Configuring AWS OpenSearch Service cluster monitoring with CloudWatch, monitoring JVM memory and k-NN, creating Grafana dashboards and alerts in Alertmanager| RTFM: Linux, DevOps, and system administration | DevOps-engineering, and syst...
MariaDB has announced Enterprise Platform 2026 with a clear pitch to developers, data teams and DBAs: unify the transactional, analytical and vector engines in one high-performance platform, add built-in RAG and AI agents, and run it in a serverless cloud to handle the elastic, unpredictable demand of agentic applications. The promise: fewer moving parts, lower […]| System Administration
The idealized model of a transactional data storage system is one of a sequential, serializable system, where clients can submit transactions and the system ensures the outcomes are as if those transactions were executed against a single copy of that data. In practice, performance limitations of this model have historically pushed systems to explore a wide set of alternative, weakly consistent models.| William Schultz
Learn how Microsoft Azure SQL Managed Instance helps organizations move from legacy constraints to a scalable and secure AI-ready foundation. The post Innovation spotlight: How 3 customers are driving change with migration to Azure SQL appeared first on Microsoft Azure Blog.| Microsoft Azure Blog
In this tutorial, we'll deploy a cohesive system that allows distributed SQL querying across large datasets stored in Minio, with Trino leveraging metadata from Hive Metastore and table schemas from Redis.| MinIO Blog
A complete TypeScript rewrite with drop-in ORM support, full mysql2/pg compatibility layers, and smarter parsing for Aurora Serverless v2's Data API.| JeremyDaly.com
Transactional databases, the engines behind applications from e-commerce platforms and payment systems to customer portals and financial services, demand speed and consistency. While many database administrators focus on CPU and memory, storage latency, particularly tail latency, is a critical but often overlooked bottleneck. This is where StorPool storage makes an enormous difference. The Problem with ... How Unprecedented Low Storage Latency Solves OLTP Performance Problems The post How Unp...| StorPool
Diagnosing the Data Disorder: Why Data Competency Is Critical for Modern Businesses? by Pure Storage Blog Data competency is not only an IS/IT capability; it is a much broader, cross-functional capability and lever for strategic business decisions. The post Diagnosing the Data Disorder: Why Data Competency Is Critical for Modern Businesses? appeared first on Pure Storage Blog.| Pure Storage Blog
Managing Enterprise Storage with Pure Fusion in PowerShell by Pure Storage Blog This article explores how to create and deploy application-specific storage workloads using Pure Fusion and PowerShell. The post Managing Enterprise Storage with Pure Fusion in PowerShell appeared first on Pure Storage Blog.| Pure Storage Blog
This Berkeley systems group paper opens with the thesis that LLM agents will soon dominate data system workloads. These agents, acting on behalf of users, do not query like human analysts or even like the applications written by them. Instead, the LLM agents bombard databases with a storm of exploratory requests: schema inspections, partial aggregates, speculative joins, rollback-heavy what-if updates. The authors calls this behavior agentic speculation.| Metadata
This paper from SIGMOD 2016 proposes a transaction healing approach to improve the scalability of Optimistic Concurrency Control (OCC) in main-memory OLTP systems running on multicore architectures. Instead of discarding the entire execution when validation fails, the system repairs only the inconsistent operations to improve throughput in high-contention scenarios.| Metadata
This EuroSys '23 paper reads like an SOSP best paper. Maybe it helped that EuroSys 2023 was in Rome. Academic conferences are more enjoyable when the venue doubles as a vacation.| Metadata
Consistent replication algorithms can be placed on a sliding scale based on how they handle replica failures. Across the three common points on this spectrum, the resource efficiency, availability, and latency are compared, providing guidance for how to choose an appropriate replication algorithm for a use case.| Transactional
The background and context on why the groupings exist the way they do, and thedifferent sorts of pages you’ll find in this section. But, this is allphilosophical waxing, so quite skippable.| Transactional
Master Apache Flink watermarks with this interactive simulation. Learn what they are, why you need them, and how to configure them through hands-on examples.| Flink Watermarks…WTF?
