Things have changed a lot in the last year related to LLMs and AI; on the one hand, it seems the AI skeptics for coding are increasingly confined to the corners of the internet. Everyone is dancing around in the middle, not sure of where everything should fall. Clearly, if we don’t use AI at […] The post Running Llama 3.1 8B Locally (LangChain and SQLite) appeared first on Confessions of a Data Guy.| Confessions of a Data Guy
So, the classic newbie question. DuckDB vs Polars, which one should you pick? This is an interesting question, and actually drives a lot of search traffic to this website on which you find yourself wasting time. I thank you for that. This is probably the most classic type of question that all developers eventually ask […] The post DuckDB vs Polars. Wait. DuckDB and Polars. appeared first on Confessions of a Data Guy.| Confessions of a Data Guy
Data teams often find themselves balancing business needs against budget constraints and limited headcount, not to mention the increasing pressures to catch up with ever-changing technologies. If you have a three-person data team that maintains hundreds of tables & serves thousands of reports for internal and external stakeholders, the challenge multiplies with a tech stack […] The post Data platform migration beyond the tech stack: Patties Food Group appeared first on Infinite Lambda.| Infinite Lambda
Data protection crucial when you are handling your clients' personally identifiable information (PII). Building a robust strategy to protect PII can sometimes prove challenging, as you need to strike a balance between very specific requirements and technical considerations. In this article, we will show you how to implement tag-based masking in Snowflake using stored procedures, […] The post Tag-Based Masking in Snowflake Using Stored Procedures appeared first on Infinite Lambda.| Infinite Lambda
Is your data team constantly feeling the pressure to deliver? Do members of your team say they feel like they’re doing work meant for two people? If the answer to either or both of these questions is a resounding yes, you may feel tempted to think, “We just need more hands on deck.” However, hiring… Read more| Seattle Data Guy
Well, all the bottom feeders (Iceberg and DuckDB users) are howling at the moon and dancing around a bonfire at midnight trying to cast their evil spells on the rest of us. Apache Iceberg writes with DuckDB? Better late than never I suppose. Not going to lie, Iceberg writes with MotherDuck is an interesting concept. […] The post Apache Iceberg Writes with DuckDB (or not) appeared first on Confessions of a Data Guy.| Confessions of a Data Guy
So, you’re just a regular old Data Engineer crawling along through the data muck, barley keeping your head above the bits and bytes threatening to drown you. At point in time you were full of spit and vinegar and enjoyed understanding and playing with every nuance known to man. But, not you are old and […] The post How to tune Spark Shuffle Partitions. appeared first on Confessions of a Data Guy.| Confessions of a Data Guy
Ok, not going to lie, I rarely find anything of value in the dregs of r/dataengineering, mostly I fear, because it’s %90 freshers with little to no experience. These green behind the ear know-it-all engineers who’ve never written a line of Perl, SSH’d into a server, and have no idea what a LAMP stack is. […]| Confessions of a Data Guy
