
Launch: Use Florence-2 in Roboflow Workflows
Learn how to use Florence-2 in Roboflow Workflows for zero-shot object detection, OCR, and more.| Roboflow Blog
Learn how to use Florence-2 in Roboflow Workflows for zero-shot object detection, OCR, and more.| Roboflow Blog

The Multimodal 2022 fair was held at the NEC from 14-16 June. Multimodal is the largest trade fair in the TFL industry in the United Kingdom.| ShipHub

Explore six tips on how to effectively use YOLO-World to identify objects in images.| Roboflow Blog
In this comprehensive tutorial, discover how to speed up your image annotation process using Grounding DINO and Segment Anything Model. Learn how to convert object detection datasets into instance segmentation datasets, and use these models to automatically annotate your images.| Roboflow Blog
Viele Aktivitäten der menschlichen Kultur hinterlassen keine Spuren, andere landen in Archiven in Form von Daten. Diese Archivdaten durchlaufen zwangsweise Selektion und Strukturierung, was beeinflusst, welche Informationen wir über die Vergangenheit erhalten und wie wir sie wahrnehmen. Dieser Prozess wiederholt sich heutzutage, während Archive digitalisiert werden. Dabei kann ein Teil der Daten verloren gehen. Gleichzeitig ermöglicht die Restrukturierung und Neusystematisierung, neue Erk...| Digital Humanities Cologne
Objective EchoPrime is a foundation model designed for comprehensive echocardiographic interpretation. Unlike previous models that use single views or static...| vitalab.github.io

Explore alternatives to GPT-4 Vision with Large Multimodal Models such as Qwen-VL and CogVLM, and fine-tuned detection models.| Roboflow Blog

In this guide, we share our first impressions testing LLaVA-1.5.| Roboflow Blog
The past three years have seen significant interest in applying language models to the task of visual document understanding – integrating spatial, textual, and visual signals to make sense of PDFs and scanned documents.| machine learning musings

Comparing multimodal agents and how they struggle on ‘The Password Game’| jerpint
As 2024 comes to a close, the development of Retrieval-Augmented Generation (RAG) has been nothing short of turbulent. Let's take a comprehensive look back at the year's progress from various perspectives.| RAGFlow Blog
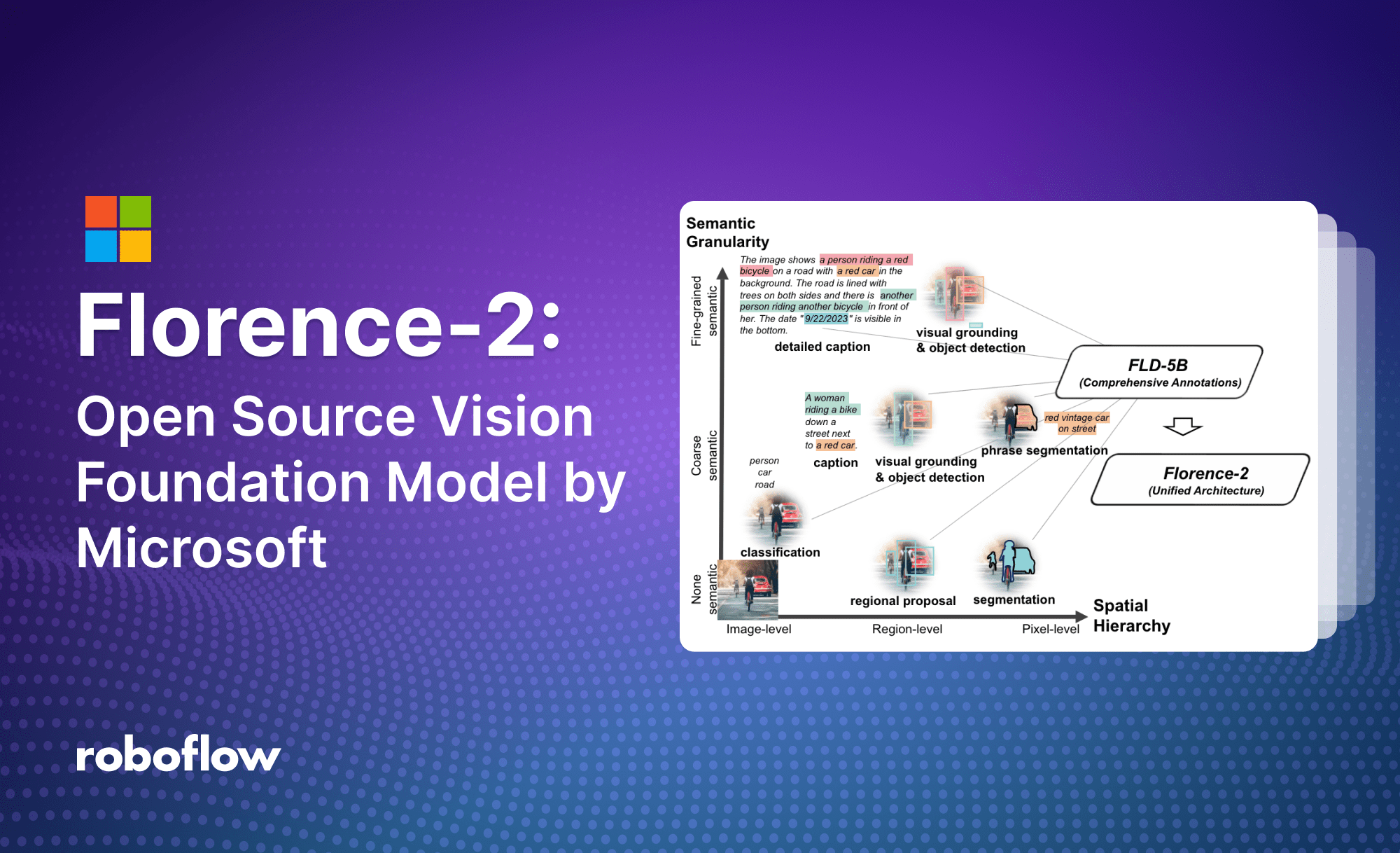
Florence-2 is a lightweight vision-language model open-sourced by Microsoft under the MIT license.| Roboflow Blog

Learn what GPT-4o is, how it differs from previous models, evaluate its performance, and use cases for GPT-4o.| Roboflow Blog

See how nine different OCR models compare for scene text recognition across industrial domains.| Roboflow Blog
To make the most of being a Multimodal learner, you need to understand what each of your preferred modalities means, what your VARK preferences are, and how to best use your VARK preferences in learning situations.| VARK - helping you learn better

Road diets remove lanes to improve safety, cut emissions, and calm traffic. See real road diet examples and the data behind their success.| StreetLight

Cities can gain many benefits from multimodal transportation, which encompasses all types of transport, from cars and buses to bikes and pedestrian traffic.| StreetLight
In this guide, we evaluate Google's Gemini LMM against several computer vision tasks, from OCR to VQA to zero-shot object detection.| Roboflow Blog

In this guide, we share findings experimenting with GPT-4 with Vision, released by OpenAI in September 2023.| Roboflow Blog
