
The 5 Stages of Monitoring: From 'Firefighting' to 'Fire Prevention'
From 'Is it up?' to 'We see everything' – 5 monitoring stages to save your sanity (and $50K in outages). Start small, win big!| Kalvad
Ryan is joined by Spiros Xanthos, CEO and founder of Resolve AI, to talk about the future of AI agents in incident management and troubleshooting, the challenges of maintaining complex software systems with traditional runbooks, and the changing role of developers in an AI-driven world.| Stack Overflow Blog
From 'Is it up?' to 'We see everything' – 5 monitoring stages to save your sanity (and $50K in outages). Start small, win big!| Kalvad
Michael Blum| mblum.me 🥝

こんにちは。NewsPicksのWeb Reader Experience Unitで学生インターンをしている西(@yukinissie)です。 昨年の 9 月までSREチームに所属しており、その頃にNewsPicksの全ての常駐バッチサーバーをAWS CDKを用いてAWS FargateとAWS Fragate Spotを併用するようにさせましましたのでコストの変化や工夫した点についてご紹介します。 AWS Fargate Spotとは? 実際どれくらいのコストを削減できたか 0...| Uzabase for Engineers

こんにちは。SREチームの吉澤です。最近、SRE NEXTドリブンでSREとSWEでタッグを組んでインフラコスト削減した話を書きました。まだの方はぜひ読んでみてください。 アンドパッドは、7/11(金)〜12(土)開催のSRE NEXT 2025にCOFFEEスポンサーとして協賛しました! 今回はアンドパッドブースの様子と、現地参加したメンバーによるおすすめセッションをご紹介します。アーカイ...| ANDPAD Tech Blog

こんにちは。SREチームの吉澤です。 SREはインフラの専門性を持つため、SREチームのミッションに「インフラコスト削減」も含まれている会社は多いと思います。アンドパッドでも、主にSREチームがインフラコスト削減に取り組んできました。しかし、この取り組みだけでは削減できないコストが見えてきました。 そこでアンドパッドでは、2024年6月から、SREとソフトウ...| ANDPAD Tech Blog

こんにちは。SREチームの吉澤です。先日のSRE KaigiではFindyさんのSRE Quizを全問正解してTシャツをもらってしまい、完全に勘で答えたので気まずくなったりしてました。 1/26(日)開催のSRE Kaigi 2025にて、アンドパッドCREチームの杉本さん、島根さんが「SREじゃなくてもできる!インシデント対応で鍛えたCREチームの5年史」というタイトルで発表しました!SREチームの私と角...| ANDPAD Tech Blog
在同一家公司工作两年以上,有很大概率会 burn out(意思就是精疲力尽,俺不中了)。如果岗位又是 SRE, […] Continue reading...| 卡瓦邦噶!
Deep dive into the IAM failure that took down Google Cloud, cascaded into Cloudflare and Anthropic, and rippled across dozens of internet services.| Forge Code Blog

Queues are everywhere, and they follow mathematical rules. Learn a few of those rules! It’ll go a long way to making you a stronger SRE.| Dan Slimmon

ブレインパッドのSRE(Site Reliability Engineering)チームは、パーソナライズ・プラットフォーム「Rtoaster(アールトースター)」などのデータ活用プロダクトをお客様が安心して利用できるよう、サービスの安定稼働と信頼性の確保に取り組んでいます。普段は明かされないプロダクト運用の舞台裏、SREチームが大切にしている視点など、同チームで活躍する井上さん、内...| Platinum Data Blog by BrainPad ブレインパッド
How DevOps is Revolutionizing Patient Care, Compliance, and Innovation in the Healthcare Sector Introduction: The Healthcare Industry at a Turning Point The global healthcare sector is undergoing an unprecedented digital transformation. Driven by the need for better patient outcomes, operational efficiency, regulatory compliance, and resilience in the face of events like pandemics, healthcare organizations are […]| ITGix
Guide to connecting your Nest app with Jagear via OpenTelemetry| Sagyam's Blog
it would take 12 years of uninterrupted service to be able to take a 1 hour outage and still be at five nines.| constructolution
People have asked me, “Are we doing DevOps, or are we doing SRE?” I’ve also heard (and this is worse): “We’re an SRE team – we don’t do DevOps.” These distinctions don’t make sense, because SRE and DevOps aren’t actually different things. SRE is DevOps. To be more precise, SRE is a specific implementation of […]| constructolution