Distributed systems often struggle with data consistency. In this post, I explore how the Transactional Outbox pattern helped us solve this challenge in a client project, and how it compares to CDC and Event Sourcing.| Scott Logic
Unlock e-commerce profits with dynamic pricing on Databricks. Learn how AI-driven strategies give you a competitive edge. The post Why Dynamic Pricing is Powerful for E-Commerce? first appeared on Techwards.| Techwards
Unlock precise retail inventory control with AI. Fine-grained demand forecasting reduces stockouts, cuts waste & boosts profits. Learn how! The post Stop Stockouts: Master AI Retail Forecasting Now first appeared on Techwards.| Techwards
Lakehouse Architecture unifies data lakes and warehouses, enabling retailers to process real-time data, personalize experiences, and optimize supply chains—all from one platform. The post Gain a Retail Edge: How Lakehouse Architecture Deliver Unprecedented Insights first appeared on Techwards.| Techwards
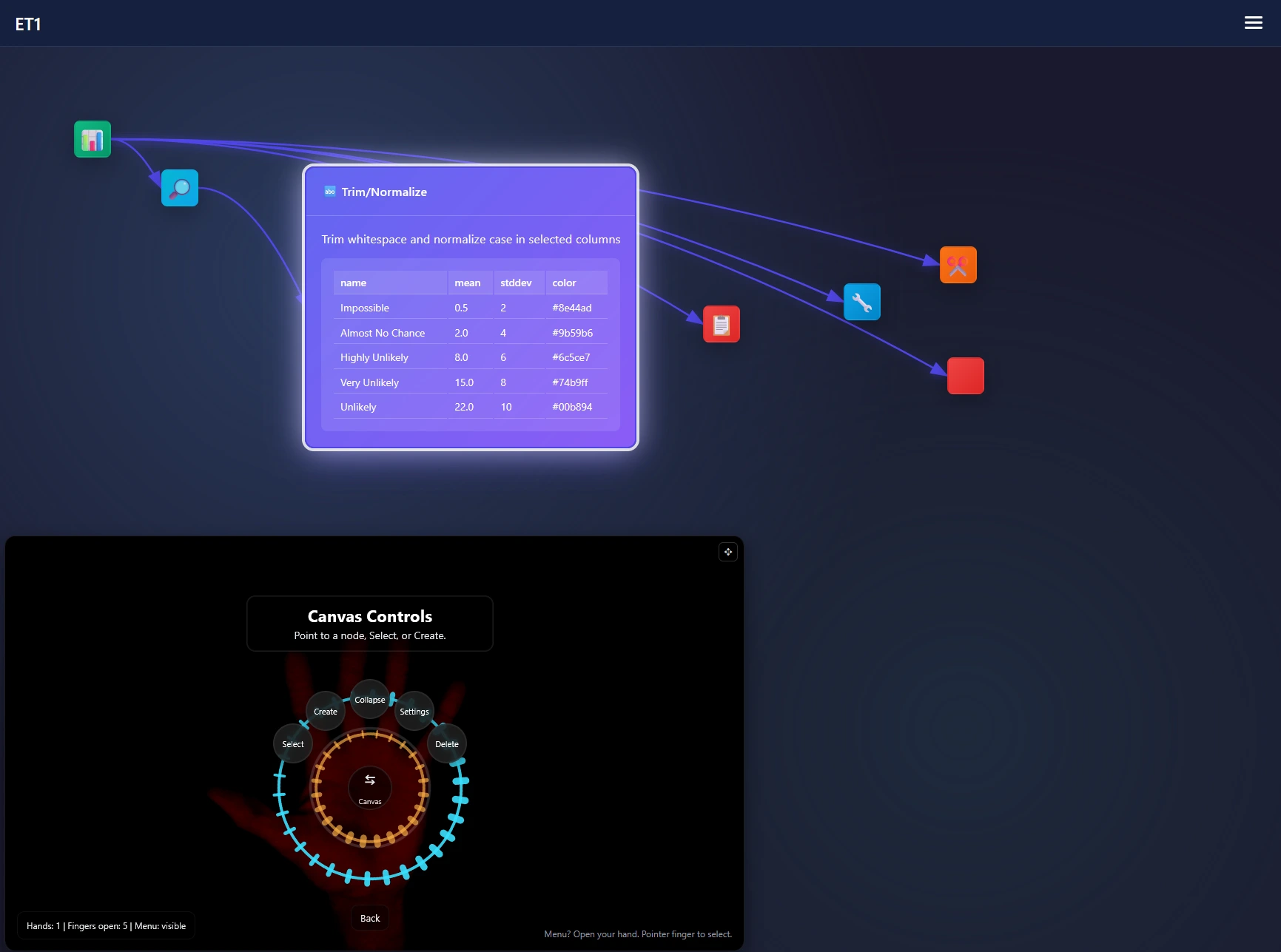
If a web-cam is available ET1’s code will try to automatically sync and if you can wave and point, this radial menu is a fun way to augment your ETL development. Using computer vision (explained in depth below) we map a skeleton over your hands and able to create a radial menu we are calling […]| Dev3lop
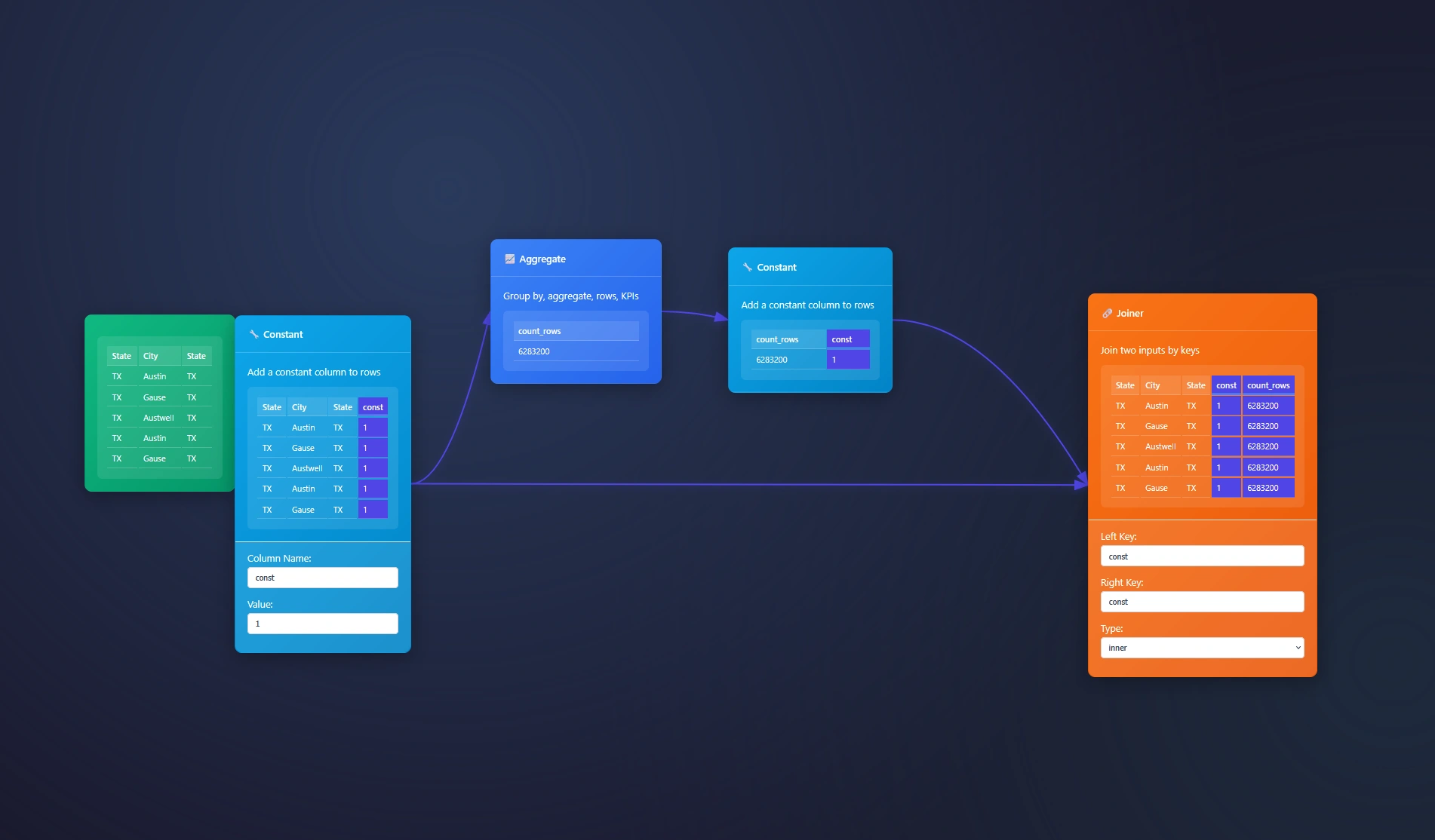
Seeking to append fields like the Alteryx Desktop software? The Joiner Node and Aggregate node is here to help. You will also need a constant to join on across both data streams. We will show you how in this example below where we are sent 6million records in a CSV and asked to append the […]| Dev3lop
Dealing with duplicate columns? This particular node is designed to remove similarly named column headers. If “State”=”State” then we remove the last column and only keep the first column. “Remove duplicate columns based on similar header names” Currently there are no settings for this tool because today Duplicate Columns Node solves problems without requiring a […]| Dev3lop
Aggregation, what a classic. Aggregating your data is a landmark trait for any data steward, data wrangler, or data analyst. In ET1, you can easily aggregate your data. The Power of Grouping (Group By) with the Aggregate Node Aggregations turn a sea of numbers into meaningful insights. Group by in ET1 is nested in the […]| Dev3lop
Are you combining the data? We have you covered. ET1 has all the right tools. The Three Musketeers of Data Combination 1. 🤝 Join (The Matchmaker) 2. 🔗 Union (The Stacker) 3. 🧵 Concat ([bring], [it], [together],[with],”glue”) Concat merges everything, and it doesn’t care about data types. Real-World Examples Join: Union: Concat: Pro Tips No […]| Dev3lop
The filtering nodes help you reduce the number of rows, drill into the exact information needed, and create a data set that will add value VS confuse your audience. When filtering, remember you’re reducing the amount of data coming through the node, or you can swap to include. Include, exclude, and ultimately work on your […]| Dev3lop
Posted by Jason Jabbour, Kai Kleinbard and Vijay Janapa Reddi (Harvard University)Everyone wants to do the modeling work, but no one wants to do the engineering.| The TensorFlow Blog
Did you know that Polars, that Rust based DataFrame tool that is one the fastest tools on the market today, just got faster?? There is now GPU execution on available on Polars that makes it 70% faster than before!!| Confessions of a Data Guy
