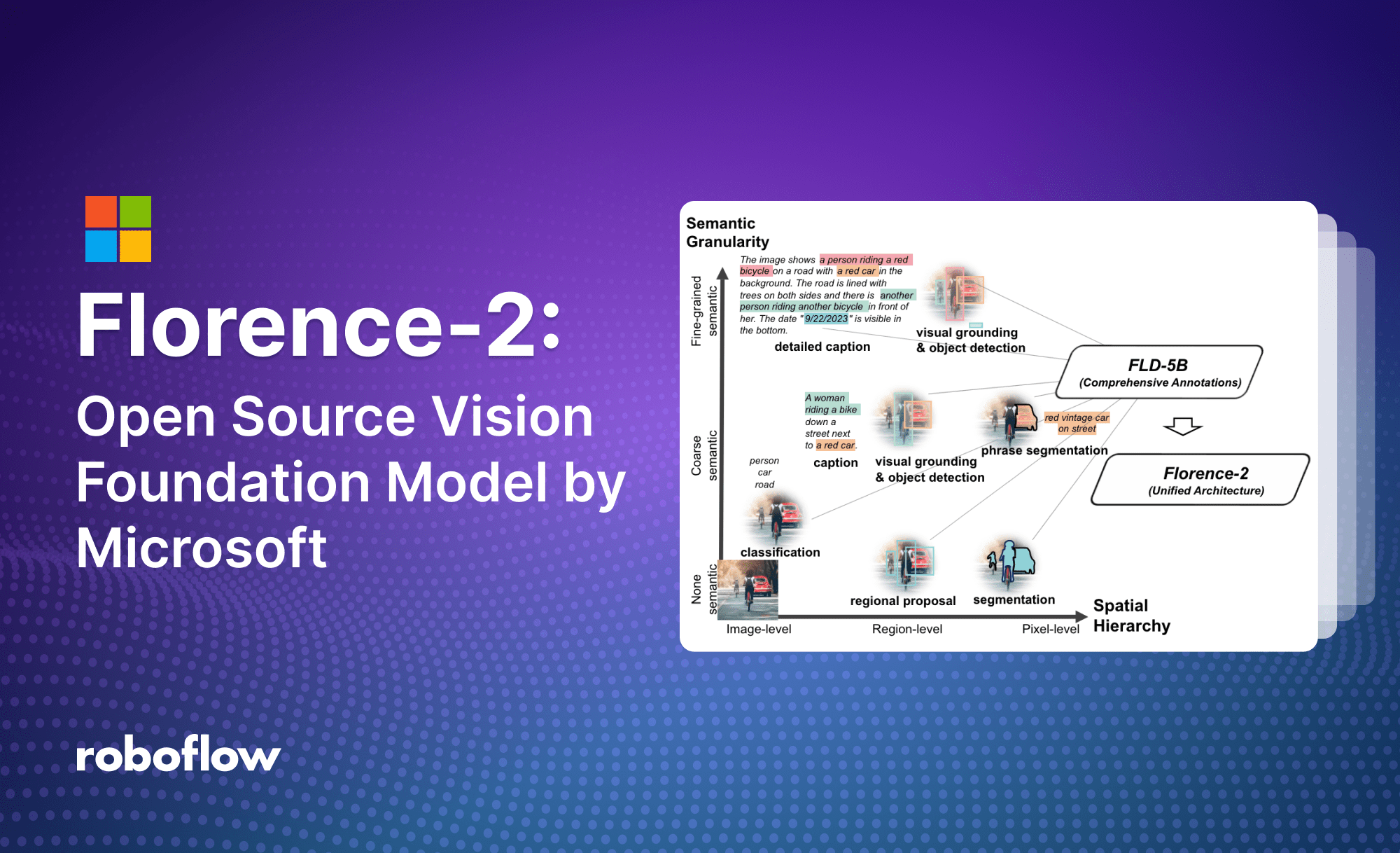
Accurate data labeling is essential for training machine learning models. This guide explores top data labeling platforms, key features to consider, and pros and cons so you can choose the right tool for building better AI.| Roboflow Blog
Object detection has entered a new era in 2025. Next-generation models are combining transformer efficiency and real-time speed to power breakthroughs in automation, robotics, and visual intelligence across every industry. See the best models.| Roboflow Blog
YOLO26 brings faster CPU inference, small-object accuracy, and edge optimization to the YOLO family. See how it stacks up against today’s leading computer vision models.| Roboflow Blog
Modern manufacturing runs on precision, and computer vision is redefining what’s possible on the factory floor. See how AI-powered inspection systems detect and act on defects in real time.| Roboflow Blog
Learn how to integrate Roboflow Batch Processing with AWS S3 to run large-scale image inference efficiently. This step-by-step guide shows how to process 100k+ images at a lower cost.| Roboflow Blog
Learn how to integrate Roboflow Batch Processing with Azure Blub Storage to run large-scale image inference efficiently. This step-by-step guide shows how to process 100k+ images at a lower cost.| Roboflow Blog
Learn how to integrate Roboflow Batch Processing with Google Cloud Storage to run large-scale image inference efficiently. This step-by-step guide shows how to process 100k+ images at a lower cost.| Roboflow Blog