I recently had the pleasure of reading anthropologist David Graeber’s 2018 book, Bullshit Jobs: A Theory. Graeber defines a bullshit job as, a form of paid employment that is so completely po…| Dan Slimmon
Thundering herds, noisy neighbours, retry storms.| Mads Hartmann
I had the pleasure of contributing an article to the Reliability issue of Increment magazine. The article is titled Tracing a path to observability and chronicles our efforts at Glitch to gain visibility into our production systems and eventually make them more reliable. Give it a read and let me know what you think.| Mads Hartmann
At Glitch we’ve recently completed a project to migrate to SLO-based alerts. It’s too early to tell if this has been a success or not, but in this post I’ll write about our motivation for going down this route, and give an introduction to all the concepts you need to know, should you want to give it a go as well. SLOs are useful for a lot of things. As you’ll see below, we’re hoping that by implementing SLOs - and alerting on them - we’ll be able to improve communication during in...| Mads Hartmann
As part of an upcoming episode of Shift Shift Forward I answered a few questions about incident response. The description of the episode is:| Mads Hartmann
Recently Charity Majors asked a few hypothetical questions (tweet) around what you’d want out of a book on observability. I saw this as excellent opportunity to throw a bunch of questions I’ve been struggling with at an observability expert - so here are my questions ☺️| Mads Hartmann
As I have alluded to in the other parts of this little series of posts we’ve been investing in observability tools at Glitch to help us keep the platform reliable, even as more and more people run their apps on Glitch. In this post, I’ll focus on why we started investing in observability tools, where we are now and how we got there, and finally what we still haven’t figured out.| Mads Hartmann
At Glitch we have been investing in observability tools to help us keep the platform reliable, even as more and more people run their apps on Glitch. In the previous post in this series I highlighted some of the best observability resources I’ve come across so far. In this post I’ll focus on telemetry.| Mads Hartmann
I’ve been reading up on observability over the last three months. In this post I have organized the material into a sort of recommended reading order. It doesn’t reflect the order in which I read it, but I think this order would’ve made more sense.| Mads Hartmann
Queues are not just architectural widgets that you can insert into your architecture wherever they're needed. Queues are spontaneously occurring phenomena, just like a waterfall or a thunderstorm.| Dan Slimmon
I was recently delighted to be interviewed by Adam Hawkins on his podcast Small Batches. We discussed a huge variety of topics. Here is the full episode, and on that page you’ll find meticulously timestamped links to specific topics. Check out the rest of Adam’s podcast, it’s phenomenal!| Dan Slimmon
We often don't realize how noisy the errors have gotten until things are already well out of hand. After all, we've got shit to do. Deadlines to hit. By the time we decide to get serious about error management, a huge, impenetrable, meaningless backlog of errors has already accumulated. I call this stuff "slag."| Dan Slimmon
Last month, I had the unadulterated pleasure of presenting “No Observability Without Theory” at Monitorama 2024. If you’ve never been to Monitorama, I can’t recommend it enough. I think it’s the best tech conference, period. This talk was adapted from an old blog post of mine, but it was a blast turning it into a … Continue reading No Observability Without Theory: The Talk| Dan Slimmon
If you’re a junior engineer at a software company, you might be required to be on call for the systems your team owns. Which means you’ll eventually be called upon to lead an incident response. And since incidents don’t care what your org chart looks like, fate may place you in charge of your seniors; … Continue reading Leading incidents when you’re junior| Dan Slimmon
It only takes a few off-the-rails incidents in your software career to realize the importance of writing things down. That’s why so many companies’ incident response protocols define a scribe role. The scribe’s job, generally, is to take notes on everything that happens. In other words, the scribe produces an artifact of the response effort. … Continue reading Fight understanding decay with a rich Incident Summary| Dan Slimmon

Avoiding the trap of Application-centric SLI to capture actual user satisfaction Introduction In today’s digital world, ensuring a seamless user experience is paramount. Organizations striving to deliver reliable services often grapple with the challenge of finding the right balance between introducing new features and improving reliability and performance. Enter| Michelin IT Engineering Blog

こんにちは。SREチームリーダーの角井です。 アンドパッドは、8/3(土)〜4(日)に開催されたSRE NEXT 2024にゴールドスポンサーとして協賛し、企業ブースとスポンサーLTに参加させていただきました! スポンサーLTでは、私から「アンドパッドのマルチプロダクト戦略を支えるSRE」というタイトルで発表させていただきました。発表後にはAsk the Speakerの時間があり、それに加...| ANDPAD Tech Blog

Linting provides a cheap feedback loop, requires little setup, and can capture risky patterns. See which linter we chose and why.| Honeycomb