I don’t know about you, but I grew up and cut my teeth in what feels like a special and Golden age of software engineering that is now relegated to the history books, a true onetime Renaissance of coding that was beautiful, bright, full of laughter and wonder, a time which has passed and will […]| Confessions of a Data Guy
Learn what data compliance is, its benefits, essential tools, and key metrics to protect sensitive information and meet regulations.| Git for Data - lakeFS
SQLMesh is an open-source framework for managing, versioning, and orchestrating SQL-based data transformations. It’s in the same “data transformation” space as dbt, but with some important design and workflow differences. What SQLMesh Is SQLMesh is a next-generation data transformation framework designed to ship data quickly, efficiently, and without error. Data teams can efficiently run and […]| Confessions of a Data Guy
The data lake was once heralded as the future, an infinitely scalable reservoir for all our raw data, promising to transform it into actionable insights. This was a logical progression from databases and data warehouses, each step driven by the increasing demand for scalability. Yet, in embracing the data lake's| MinIO Blog
Learn 5 key considerations for building a scalable, cost-effective GCP data lake. Optimize performance, storage, and analytics on Google Cloud.| HatchWorks AI
Learn Databricks best practices for 2025 to optimize performance, reduce costs, and manage production data efficiently with actionable tips.| HatchWorks AI
Predicting purchase intent is a common e-commerce use case. See how to set up the solution with Snowpark Container Services (SPCS) and Snowflake Registry to leverage real-time ML inference efficiently.| Infinite Lambda
So … Astronomer.io … who are they and what do they do? It’s funny how, every once in a while, the Data Engineering world gets dragged into the light of the real world … usually for bad things … and then gets shoved under the carpet again. Recently, because of the transgressions of the CEO […]| Confessions of a Data Guy
Explore how Homes England built a secure data platform to improve data quality and empower better, faster decision making across the organisation.| dataingovernment.blog.gov.uk
Data integration is critical for organizations of all sizes and industries—and one of the leading providers of data integration tools is Talend, which offers the flagship product Talend Studio. In 2023, Talend was acquired by Qlik, combining the two companies’ data integration and analytics tools under one roof. In January 2024, Talend discontinued Talend Open… Read more The post Alternatives to Talend – How To Migrate Away From Talend For Your Data Pipelines appeared first on Seattle...| Seattle Data Guy
Discover data virtualization, its benefits, real-world use cases, architecture and top tools for integrating, managing, and accessing data in real time.| lakeFS
Data enables faster and more accurate due diligence, informs operational transformation post-acquisition, and supports more effective positioning when it comes time to exit. This post outlines the role of data across each of these key stages.| Scott Logic
Find out how lakeFS complements MLOps tools serving as the data infrastructure layer. Compare MLflow, Neptune, Quilt and DataChain.| Git for Data - lakeFS
Discover what data discovery is, how it works, its benefits, challenges, and best practices to turn raw data into strategic, actionable insights.| Careers at lakeFS: Help Close the Data Infrastructure Gap
