Picture a world where your most sensitive data files and database tables are protected with the same robust security protocols and layers you’d expect from a leading, Fortune 500 corporation. Without having to setup data security; login, authorization, storage, persistence, managing login information and keeping data compliance people happy. In ET1.1, we encourage end users […] The post Login to ET1.1 with Auth2 appeared first on Dev3lop.| Dev3lop
The Neon Input Node is our first managed database access node, and an intuitive approach to giving people access to a serverless PostgreSQL which users are able to manage in Neon Lake. Data here is safe, and protected by 0Auth (Two way authentication). As you use ET1.1 csv files, json, and manual tables, this data […]| Dev3lop
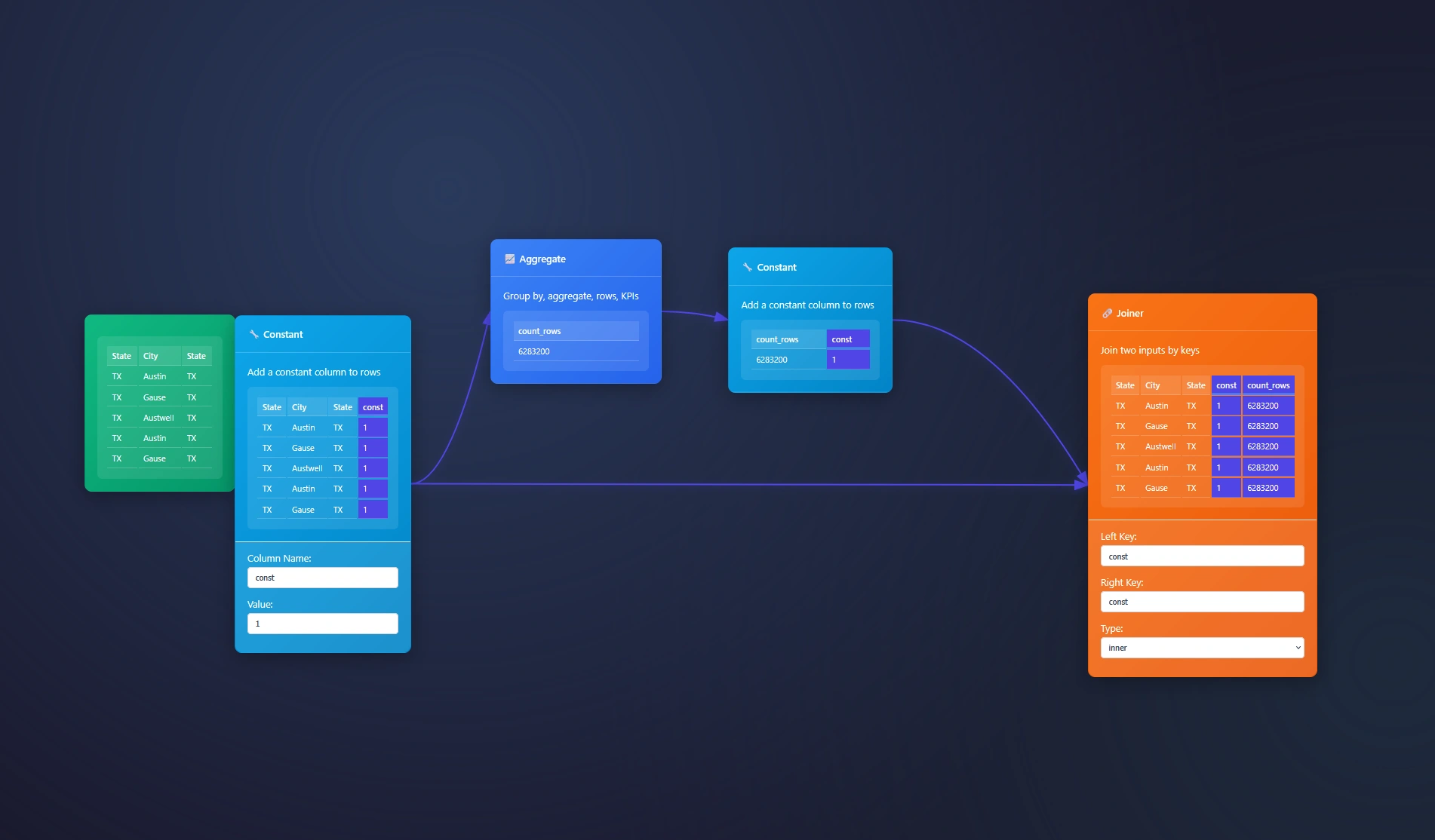
The Constant Node creates a constant value per row in your data pipeline. This node is extremely handy when transforming data in your ETL processes. The Constant Node is rather straight forward, two inputs and you’re done. Using the Constant Node Add the Constant Node to your canvas, send data downstream to your node and […] The post ET1s Constant Node appeared first on Dev3lop.| Dev3lop
Bring your columns together as one with the Concat Node in ET1. This node is similar to concat() in Excel and allows you to easily bring more than 1 column together in your data pipeline, and also it gives you the ability to add the delimiter. The opposite of the Concat Node is the Split […] The post ET1’s Concat Node appeared first on Dev3lop.| Dev3lop
Automatically finding and replacing data is possible using the Find/Replace Node! Find and replace works inside of sentences, words, numbers, and anywhere in the data. Similar to “find all” and “replace all,” in your common Word Document software, ET1 offers the same but in a repeatable and consistent data app. Using Find/Replace Node Finding data […] The post ET1’s Find/Replace Node appeared first on Dev3lop.| Dev3lop