We go hands-on with the NVIDIA DGX Spark, a "supercomputer" built for local AI development, and test a real-time computer vision project.| Roboflow Blog
Instance segmentation lets AI models identify and outline each object in an image with pixel-perfect precision. In this tutorial, learn how to label segmentation data, and train a high-accuracy RF-DETR model.| Roboflow Blog
This blog explores the top code editors for developing, testing, and deploying Vision AI projects. It covers Visual Studio Code, Cursor, Colab, Jupyter, and PyCharm, explaining their key features, pros, and cons.| Roboflow Blog
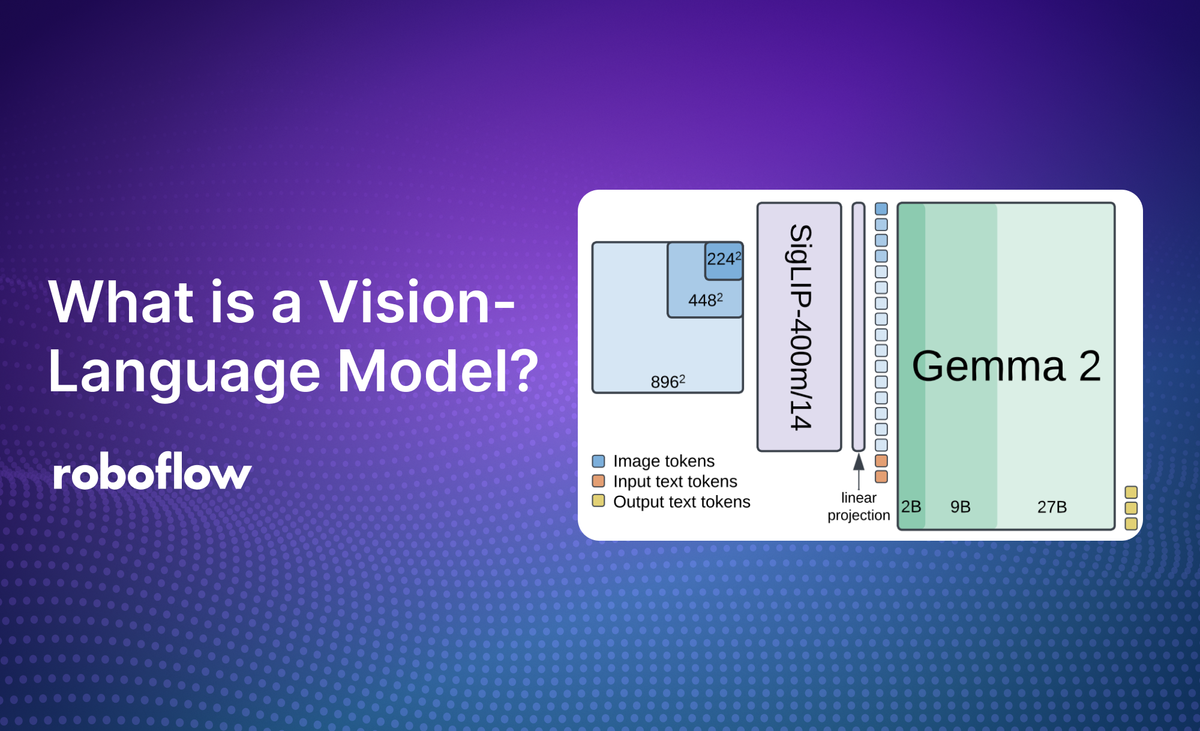
Vision-Language Models are getting smaller, faster, and smarter - no cloud required. In this guide, we explore the best local VLMs you can run on your own hardware, from Llama 3.2 Vision to SmolVLM2, and show how to deploy them efficiently with Roboflow Inference.| Roboflow Blog
Learn how to use RF-DETR, Roboflow’s state-of-the-art real-time object detection model, to build a workflow that identifies, tracks, and labels objects across video frames with high accuracy and efficiency.| Roboflow Blog