The SAP and Databricks partnership and the introduction of SAP Business Data Cloud. Jan van Ansem from Snap Analytics explains what it means for customers. The post The SAP Databricks partnership: Combining expert knowledge of business critical processes with world-class data engineering capabilities appeared first on Snap Analytics.| Snap Analytics
The first five posts of these series were largely conceptual discussions that sprinkled in some SQL and data models here and there where helpful. This final post will serve as a summary of those posts, but it will also specifically include SQL queries, data models and transformation logic related to the overall discussion that should […] The post Tied With A Bow: Wrapping Up the Hierarchy Discussion (Part 6 of 6) appeared first on Snap Analytics.| Snap Analytics
In the first three posts of this series, we delved into some necessary details from graph theory, reviewed acyclic graphs (DAGs), and touched on some foundational concepts that help describe what hierarchies are and how they might best be modeled. In the fourth post of the series, we spent time considering an alternative model for […] The post Edge Cases: Handling Ragged and Unbalanced Hierarchies (Part 5 of 6) appeared first on Snap Analytics.| Snap Analytics
In the first post of this series, we walked through the basic concepts of a graph. In the second post, we discussed a particular kind of graph called a directed acyclic graph (DAG) and helped disambiguate and extend the roles it plays in data engineering. In the third post, we further constrained the definition of […] The post Flat Out: Introducing Level Hierarchies (4 of 6) appeared first on Snap Analytics.| Snap Analytics
Explore 5 defining trends in the annual State of Data and AI Engineering 2025 report. Uncover what changed and what's trending this year.| Git for Data - lakeFS
Discover what an AI factory is, how it works, and how companies use it to turn raw data into scalable, automated, and intelligent business solutions.| Git for Data - lakeFS
Maybe you’re luckier than me. Maybe you’ve never opened a .sql file or an Airflow DAG only to be greeted by a 5,000+ line query…a true monster of a script that leaves you wondering where to begin. I’ve seen plenty of these, and every time, I ask myself: Why in the world do these exist? And, more… Read more| Seattle Data Guy
The use of the Algorithmic Transparency Recording Standard (ATRS) became mandatory for central government in 2024. Read about how the GDS Data and AI ethics team have rolled out the mandate across government and how they have updated the ATRS to reflect learnings from this process.| dataingovernment.blog.gov.uk
We compare MCP vs workflow automation vs LLM-specific function calling in enterprise contexts to offer insights into performance and accuracy. Visit the Infinite Lambda Blog.| Infinite Lambda
We are benchmarking the impact of PostgreSQL Triggers on performance. Find the analysis and key takeaways on the Infinite Lambda blog.| Infinite Lambda
After working in data for over a decade, one thing that remains the same is the need to create data pipelines. Whether you call them ETLs/ELTs or something else, companies need to move and process data for analytics. The question becomes how companies are actually building their data pipelines. What ETL tools are they actually… Read more| Seattle Data Guy