Create a table manually using the Manual Table Node. Manual Table node falls under the data input node category. Built to help you create small tables that you need to use in your data pipelines. When you need a thin layer of data, this is a great tool for manually synthesizing your data which happens […] The post ET1 Manual Table Node appeared first on Dev3lop.| Dev3lop
ET1’s Github CSV Node is designed to help end users extract data from Github CSV URLs which are in public repositories. A public repository on Github is not a place to put your private or company information. However City/State for USA is a commonly used resource in Map Data related solutions. Unlike the CSV Input […] The post ET1’s Github CSV Node appeared first on Dev3lop.| Dev3lop
The CSV Input Node, what a classic, flat files living on your computer can be consumed and the data can be extracted here in ET1. CSV is a common file type for data gurus. Comma-Separated Values, a plain text file format for storing tabular data with values separated by commas. If you have a CSV […]| Dev3lop
When extracting data from a JSON file, try the JSON Input Node. JSON (JavaScript Object Notation) is a common data source. With ET1’s JSON Input Node you can quickly open your JSON files and begin to transform the data, merge it with other data like CSV data. In ET1, data is normalized in a data […] The post ET1’s JSON Input Node appeared first on Dev3lop.| Dev3lop
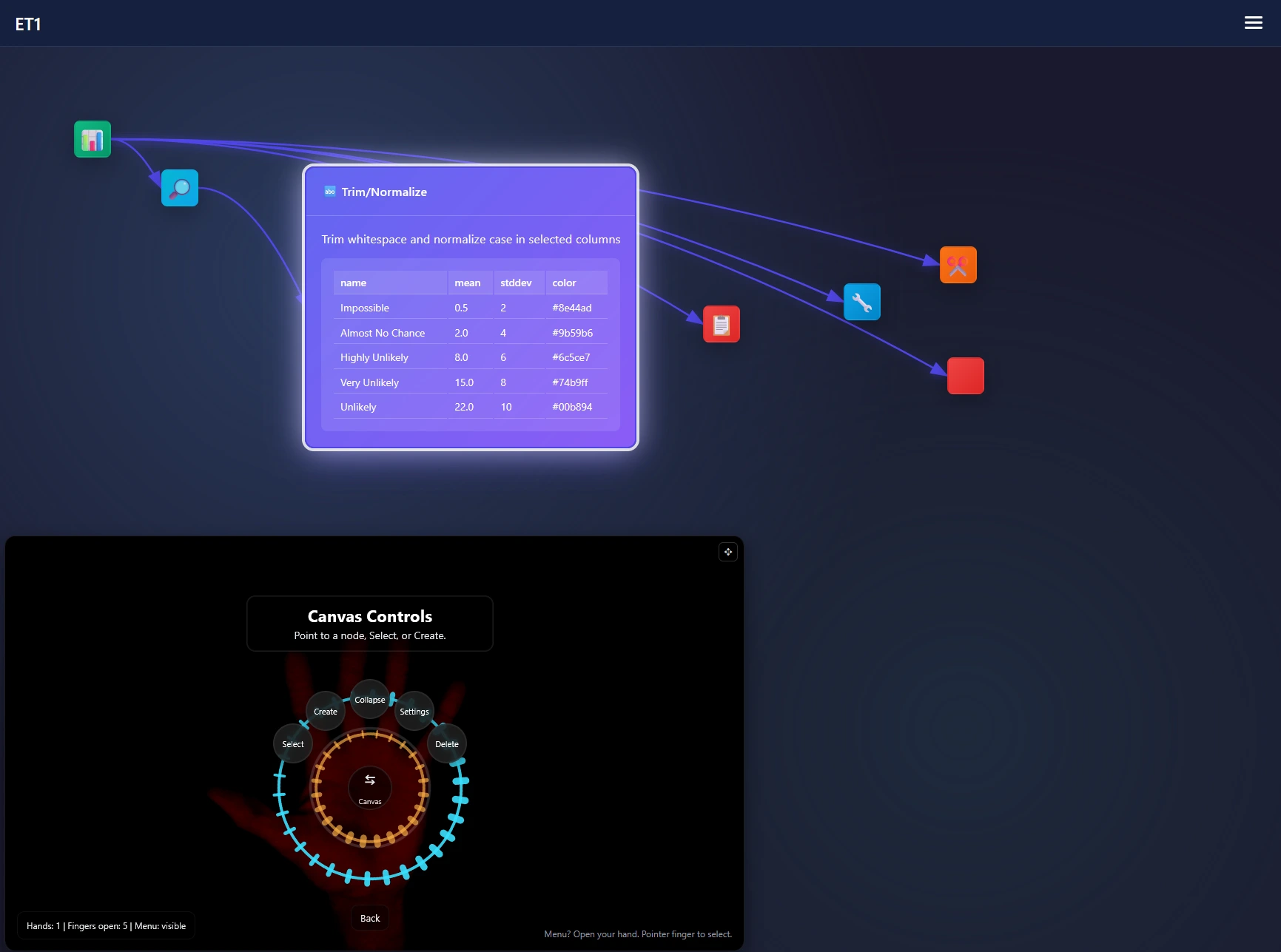
Trim/Normalize Node is built to help you quickly clean your data pipelines and like the Column Renamer, built to make data pipeline maintaining simple, not complicated, and more than anything, easy to repeat. AT TIMES WE NEED CAPITAL LETTERS! Perhaps you-have-a-lot-of-this-happening (special characters you don’t ne3ed). then there are times we aren’t trying to scream, […] The post ET1’s Trim/Normalize Node appeared first on Dev3lop.| Dev3lop