TLDR: VISTA is a multi agent framework that improves text to video generation during inference, it plans structured prompts as scenes, runs a pairwise tournament to select the best candidate, uses specialized judges across visual, audio, and context, then rewrites the prompt with a Deep Thinking Prompting Agent, the method shows consistent gains over strong […] The post Google AI Introduces VISTA: A Test Time Self Improving Agent for Text to Video Generation appeared first on MarkTechPost.| MarkTechPost
Last Updated on October 15, 2025 by Editorial Team Author(s): Hira Ahmad Originally published on Towards AI. When Transformers Multiply Their Heads: What Increasing Multi-Head Attention Really Does Transformers have become the backbone of many AI breakthroughs, in NLP, vision, speech, etc. A central component is multi-head self-attention: the notion that instead of one attention lens, a model uses several, each looking at different aspects of the input. But more heads isn’t always strictly ...| Towards AI
Discover how CaseGuard Studio’s AI-powered redaction platform automates data protection with 98% accuracy. Ideal for law enforcement, healthcare, legal, and financial sectors.| AI News
Our interview series is here to deliver you digestible intelligence from the organizations and innovators leading the world of AI in healthcare - through expert and in-depth interviews.| AI Accelerator Institute
In this post we break down Meta AI's DINOv3 research paper, which introduces a state-of-the-art Computer Vision foundation models family The post DINOv3 Paper Explained: The Computer Vision Foundation Model appeared first on AI Papers Academy.| AI Papers Academy
