The version 2.10.0 of GPU Shark II, a monitoring and information utility for graphics cards, has been released with Raspberry Pi 5, OpenCL and CUDA support. The post GPU Shark 2.10 GPU Monitoring and Information Utility Released first appeared on Geeks3D.| Geeks3D
Coastal communities in the U.S. have a 26% chance of flooding within a 30-year period. This percentage is expected to increase due to climate-change-driven sea-level rise, making these areas even more vulnerable. Michael Beck, professor and director of the UC Santa Cruz Center for Coastal Climate Resilience, focuses on modeling and mapping the benefits of Read Article| NVIDIA Blog
The parallel processing of accelerated computing offers the power needed to make the quantum computing breakthroughs of today and tomorrow possible.| NVIDIA Blog
F5 has announced its intent to acquire enterprise AI security company CalypsoAI, whose award-winning platform brings real-time threat defense, red teaming at scale, and data security to enterprises racing to deploy generative and agentic AI.| ITOps Times
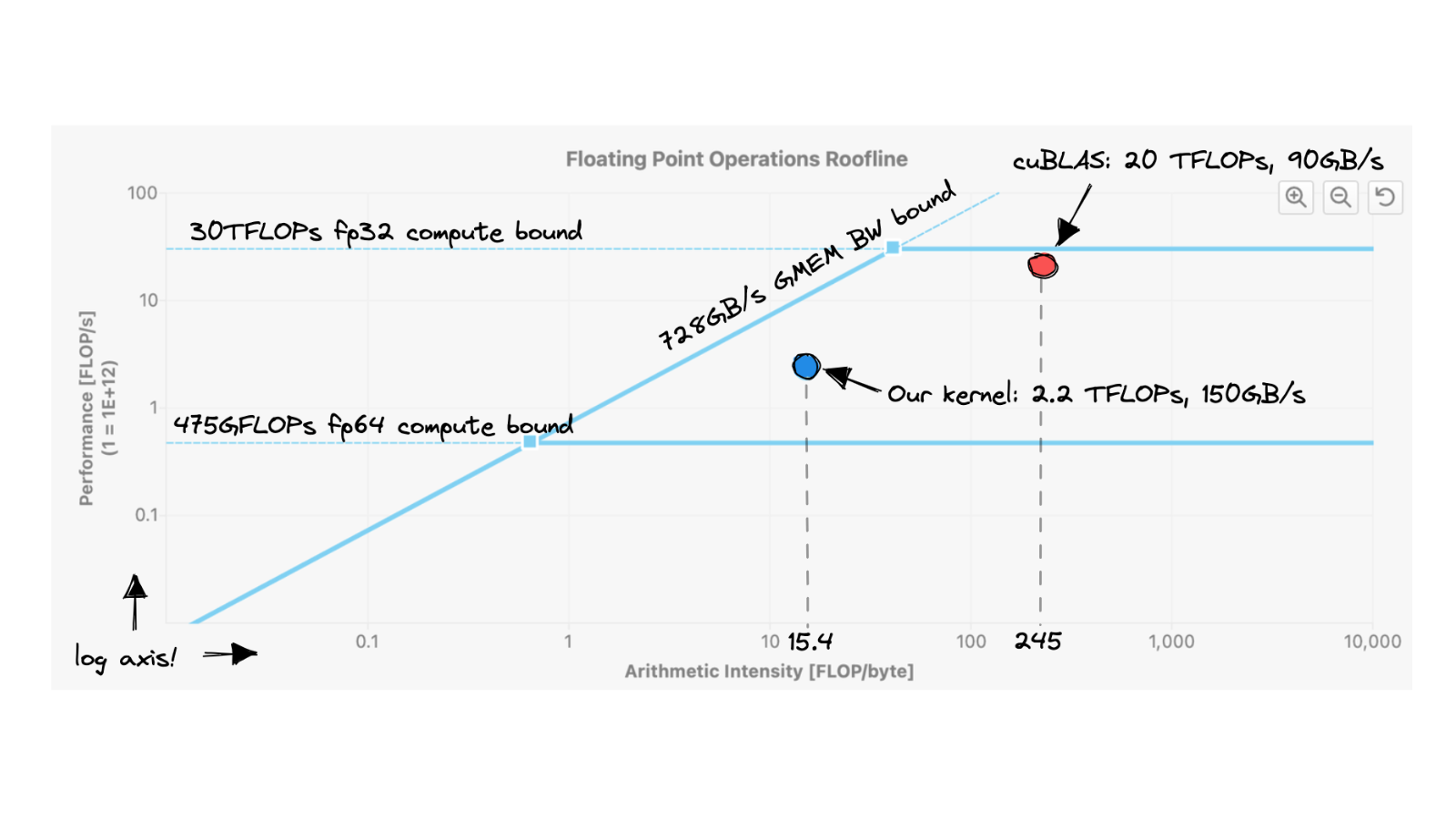
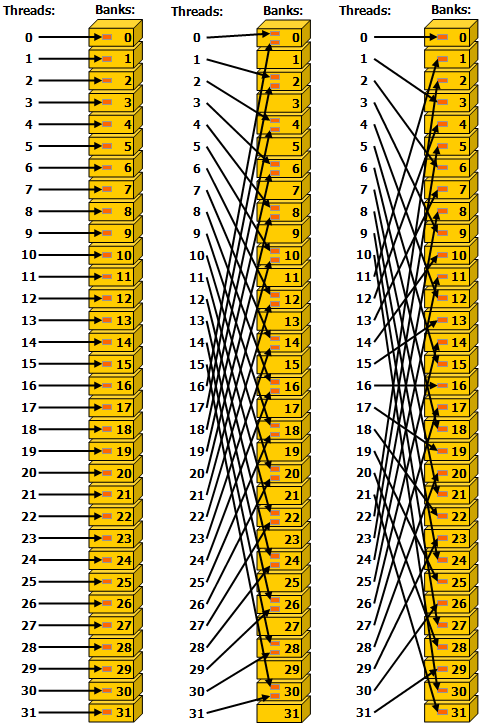
In this post, I’ll iteratively optimize an implementation of matrix multiplication written in CUDA.My goal is not to build a cuBLAS replacement, but to deepl...| siboehm.com
Posted by the TensorFlow teamTensorFlow 2.18 has been released! Highlights of this release (and 2.17) include NumPy 2.0, LiteRT repository, CUDA Update, Hermetic CUDA and more. For the full release notes, please click here.| The TensorFlow Blog
Posted by the TensorFlow teamTensorFlow 2.17 has been released! Highlights of this release (and 2.16) include CUDA update, upcoming Numpy 2.0, and more. For the full release notes, please click here.| The TensorFlow Blog