Over the past three years our teams have noticed a pattern. Many companies looking to migrate to the cloud go from SQL Server to Snowflake. There are many reasons this makes sense. One of the reasons and common benefits was that teams found it far easier to manage that SQL Server and in almost every… Read more| Seattle Data Guy
Every so often, I have to convert some .txt or .csv file over to Excel format … just because that’s how the business wants to consume or share the data. It is what it is. This means I am often on the lookup for some easy to use, simple, one-liners that I can use to […]| Confessions of a Data Guy
Learn how to build a solid AI infrastructure for efficiently developing and deploying AI and machine learning (ML) applications. Read more.| Git for Data - lakeFS
If you work in data, then you’ve likely used BigQuery and you’ve likely used it without really thinking about how it operates under the hood. On the surface BigQuery is Google Cloud’s fully-managed, serverless data warehouse. It’s the Redshift of GCP except we like it a little more. The question becomes, how does it work?… Read more| Seattle Data Guy
Planning out your data infrastructure in 2025 can feel wildly different than it did even five years ago. The ecosystem is louder, flashier, and more fragmented. Everyone is talking about AI, chatbots, LLMs, vector databases, and whether your data stack is “AI-ready.” Vendors promise magic, just plug in their tool and watch your insights appear.… Read more| Seattle Data Guy
Our analytics team plays a vital role in maintaining high-quality data that drives everything from key reports to experiments aimed at improving our products. Ensuring data reliability is critical, and to achieve this, we’ve built a robust SQL testing library for Athena. A strong data foundation isn’t just about accuracy—it’s about reliability. That’s why testing... Read more| Engineering Blog - Wealthfront
Since I started working in tech, one goal that kept coming up was workflow automation. Whether automating a report or setting up retraining pipelines for machine learning models, the idea was always the same: do less manual work and get more consistent results. But automation isn’t just for analytics. RevOps teams want to streamline processes… Read more| Seattle Data Guy
Running dbt on Databricks has never been easier. The integration between dbtcore and Databricks could not be more simple to set up and run. Wondering how to approach running dbt models on Databricks with SparkSQL? Watch the tutorial below.| Confessions of a Data Guy
There are things in life that are satisfying—like a clean DAG run, a freshly brewed cup of coffee, or finally deleting 400 lines of YAML. Then there are things that make you question your life choices. Enter: setting up Apache Polaris (incubating) as an Apache Iceberg REST catalog. Let’s get one thing out of the […]| Confessions of a Data Guy
Context and Motivation dbt (Data Build Tool): A popular open-source framework that organizes SQL transformations in a modular, version-controlled, and testable way. Databricks: A platform that unifies data engineering and data science pipelines, typically with Spark (PySpark, Scala) or SparkSQL. The post explores whether a Databricks environment—often used for Lakehouse architectures—benefits from dbt, especially if […]| Confessions of a Data Guy