Dive into Continuous Thought Machines, a novel architecture that strive to push AI closer to how the human brain works The post Continuous Thought Machines (CTMs) – The Era of AI Beyond Transformers? appeared first on AI Papers Academy.| AI Papers Academy
Dive into Perception Language Models by Meta, a family of fully open SOTA vision-language models with detailed visual understanding The post Perception Language Models (PLMs) by Meta – A Fully Open SOTA VLM appeared first on AI Papers Academy.| AI Papers Academy
In this article, we create a background replacement application using BiRefNet. We cover the code using Jupyter Notebook and create a Gradio application as well. The post Background Replacement Using BiRefNet appeared first on DebuggerCafe.| DebuggerCafe
In this article, we explore the BiRefNet model for high-resolution dichotomous segmentation. Along with discussing the key elements of the paper, we also create a small background removal codebase usign the pretrained model. The post Introduction to BiRefNet appeared first on DebuggerCafe.| DebuggerCafe
IBM releases GraniteDocling, an open-source compact document AI model with improved accuracy, multilingual support, and enterprise readiness| MarkTechPost
Posted by Colby Banbury, Emil Njor, Andrea Mattia Garavagno, Vijay Janapa Reddi – Harvard UniversityTinyML is an exciting frontier in machine learning, enabling models to run on extremely low-power devices such as microcontrollers and edge devices. However, the growth of this field has been stifled by a lack of tailored large and high-quality datasets. That's where Wake Vision comes in—a new dataset designed to accelerate research and development in TinyML.| The TensorFlow Blog
Designed for millions of robotic developers, NVIDIA Jetson Thor delivers 2,070 FP4 teraflops to tackle complex applications including agentic AI, high-speed sensor processing and general robotics tasks.| NVIDIA Blog
Learn how to take a dataset from Voxel51 into Roboflow, train an RF-DETR model, and deploy it to the cloud, private servers, or edge devices. This step-by-step guide walks you through dataset conversion, model training, workflow testing, and real-world integration.| Roboflow Blog
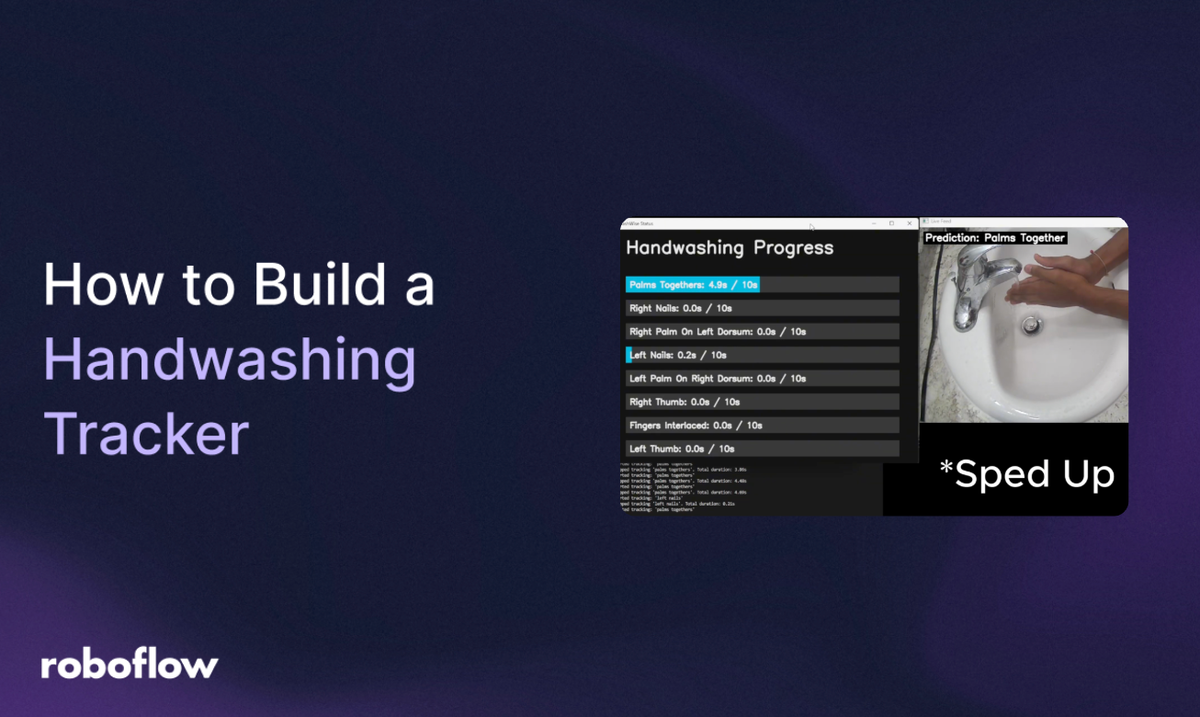
With this project, we integrate real-time feedback and computer vision to develop a hand-washing steps-tracking system using a Python application and a Roboflow-trained model.| Roboflow Blog
The latest Granite vision model recently came in second on the OCRBench leaderboard, and is the best-performing small model on the chart.| IBM Research
Enhance driving safety with Vision AI for real-time alerts on speeding and proximities, preventing accidents and ensuring operational continuity.| viso.ai