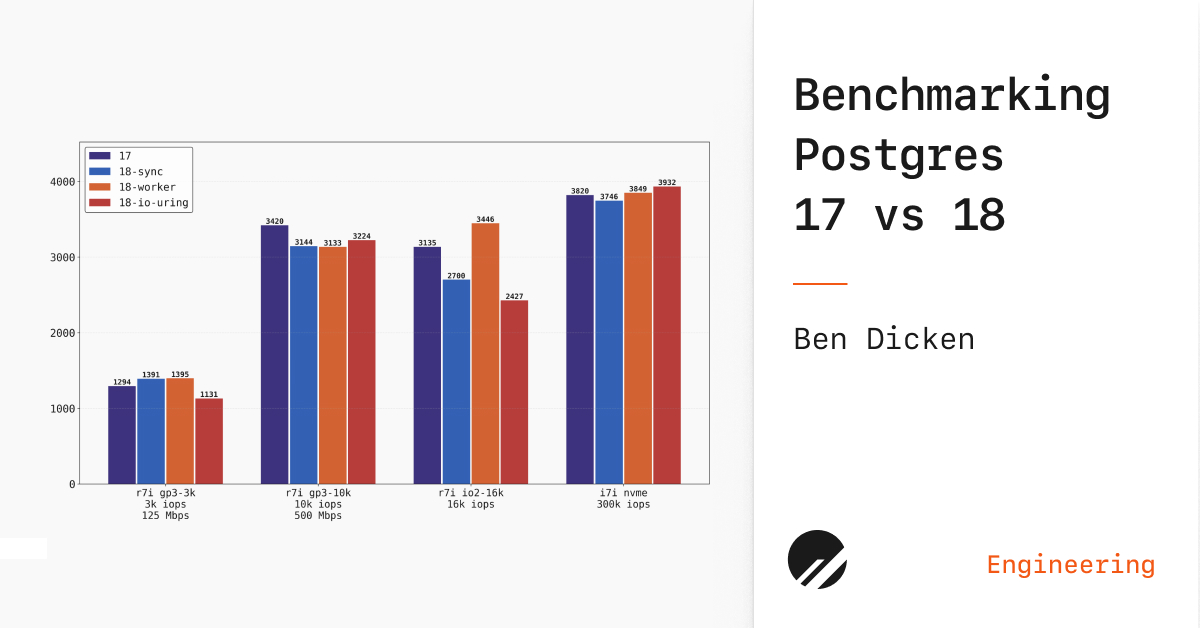
Postgres 18 brings a significant improvement to read performance via async I/O and I/O worker threads. Here we compare its performance to Postgres 17.| planetscale.com
At the Migrate and Modernize Summit, we’re announcing a set of agentic AI solutions and offerings to speed transformation and reduce friction. Learn more.| Microsoft Azure Blog
I am trying to understand how to properly store ordered information in a relational database. An example: Say I have a Playlist, consisting of Songs. Inside my Relational Database, I have a table...| Software Engineering Stack Exchange
Introduction Versatile as it is, SQLite still suffers from one major drawback. Which is write concurrency. SQLite, using the Write-Ahead-Log (WAL) journaling mode, supports an unlimited number of r…| Oldmoe's blog
My career in data started as a SQL Server performance specialist, which meant I was deep into the nuances of indexes, locking and blocking, execution plan analysis and query design. These days I’m more in the world of the open table format such as Apache Iceberg. Having learned the internals of both| Jack Vanlightly
OSWALD is a Write-Ahead Log (WAL) design built exclusively on object storage primitives. It works with any object storage service that…| nvartolomei.com
Налаштування моніторингу кластеру AWS OpenSearch Service з CloudWatch, та моніторинг пам'яті JVM та k-NN, створення Grafana dashboard та алертів в Alertmanager| RTFM: Linux, DevOps та системне адміністрування | De...
