
Selecting The Right AI Evals Tool – Hamel’s Blog
An example of how to assess AI eval tools like Langsmith, Braintrust, and Arize Phoenix.| Hamel's Blog
An example of how to assess AI eval tools like Langsmith, Braintrust, and Arize Phoenix.| Hamel's Blog
My life is not a math Olympiad| Graham King
Hello friends. This blog post was supposed to be the second part of this re| evilsocket
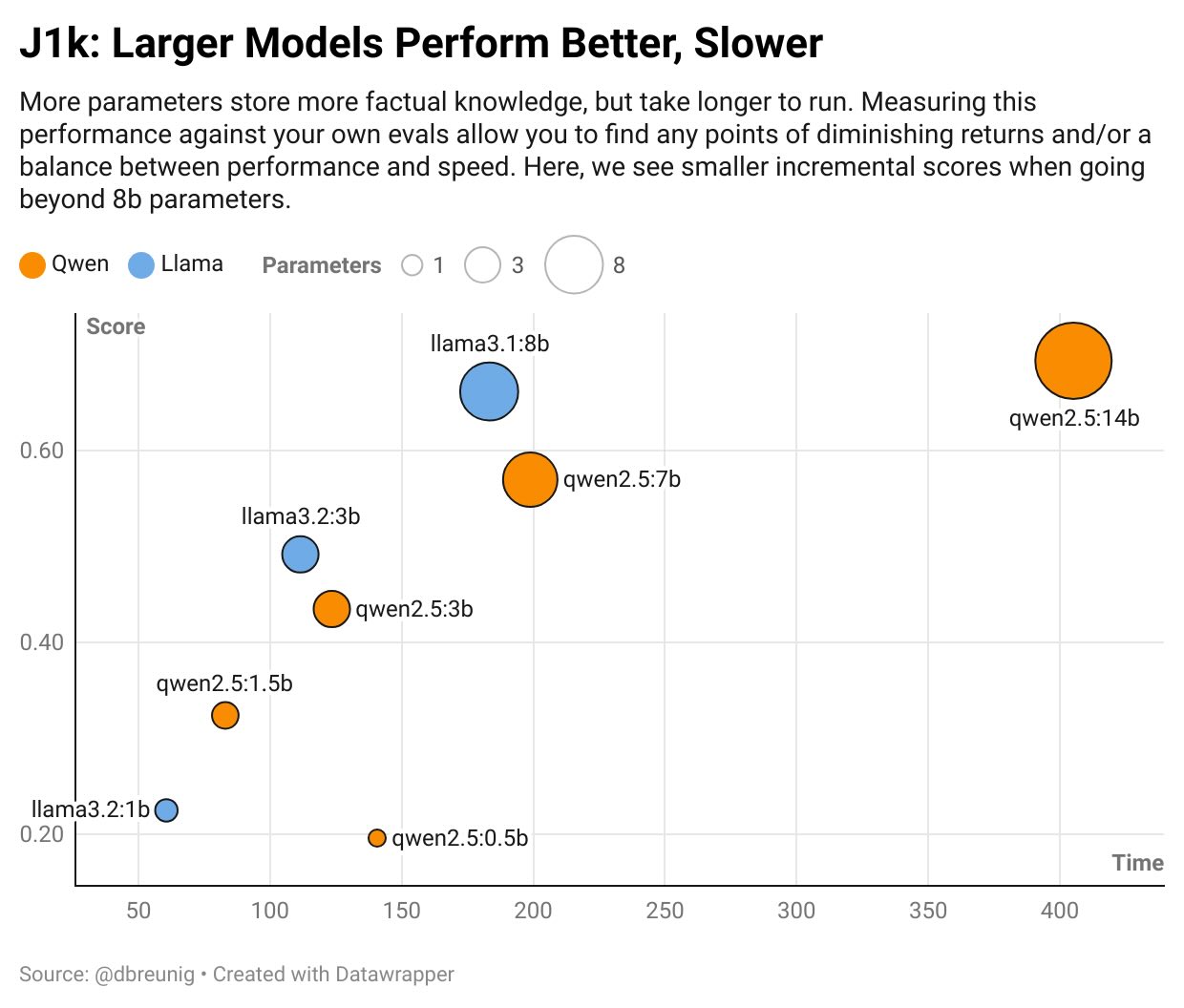
A well-built custom eval lets you quickly test the newest models, iterate faster when developing prompts and pipelines, and ensure you’re always moving forward against your product’s specific goal. Let’s build an example eval – made from Jeopardy questions – to illustrate the value of a custom eval.| Drew Breunig
Earlier this year, I wrote Your AI product needs evals. Many of you asked, “How do I get started with LLM-as-a-judge?” This guide shares what I’ve learned after helping over 30 companies set up their evaluation systems. The Problem: AI Teams Are Drowning in Data Ever spend weeks building an AI system, only to realize you have no idea if it’s actually working? You’re not alone. I’ve noticed teams repeat the same mistakes when using LLMs to evaluate AI outputs: Too Many Metrics: Cre...| Hamel's Blog

