and removing orphan files helps manage storage and ensures compliance. Effective catalog management, whether through open-source or managed solutions like Dremio's Enterprise ...| Dremio
Migrating to an Apache Iceberg Lakehouse enhances data infrastructure with cost-efficiency, ease of use, and business value, despite the inherent challenges. By adopting a data lakehouse architecture, you gain benefits like ACID guarantees, time travel, and schema evolution, with Apache Iceberg offering unique advantages. Selecting the right catalog and choosing between in-place or shadow migration approaches, supported by a blue/green strategy, ensures a smooth transition. Tools like Dremio ...| Dremio
In previous blogs, we've discussed understanding Polaris's architecture and getting hands-on with Polaris self-managed OSS; in this article, I hope to show you how to get hands-on with the Snowflake Managed version of Polaris, which is currently in public preview.| Dremio
Explore a comparative analysis of Apache Iceberg and other data lakehouse solutions. Discover unique features and benefits to make an informed choice.| Dremio
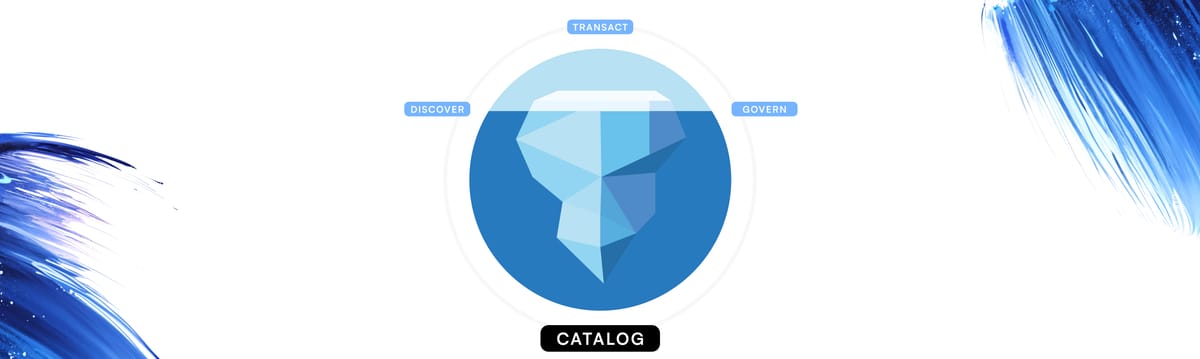
Dremio is the only company offering an hybrid enterprise Iceberg lakehouse that provides seamless self-service analytics, directly connecting users to their data. Dremio’s Universal Semantic Layer transforms data into a business-friendly format, enabling easy discovery and analysis.| Dremio
Databricks' acquisition of Tabular, founded by the creators of Apache Iceberg, underscores the importance of open frameworks in modern data lake design. Open frameworks ensure interoperability, flexibility, and simplicity, benefiting those leveraging data for AI.| MinIO Blog
Dremio's approach removes primary roadblocks to virtualization at scale while maintaining all the governance, agility, and integration benefits.| Dremio