NVIDIA was today named an Autonomous Grand Challenge winner at the Computer Vision and Pattern Recognition (CVPR) conference, held this week in Nashville, Tennessee. The announcement was made at the Embodied Intelligence for Autonomous Systems on the Horizon Workshop. This marks the second consecutive year that NVIDIA’s topped the leaderboard in the End-to-End Driving at Read Article| NVIDIA Blog
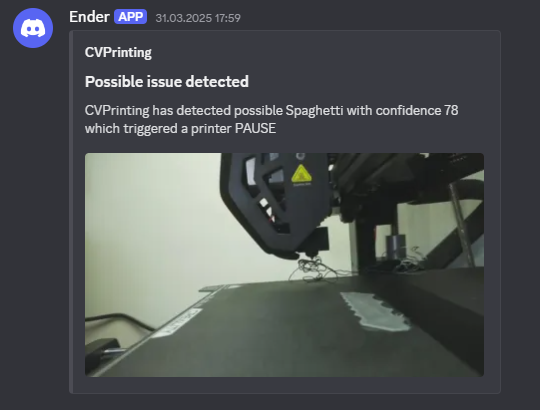
Computer vision for detecting issue during 3d printing with automatic notification to Discord and Telegram and pausing the print. This plugin has minimal HW requirements. Recommended hardware is Raspberry pi 5, older version are not supported.| OctoPrint Plugin Repository
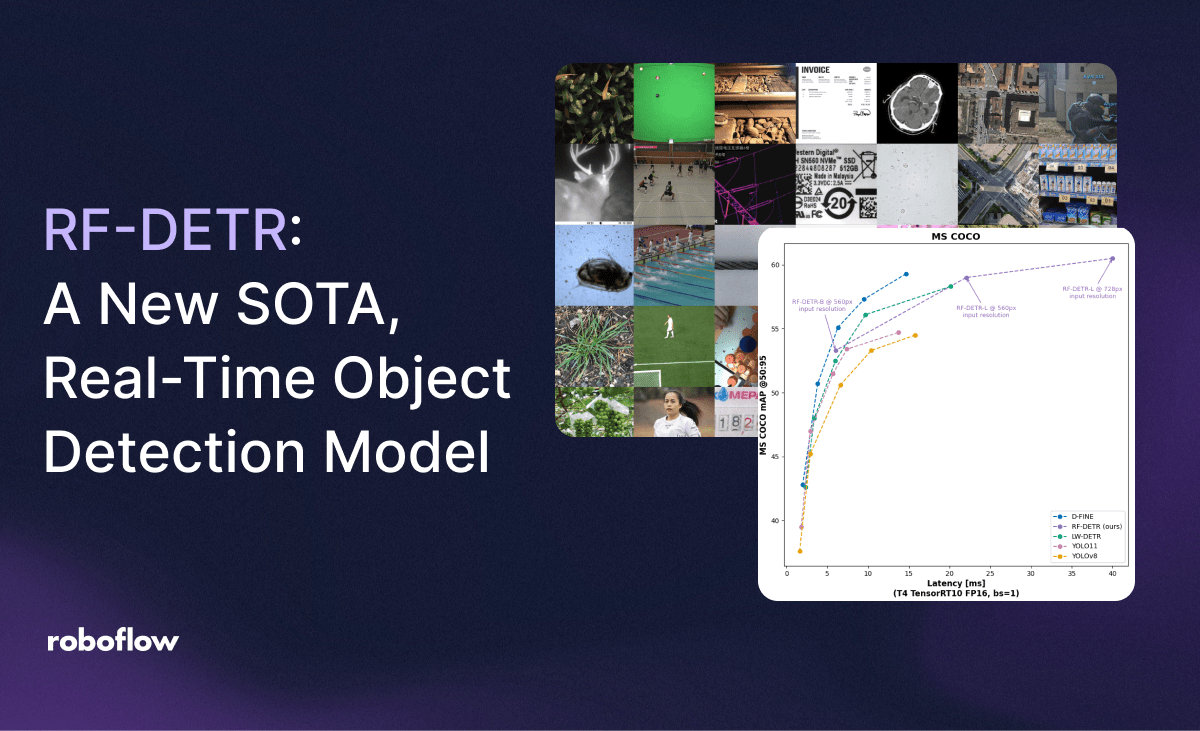
Today we are releasing RF-DETR, a state-of-the-art real-time object detection model. Learn more about how RF-DETR works and how to use the model.| Roboflow Blog
Intro Since many of my posts were mostly critical and arguably somewhat cynical [1], [2], [3], at least over the last 2-3 years, I decided to switch gears a little and let my audience know I'm actually a very constructive, busy building stuff most of the time, while my ranting on the blog is mostly a side project to vent, since above everything I'm allergic to naive hype and nonsense. Nevertheless I've worked in the so called AI/robotics/perception for at least ten years in industry now (an...| Piekniewski's blog
Computer vision plays a big part in deploying automated visual inspection, making it possible to process the amounts of data from this automation.| AI Accelerator Institute
