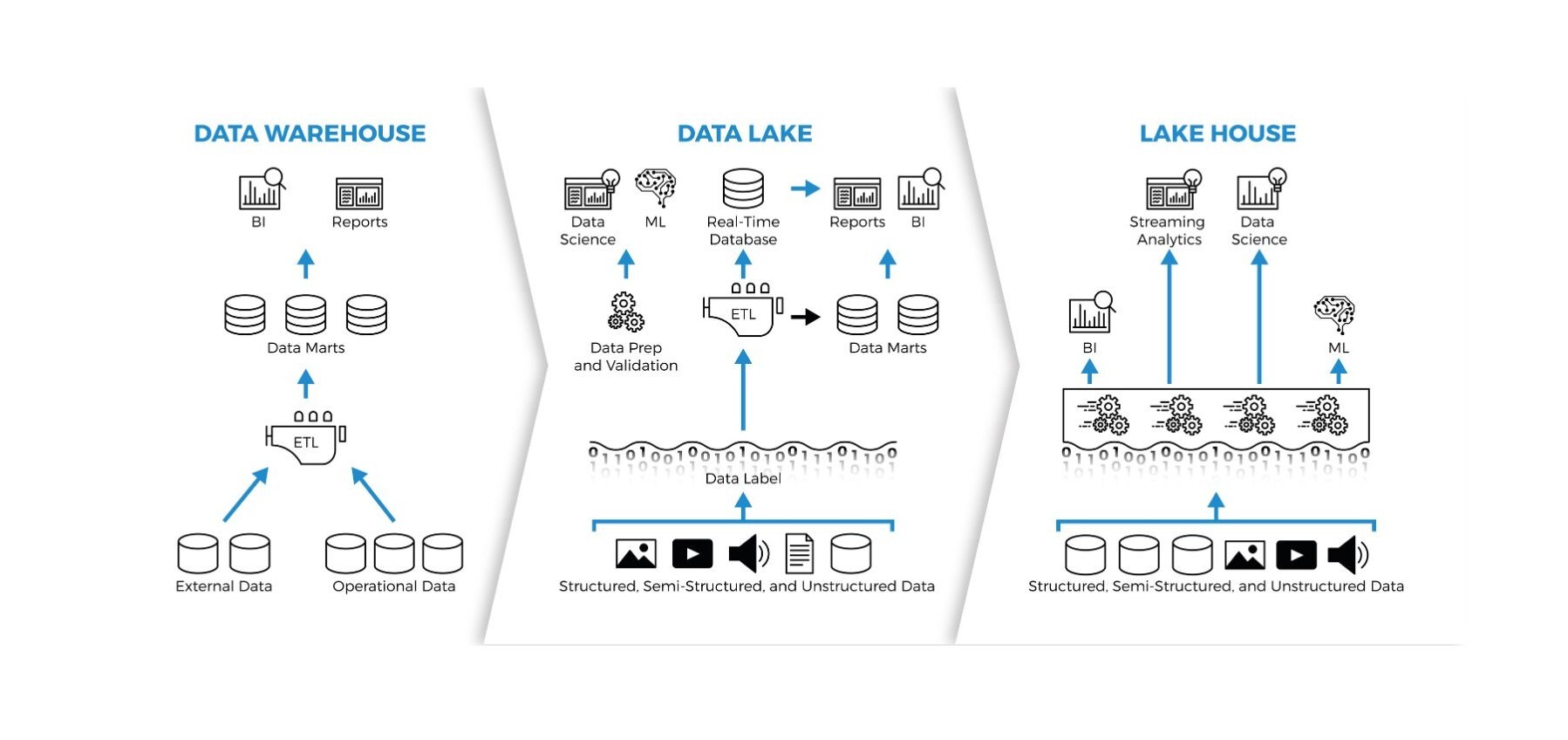
Data Lakehouse: Qué Es y Ventajas Clave de Su Arquitectura
El data lakehouse combina lo mejor del data lake y del data warehouse. Conoce su arquitectura, beneficios y tendencias clave en la nube.| blog.bismart.com
Reading Time: 3minutesFor years, enterprises have invested heavily in cloud-native lakehouses like Snowflake and Databricks to unify analytics at scale. These platforms are powerful—the culmination of decades of innovation in analytic technology stacks, starting with enterprise data warehouses, continuing through the “big... The post The Naked Truth about Data Lakehouses: Delayed Projects and Wasted $Millions appeared first on Data Management Blog - Data Integration and Modern Data Manag...| Data Management Blog – Data Integration and Modern Data Management Articles...
El data lakehouse combina lo mejor del data lake y del data warehouse. Conoce su arquitectura, beneficios y tendencias clave en la nube.| blog.bismart.com