On your magic quest to join data? We call it the Joiner node. A simple joining solution that helps people join data at a row level. In ET1, Joiner is focused on “keeping it simple” and will aim to automatically infers your joins. ET1 assumes. Inferring a join means it assumes you prepared the data […]| Dev3lop
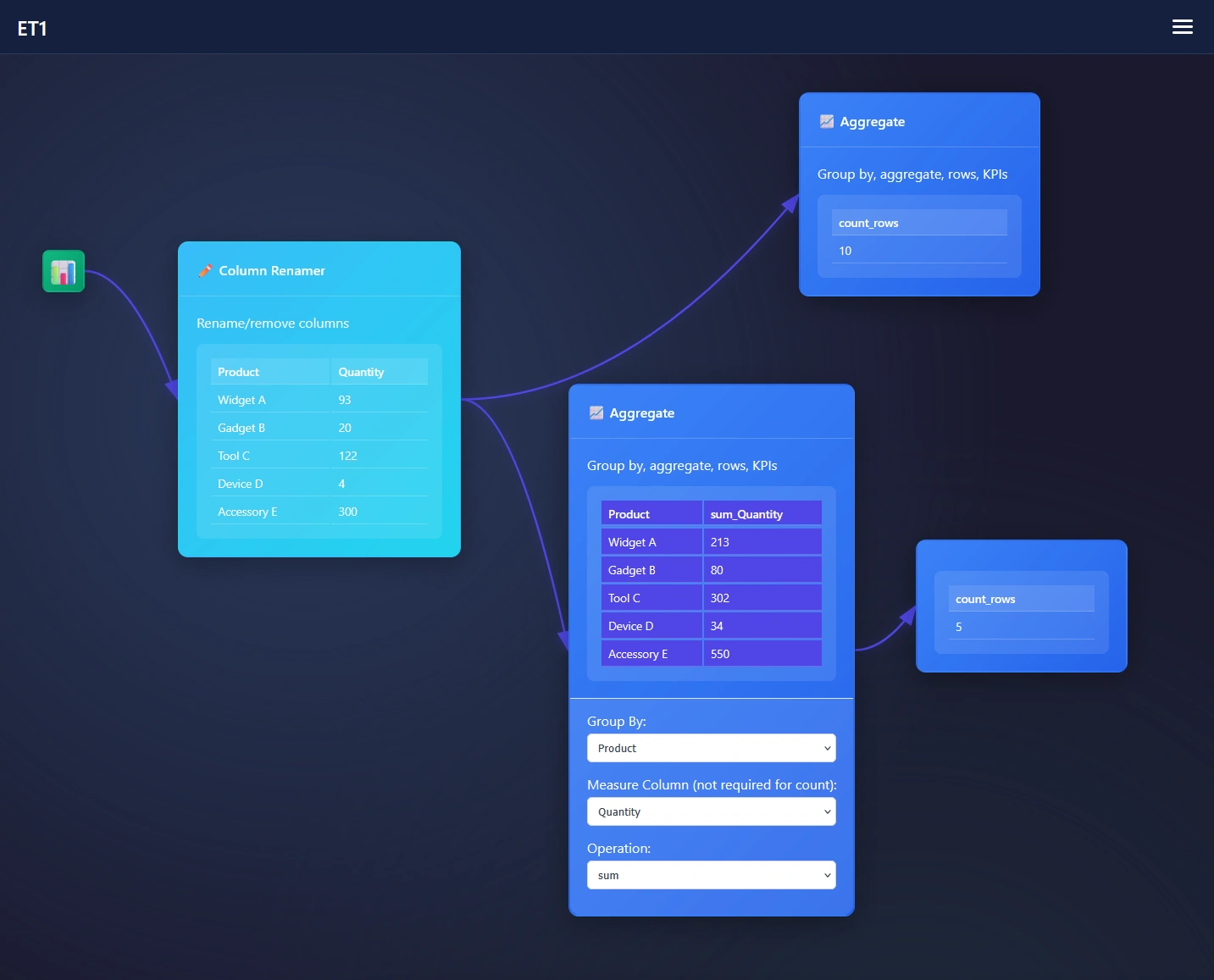
Eager to group data? The Group By feature can be found in the Aggregation Node. Add the aggregation node to the canvas and send data downstream to this node. We have many products, however duplicate quantities across many suppliers, and we need to check the quantity of entire business! Using Group By in ET1 Open […]| Dev3lop
When you have numbers, you have a need for a Measure Filter Node. Numbers are here, lets talk about it. Filtering with a number or decimal is straight forward using ET1. Using Measure Filter Node in ET1 Get started using the Measure Filter node. Attach data pipeline / arrow. This flows data downstream. Then you […]| Dev3lop
The Split node lets ET1 user split one or more column into multiple columns. This particular node is great for the times you have multiple rows of data with consistent delimiters. The data we are splitting Here is the CSV you need to follow the overview. We will pass this data through the CSV Input […]| Dev3lop
If a web-cam is available ET1’s code will try to automatically sync and if you can wave and point, this radial menu is a fun way to augment your ETL development. Using computer vision (explained in depth below) we map a skeleton over your hands and able to create a radial menu we are calling […]| Dev3lop
The Unique Filter Node or Unique Tool finds unique values per row in your data pipelines, or allows people to quickly review duplicates only. Plus, you can select what column(s) to find unique values within. This enables people to easily understand what is inside of a column. Duplicate rows happen, The Unique Filter node manages […]| Dev3lop