こんにちは!クラウド基盤本部、PDX(Platform Developer eXperience)所属の@BkNkbotです。昨日から、CYBOZU SUMMER BLOG FES '24でクラウド基盤本部の所属メンバーが記事を執筆する「クラウド基盤本部Stage」が始まっています! というわけで、最初の3日間は私から「インタビュー記事」をお届けします(今日はその2日目です)。協力していただいたメンバー・その方のチーム紹介を兼...| Cybozu Inside Out | サイボウズエンジニアのブログ

こんにちは!クラウド基盤本部、PDX(Platform Developer eXperience)所属の@BkNkbotです。今日から最終日の8/20(火)まで、CYBOZU SUMMER BLOG FES '24でクラウド基盤本部Stageが始まり、毎日クラウド基盤本部のメンバーが記事を執筆します。 ……というわけで、最初の3日間は私から「インタビュー記事」をお届けします。協力していただいたメンバー・その方のチーム紹介を兼ねている...| Cybozu Inside Out | サイボウズエンジニアのブログ
Our technical blog.| source.coveo.com

Over the years, I’ve developed a reliable method for harnessing the diagnostic power of groups. My approach is derived from a different field in which groups of experts with various levels of…| Dan Slimmon
Presentation on the need to re-examine how we engineer systems (taking service providers as an example) and the implications on how we quantify cyber risk if we want to take this message into the board room (as given at BT’s SnoopCon 2019 and Cisco’s June 2019 Knowledge Network webinar for service providers). Having delivered security […] The post Security Engineering – A manifesto for defensive security appeared first on Portcullis Labs.| Portcullis Labs
Whilst there are some great examples of how to assess infrastructure as code dynamically with things like the Center for Internet Security‘s Docker benchmark and CoreOS‘s Clair, these kinda run a little too late in the pipeline for my liking. If we want to treat infrastructure as code then surely we ought to be performing […] The post Use Infrastructure as Code they said. Easier to audit they said… (part 1) appeared first on Portcullis Labs.| Portcullis Labs
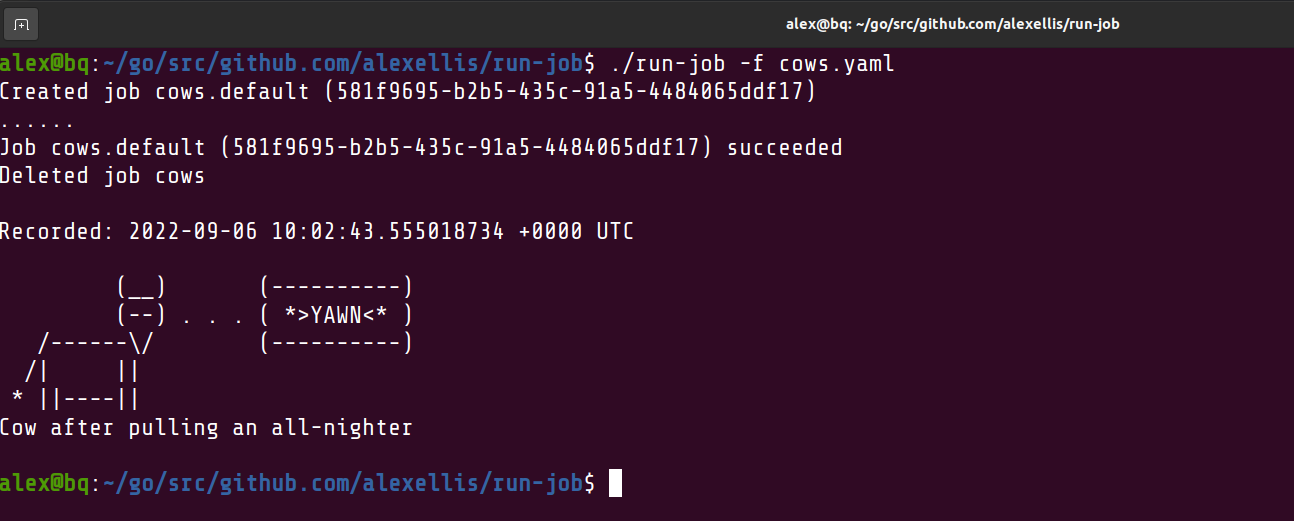
I wanted to run a container for a customer only once, but the UX just wasn't simple enough. So I created a new utility with Golang and the Kubernetes API| Alex Ellis' Blog
The 2022 Void Report came out in late 2022, It is a recommended read, and I previously summarized it here. This article focuses on one aspect of the report: why mean time to recover (MTTR) is not an appropriate metric for complex software systems.| Shaun Abram