Discover how Grab revolutionised its Spark observability with StarRocks! We transformed our monitoring capabilities by moving from a fragmented system to a unified, high-performance platform. Learn about our journey from the initial Iris tool to a robust solution that tackles limitations with real-time and historical data analysis, all powered by StarRocks. Explore the architecture, data model, and advanced analytics that enable us to provide deeper insights and recommendations for optimising...| Grab Tech
Improve your ETL workflows with Databricks and Delta Lake. Learn how to optimize data processing for faster, more reliable, and scalable pipelines with ACID compliance, schema evolution, and real-time data ingestion.| Indium
What’s going on in the world of data validation? For those of you who don’t know, data validation is the process of checking data quality in an automated or semi-automated way—for example, checking datatypes, checking the number of missing values, and detecting whether there are anomalous numbers. It doesn’t have to be rows in a dataframe though, it could be for validating API input or form submissions. The user provides rules for what should be flagged as an issue, for example saying...| Arthur Turrell
Modern AI & BI workloads take more analytical power than traditional transactional EDAs offer. To meet the demands of real-time analytics, comprehensive cloud data warehouses and real-time data platforms can complement each other.| Infinite Lambda
Learn about A/B testing an ML-powered learn-to-rank (LTR) algorithm we developed to enable personalisation for travel leader Secret Escapes.| Infinite Lambda
Discover the top secrets to smarter fraud detection in BFSI with real-time data visualization tools that drive proactive, data-driven responses to financial fraud.| Indium
PDF files are one of the most popular file formats today. Because they can preserve the visual layout of documents and are compatible with a wide range of devices and operating systems, PDFs are used for everything from business forms and educational material to creative designs. However, PDF files also present multiple challenges when it… Read more| Seattle Data Guy
Rewriting code on a legacy platform is like rearranging deck chairs on the Titanic. This article delves into legacy debt and shows you how to go about solving it the right way.| Infinite Lambda
If you’re looking to pass hundreds of GBs of data quickly, you’re likely not going to use a REST API. That’s why every day, companies share data sets of users, patient claims, financial transactions, and more via SFTP. If you’ve been in the industry for a while, you’ve probably come across automated SFTP jobs that… Read more| Seattle Data Guy
The cloud is cheaper to run than on-premises, but only if you get the migration right. This article on the Infinite Lambda Blog explains exactly how to do that.| Infinite Lambda
Scraping data from PDFs is a right of passage if you work in data. Someone somewhere always needs help getting invoices parsed, contracts read through, or dozens of other use cases. Most of us will turn to Python and our trusty list of Python libraries and start plugging away. Of course, there are many challenges… Read more| Seattle Data Guy
You did it! You finally led the charge and persuaded your boss to let your team start working on a new generative AI application at work and you’re psyched to get started. You get your data and start the ingestion process but right when you think you’ve nailed it, you get your first results and […] The post Data Ingestion Strategies for GenAI Pipelines appeared first on Datavolo.| Datavolo