Seeking to append fields like the Alteryx Desktop software? The Joiner Node and Aggregate node is here to help. You will also need a constant to join on across both data streams. We will show you how in this example below where we are sent 6million records in a CSV and asked to append the […]| Dev3lop
Dealing with duplicate columns? This particular node is designed to remove similarly named column headers. If “State”=”State” then we remove the last column and only keep the first column. “Remove duplicate columns based on similar header names” Currently there are no settings for this tool because today Duplicate Columns Node solves problems without requiring a […]| Dev3lop
Familiar with graphs? How about DAGs? This is not a paradigm shift, but think of DAG as a cool way for tiny team in Austin/Dallas Texas to build an Extract Transform and Load software! Like a guitar pedal, there’s an input and output. Sometimes it’s just an output. Then you have your input only tools. […]| Dev3lop
Aggregation, what a classic. Aggregating your data is a landmark trait for any data steward, data wrangler, or data analyst. In ET1, you can easily aggregate your data. The Power of Grouping (Group By) with the Aggregate Node Aggregations turn a sea of numbers into meaningful insights. Group by in ET1 is nested in the […]| Dev3lop
Are you combining the data? We have you covered. ET1 has all the right tools. The Three Musketeers of Data Combination 1. 🤝 Join (The Matchmaker) 2. 🔗 Union (The Stacker) 3. 🧵 Concat ([bring], [it], [together],[with],”glue”) Concat merges everything, and it doesn’t care about data types. Real-World Examples Join: Union: Concat: Pro Tips No […]| Dev3lop
The filtering nodes help you reduce the number of rows, drill into the exact information needed, and create a data set that will add value VS confuse your audience. When filtering, remember you’re reducing the amount of data coming through the node, or you can swap to include. Include, exclude, and ultimately work on your […]| Dev3lop