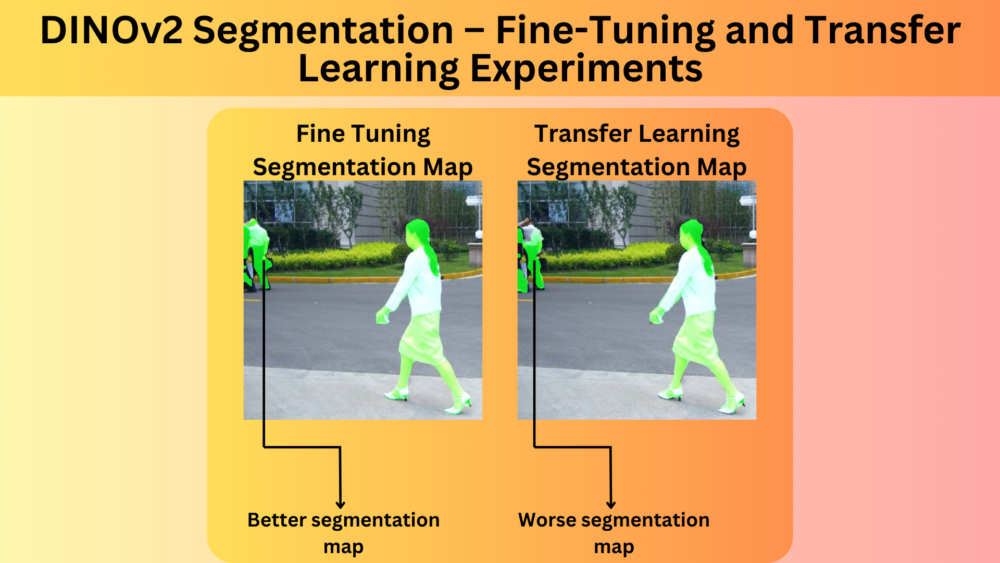
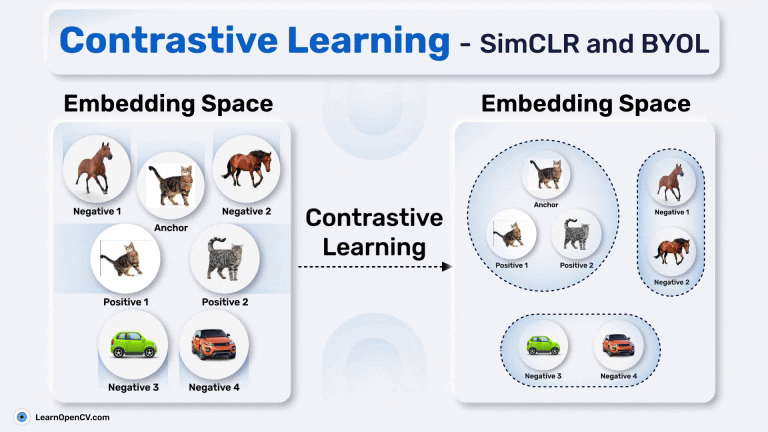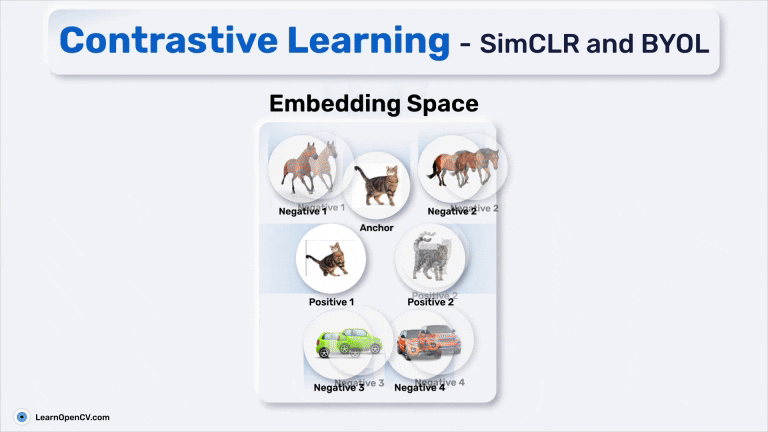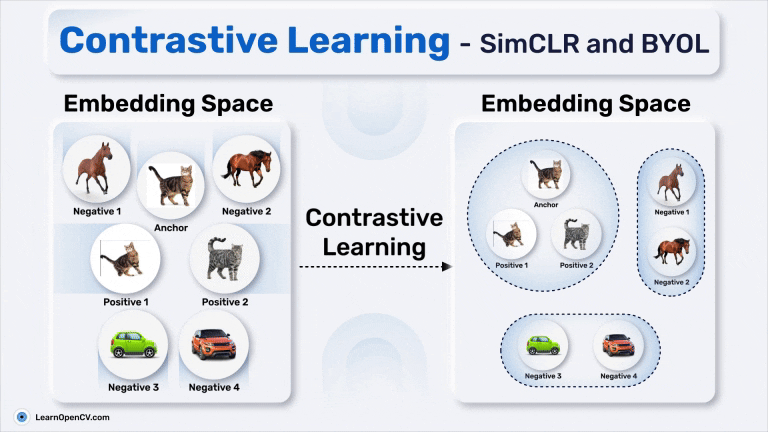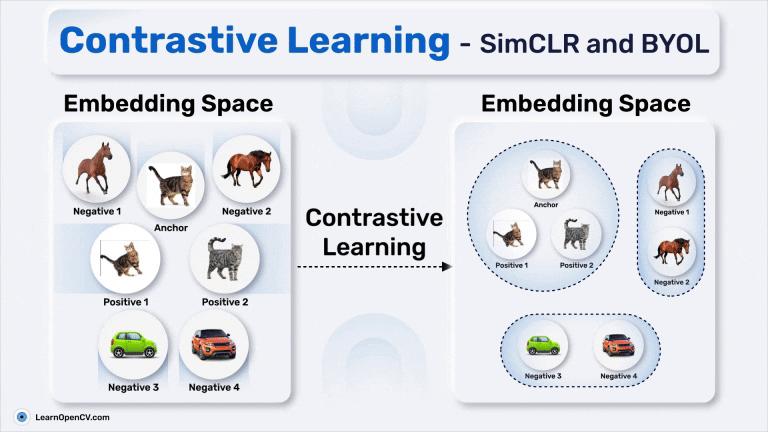
This article explores the history of self-supervised learning, introduces DINO Self-Supervised Learning, and shows how to fine-tune DINO for road segmentation| LearnOpenCV – Learn OpenCV, PyTorch, Keras, Tensorflow with code, & tutorials
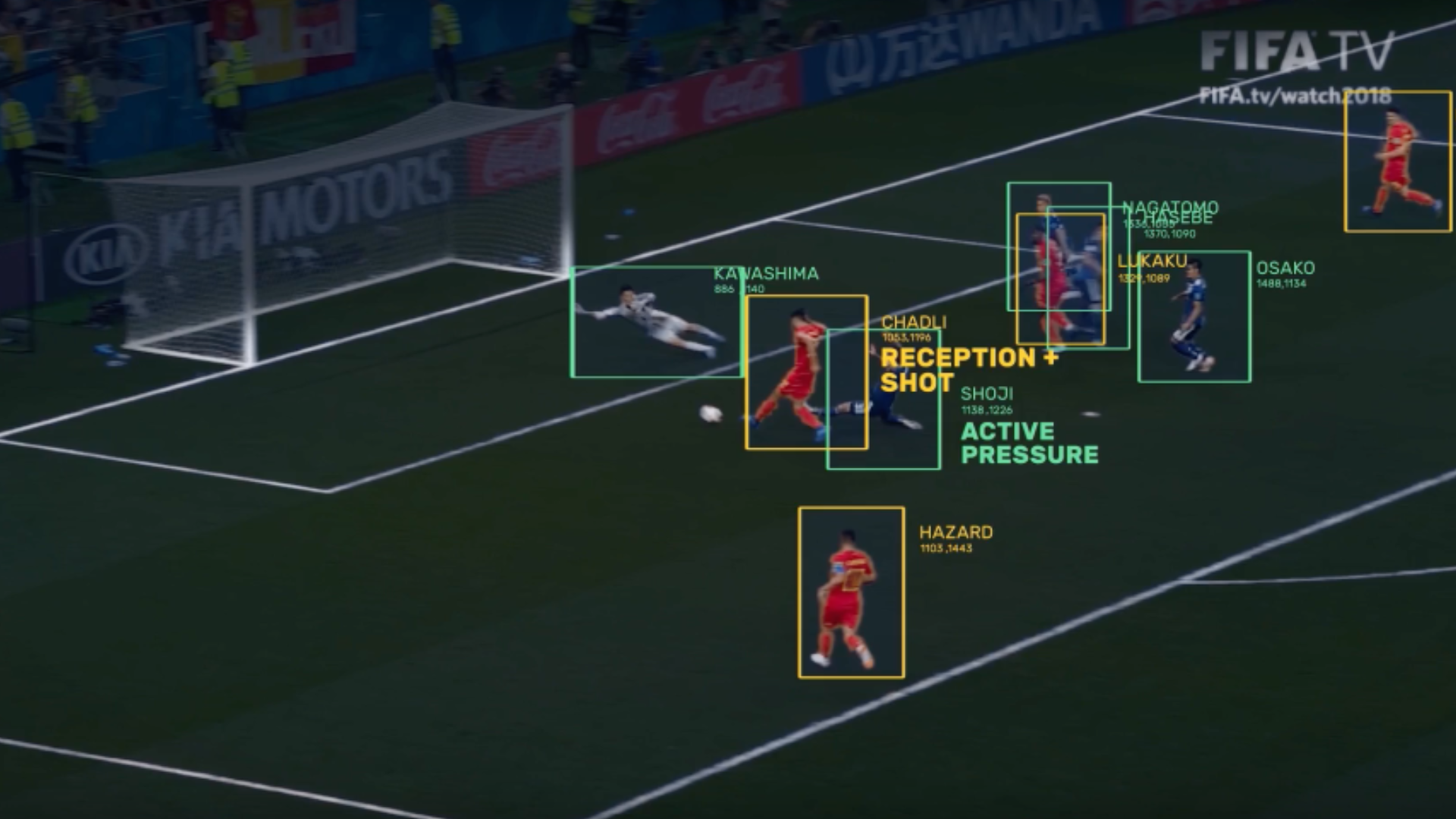
As computer vision AI continues to advance, it will bring more sophisticated analysis, smarter training routines and deeper fan engagement.| Griffon Webstudios
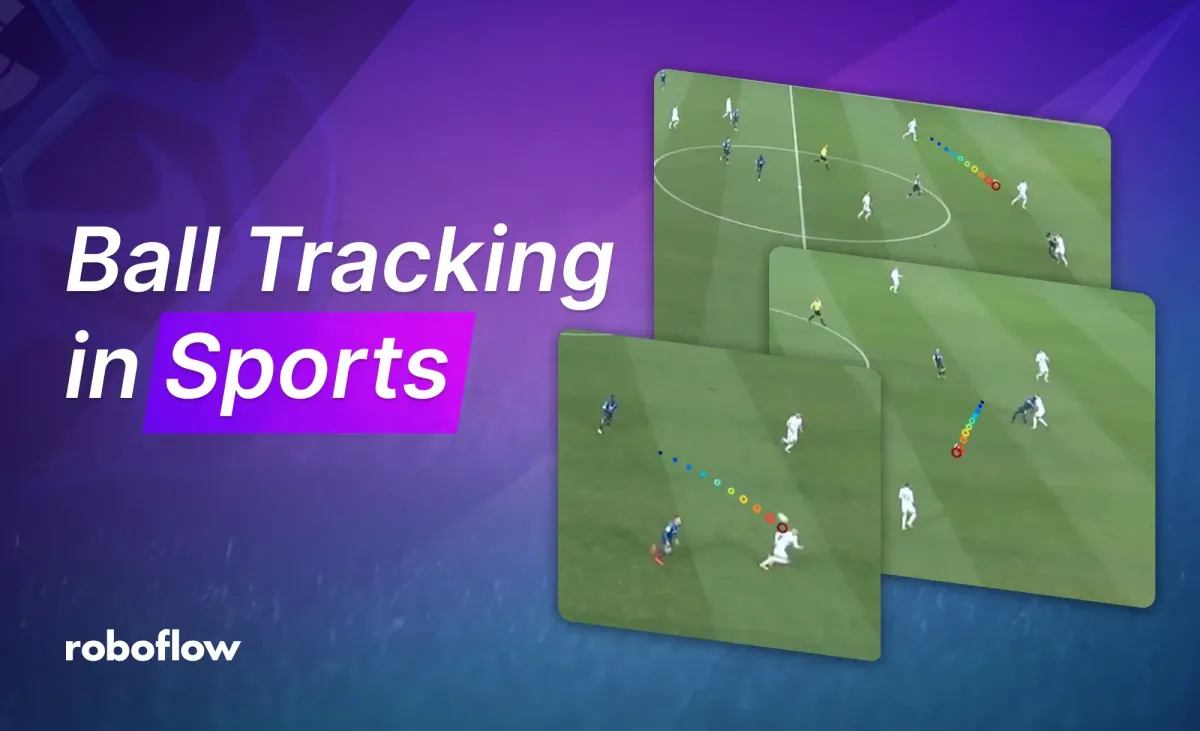
Ball tracking is crucial for AI systems to analyze sports effectively, but it's challenging due to factors like the ball's small size, high velocity, complex backgrounds, similar-looking objects, and varying lighting. This tutorial will teach you how to overcome these challenges.| Roboflow Blog
With modern advancements in artificial intelligence and computational power, computer vision has become an integral part of everyday life. Computers’ ability to ‘see’ and interpret the world around them helps in the analysis of the massive amounts of data created in daily operations.| AI Accelerator Institute