We’re pleased to introduce the pgvector extension on Heroku Postgres . In an era where large language models (LLMs) and AI applications are paramount, pgvector provides the essential capability for performing high-dimensional vector similarity searches. This allows Heroku Postgres to quickly find similar data points in complex data, which is great for applications like recommendation systems and prompt engineering for LLMs. As of today, pgvector is fully compatible with all Production-tier ...| Heroku
In the first part, we covered the basics of AWS OpenSearch Service in general and the types of instances for Data Nodes – AWS: Getting Started with OpenSearch Service as a Vector Store. In the second part, we covered access, AWS: Creating an OpenSearch Service Cluster and Configuring Authentication and Authorization. Now let’s write… Read More » The post Terraform: creating an AWS OpenSearch Service cluster and users first appeared on RTFM: Linux, DevOps, and system administration.| RTFM: Linux, DevOps, and system administration
We are currently using AWS OpenSearch Service as a vector store for our RAG with AWS Bedrock Knowledge Base. We will talk more about RAG and Bedrock another time, but today let’s take a look at AWS OpenSearch Service. The task is to migrate our AWS OpenSearch Service Serverless to Managed, primarily due to… Read More » The post AWS: introduction to the OpenSearch Service as a vector store first appeared on RTFM: Linux, DevOps, and system administration.| RTFM: Linux, DevOps, and system administration
In the previous part, AWS: Getting Started with OpenSearch Service as a Vector Store, we looked at AWS OpenSearch Service in general, figured out how data is organized in it, what shards and nodes are, and what types of instances we actually need for data nodes. The next step is to create a cluster… Read More » The post AWS: creating an OpenSearch Service cluster and configuring authentication and authorization first appeared on RTFM: Linux, DevOps, and system administration.| RTFM: Linux, DevOps, and system administration
In the case of distributed, high-throughput string interning, horizontal scaling can be achieved by breaking up one large keyspace that requires strict coordination into billions of smaller keyspaces that can be randomly load-balanced across.| Jaz’s Blog
There are books & many articles online, like this one arguing for using Postgres for everything. I thought I’d take a look at one use case - using Postgres instead of Redis for caching. I work with APIs quite a bit, so I’d build a super simple HTTP server that responds with data from that cache. I’d start from Redis as this is something I frequently encounter at work, switch it out to Postgres using unlogged tables and see if there’s a difference.| Dizzy zone
The [PostgreSQL Global Development Group](https://www.postgresql.org) today announced the release of [PostgreSQL 18](https://www.postgresql.org/docs/18/release-18.html), the latest version of the world's most advanced …| PostgreSQL News
Happy September! School is back in session for most, and fall is just around the corner. To kick off the school year, the Idaho Commission for Libraries is conducting a comprehensive 12-month campaign to highlight the diverse array of databases available at no cost to all Idahoans through LiLI.org. But we can't do it| Idaho Commission for Libraries
В першій частині розібрались з основами AWS OpenSearch Service взагалі, і з типами інстансів для Data Nodes – AWS: знайомство з OpenSearch Service в ролі vector store. В другій – з доступами, AWS: створення OpenSearch Service cluster та налаштування аутентифікації і авторизації. Тепер напишемо Terraform code для створення ...| RTFM: Linux, DevOps та системне адміністрування
After a user signaled a performance issue in a Matrix client, we have added new tracing timers in the Matrix Rust SDK to spot the problem. Once found, we have fixed an SQL query improving the throughput from 19k to 251k events/sec, and the speed from 502ms to 39ms. Then after another creative patch, the throughput has been improved to 4.2M events/sec, and the speed to 2ms.| mnt.io
All the core components of pgEdge Distributed Postgres, along with any other pgEdge repositories that previously used the pgEdge Community License have now been re-licenced under the permissive PostgreSQL License, as approved by the Open Source Initiative!| www.pgedge.com
CedarDB is a database system that delivers unmatched performance for transactions and analytics, from small writes to handling billions of rows. Built on cutting-edge research to power today’s tools and tomorrow’s challenges.| cedardb.com
Learn how queues make horizontal scaling, scheduling, and flow control easier in cloud systems, and how to make them durable and observable.| www.dbos.dev
В попередній частині – AWS: знайомство з OpenSearch Service в ролі vector store – подивились на AWS OpenSearch Service взагалі, трохи розібрались з тим, як в ньому організовані дані, що таке shards та nodes, і які нам власне типи інстансів для data nodes треба. Наступний крок – створити кластер і подивитись н...| RTFM: Linux, DevOps та системне адміністрування
Знайомство з AWS OpenSearch Service в ролі vector store для AWS Bedrock Knowledge Base та планування ресурсів OpenSearch кластеру| RTFM: Linux, DevOps та системне адміністрування | De...
Database migration is one of those tasks that can either go smoothly or turn into a nightmare depending on your preparation. If you're considering migrating from MySQL to PostgreSQL, you're making a smart choice – PostgreSQL offers superior data integrity, better JSON support, advanced indexing, and robust ACID compliance. However, the migration process requires careful planning and understanding of the differences between these two database systems. In this comprehensive guide, I'll walk y...| TechPlanet
Is SQLite durable by default? What settings guarantee durability? The documentation and even comments from its creator give conflicting answers.| www.agwa.name
Object storage is the primary storage solution for OLAP databases. This survey highlights major database players that have embraced this movement.| MinIO Blog