I am somehow very late to learning CUDA. I didn’t even know until recently that CUDA is just C++ with a small amount of extra stuff. If I had known that there is so little friction to learning it, I would have checked it out much earlier. But if you come in with C++ habits, […]| Probably Dance
We're excited to announce the reboot of the Rust CUDA project. Rust CUDA enables you to write and run CUDA kernels in Rust, executing directly on NVIDIA GPUs using NVVM IR.| rust-gpu.github.io
Unification of Memory on the Grace Hopper Nodes The delivery of new GPUs for research is continuing, most notable is the newIsambard-AI cluster atBristol. As new cutting-edge GPUs are released, software engineers aretasked with being made aware of the new architectures and features these newGPUs offer. The new Grace-Hopper GH200 nodes, as announced in a previous blogpost, consist of a 72-core NVIDIA Grace CPU and anH100 Tensor Core GPU. One of the key innovations is the NVIDIA NVLinkChip-2-Ch...| QMUL ITS Research Blog
NAMD is a molecular dynamics program that can use GPU acceleration to speed up its calculations. Recent OpenPOWER machines like the IBM Power Systems S822LC for High Performance Computing (Minsky) come with a new interconnect for GPUs called NVLink, which offers extremely high bandwidth to a number of very powerful Nvidia Pascal P100 GPUs. So they're ideal machines for this sort of workload.| sthbrx.github.io
Our previous blogs (Taichi & PyTorch 01 and 02) pointed out that Taichi and Torch serve different application scenarios can they complement each other? And the answer is an unequivocal yes! In this blog, we will use two simple examples to explain how to use Taichi kernel to implement data preprocessing operators or custom ML operators. With Taichi, you can accelerate your ML model development with ease and get rid of the tedious low-level parallel programming (CUDA for example) for good.| docs.taichi-lang.org