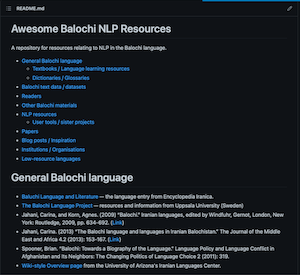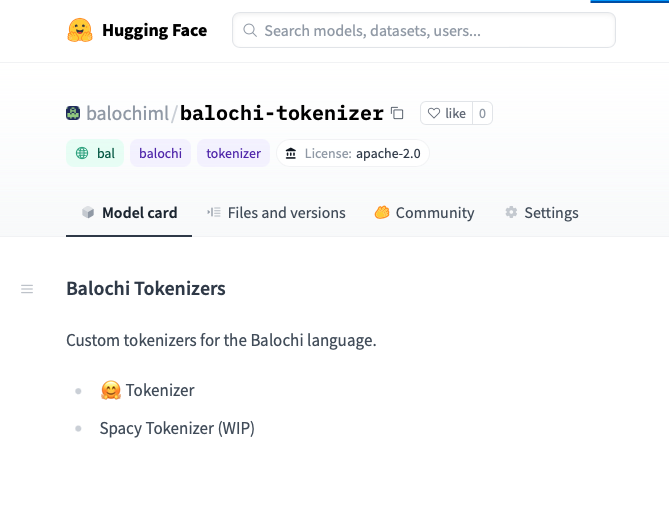
Alex Strick van Linschoten - Tokenizing Balochi with HuggingFace’s Tokenizer and FastAI/Spacy
I explore language tokenization using FastAI, Spacy, and Huggingface Tokenizers, with a special focus on the less-represented Balochi language.| mlops.systems