SentinelOne announces its intent to acquire Observo AI, the category-defining data platform for AI-native telemetry pipeline management.| SentinelOne
LogSeam transforms log management with Tigris, achieving massive cost savings and performance improvements in their security data lake architecture.| Tigris Object Storage Blog
The modern enterprise faces an unprecedented challenge: managing explosive data growth while extracting meaningful insights that drive business value. For decades, organizations have struggled with a fundamental trade-off between data warehouses and data lakes, sacrificing either flexibility for performance or cost-effectiveness for governance. Enter the data lakehouse, a revolutionary architecture that eliminates this compromise entirely. […] The post The Data Lakehouse: The Future of Ente...| Techwards
Reading Time: 4minutesImagine you’re a financial analyst at a pension fund, racing against the clock to deliver a major corporate client’s portfolio breakdown before fiscal year end. You’re juggling CRM data, financial market reports, and a tangle of Excel exports. Or picture... The post Beyond the Lakehouse: Denodo’s RAG-Driven Data Revolution appeared first on Data Management Blog - Data Integration and Modern Data Management Articles, Analysis and Information.| Data Management Blog – Data Integration and Modern Data Management Articles...

Learn 5 key considerations for building a scalable, cost-effective GCP data lake. Optimize performance, storage, and analytics on Google Cloud.| HatchWorks AI

Learn the key differences between data lakes, warehouses, and marts, their use cases, and best practices to choose the right data solution.| HatchWorks AI
In industrial operations, getting data to the cloud is critical to gain insights for increased productivity. Getting the data is simpler; the challenge today is making that data useful once it gets there. Too often, companies race to implement cloud connectivity, collect massive volumes of OT data, and then find themselves stuck. The dashboards don’t… The post Why context is everything: Avoiding data swamps in the cloud appeared first on Cirrus Link.| Cirrus Link

The data lakehouse has emerged as a powerful and popular data architecture, combining the scale of data lakes with the management features of data warehouses.| Data Management Blog - Data Integration and Modern Data Management Articles, ...

Discover how multiple storage backends support in lakeFS provides a capability that unifies data management across all your storage systems.| Git for Data - lakeFS

AI data storage solutions are a key component of the modern AI landscape. Discover benefits, common challenges, and best practices. Read more| Git for Data - lakeFS

Learn how to get started with data lake implementation. Explore the essentials to enhance your data management strategies.| Careers at lakeFS: Help Close the Data Infrastructure Gap

The latest release of the Vertica analytical database, now OpenTextTM VerticaTM includes a lot of features that Vertica customers have been eagerly awaiting like: Resharding the database as needed Rollback snapshots that capture a moment in time without a whole other data copy Workload routing so you can automate directing specific queries to just the right compute for that type of job. And more ...| OpenText™ Vertica™
IBM has taken another open source technology provider into its portfolio, acquiring Ahana, one of the leading vendors behind the massively parallel distributed in-memory SQL query engine Presto. Presto, first created and still actively developed at Meta, has attracted a broad array of open source contributors, and is championed by several vendors. It has alsoContinue reading "IBM and Ahana – A Lakehouse Down Payment"| IT Market Strategy
Oh my my look what the cat dragged in| Port 1433

Tom Breur 31 August 2019 The job market is “hot”, and data science skills are in high demand. Yet many junior data scientists are struggling to get ahead. How can that be? Is it because ever…| Data, Analytics and beyond
