
Serverless Inference with Together AI
Together AI serverless inference for text generation, image generation, and vision language models along with Gradio chat application.| DebuggerCafe
In this article, we create a multimodal Gradio application with Together AI models for chatting LLMs & VLMs, generating images, and automatic speech transcription using OpenAI Whisper models. The post Multimodal Gradio App with Together AI appeared first on DebuggerCafe.| DebuggerCafe
Together AI serverless inference for text generation, image generation, and vision language models along with Gradio chat application.| DebuggerCafe

Qwen2.5-VL is the newest member in the Qwen Vision Language family, capable of image captioning, video captioning, and object detection.| DebuggerCafe
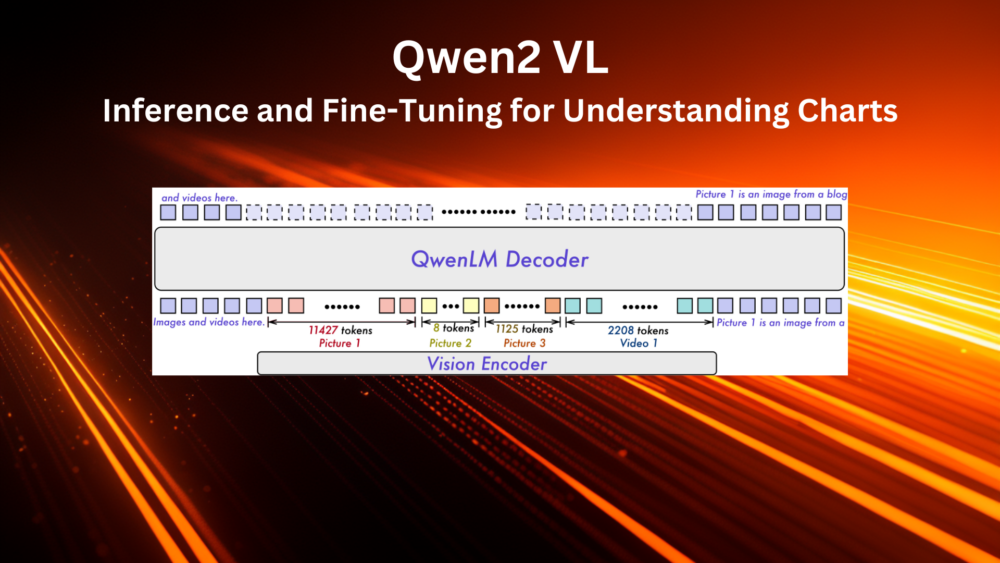
Qwen2 VL is a Vision Language model with the Qwen2 Language Decoder and Vision Transformer model from DFN as the image encoder.| DebuggerCafe

Fine-tuning Llama 3.2 Vision on a LaTeX2OCR dataset to predict raw LaTeX equations from images and creating a Gradio application.| DebuggerCafe

Llama 3.2 Vision model is a multimodal VLM from Meta belonging to the Llama 3 family that brings the capability to feed images to the model.| DebuggerCafe