Matillion Shared Jobs help making ETL solutions consistent, easy to support and cheaper to manage. Here are the key benefits explained.| Snap Analytics
Digging into new AI models is one of the most exciting parts of my job here at Datavolo. However, having a new toy to play with can easily be overshadowed by the large assortment of issues that come up when you’re moving your code from your laptop to a production environment. Similar to adding a […] The post Onward with ONNX® – How We Did It appeared first on Datavolo.| Datavolo
Explore how Tecton's declarative framework streamlines ML feature engineering from development to production, reducing complexity and infrastructure costs.| Tecton
Learn how Tecton solves hidden data engineering challenges in ML, from pipeline building to ensuring data consistency, to accelerate AI development.| Tecton
Learn how to get started with data lake implementation. Explore the essentials to enhance your data management strategies.| Careers at lakeFS: Help Close the Data Infrastructure Gap
Unlock your potential with leading top data engineering certifications. Learn about the certification details, benefits, and how to get started in detail.| Whizlabs Blog
The data diff validation approach comes in handy during a blue-green deployment when we need to address discrepancies. Learn how to do that effectively.| Infinite Lambda
40% of all business initiatives fail to achieve their targeted benefits as a result of poor data quality, yet few are investing in measuring their data quality.| Show Me The Data
With rapid advancements in tech, robust data protection practices and full compliance with regulations, such as GDPR, are a must. Let's see how.| Infinite Lambda
Data masking is essential for data protection and compliance with regulations. Let's see how to use data contracts to automate it in your Snowflake database.| Infinite Lambda
Find out how Databricks Autoloader can help you create a scalable, reliable, and stable data intake pipeline. Read on to learn more.| Git for Data - lakeFS
Database object management automation: let's look at the essential aspects, the business benefits, technological advantages and the implementation basics.| Infinite Lambda
If you’re a data engineer, then you’ve likely at least heard of Airflow. Apache Airflow is one of the most popular open-source workflow orchestration solutions that gets used for data pipelines. This is what spurred me to write the article “Should You Use Airflow” because there are plenty of people who don’t enjoy Airflow or… Read more| Seattle Data Guy
This article dives into Databricks: what it is, how it works, its core features and architecture, and how to get started. Read more| Git for Data - lakeFS
After a previous rant, I started toying with the idea of writing software to solve this issue1. The goal is to fully control and use personal health data and I develop this for myself first. Luckily there are a lot of projects and people out there to take inspiration from.| hillman.dev
Photo by Leif Christoph Gottwald on Unsplash A few months ago, I uploaded a video where I discussed data warehouses, data lakes, and transactional databases. However, the world of data management is evolving rapidly, especially with the resurgence of AI and machine learning. There are numerous other methods that technical teams are utilizing to handle… Read more| Seattle Data Guy