Le passage à l'électrique est aussi l'occasion pour les constructeurs automobiles d'optimiser et moderniser leurs processus industriels. Dans...-Intelligence artificielle| www.usine-digitale.fr
The ability to track moving objects across multiple camera feeds is of immense value to us. From baggage monitoring in busy airports to product tracking in large retail stores, there is a strong case for applications of this nature. In principle, this is simple. The tracking system first detects objects entering a camera’s view and […] The post Multi-Camera Object Tracking Using Custom Association Model appeared first on QBurst Blog.| QBurst Blog
We dive into the world of AI design tools and examine five leading solutions: Canva, Adobe Photoshop, Beautiful.ai, Decktopus, and Midjourney.| TOPBOTS
YOLOv8 object tracking and counting unveils new dimensions in real-time tacking; explore its mastery in our detailed guide, your key to mastering the tech.| LearnOpenCV – Learn OpenCV, PyTorch, Keras, Tensorflow with code, & tutorials
The YOLO (You Only Look Once) series of models, renowned for its real-time object detection capabilities, owes much of its effectiveness to its specialized loss functions. In this article, we delve into the various YOLO loss function integral to YOLO's evolution, focusing on their implementation in PyTorch. Our aim is to provide a clear, technical| LearnOpenCV – Learn OpenCV, PyTorch, Keras, Tensorflow with code, & tutorials
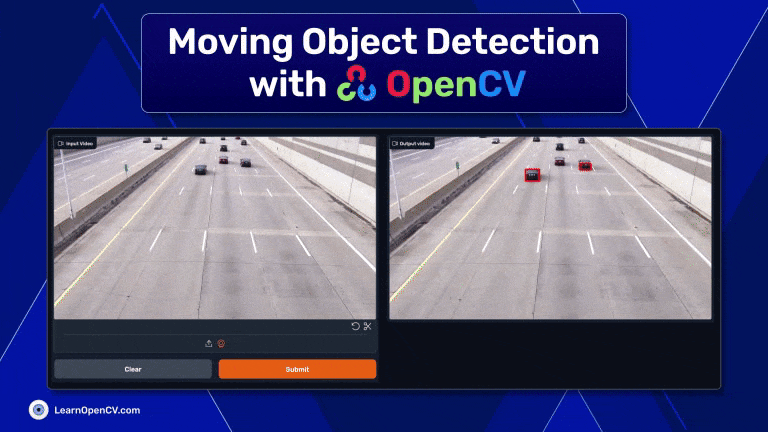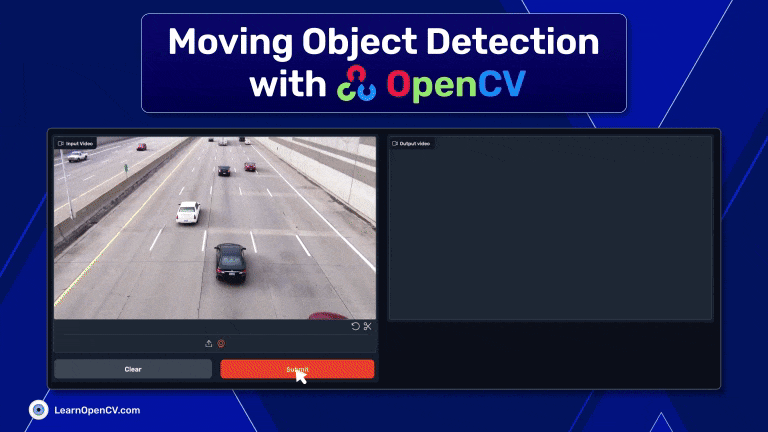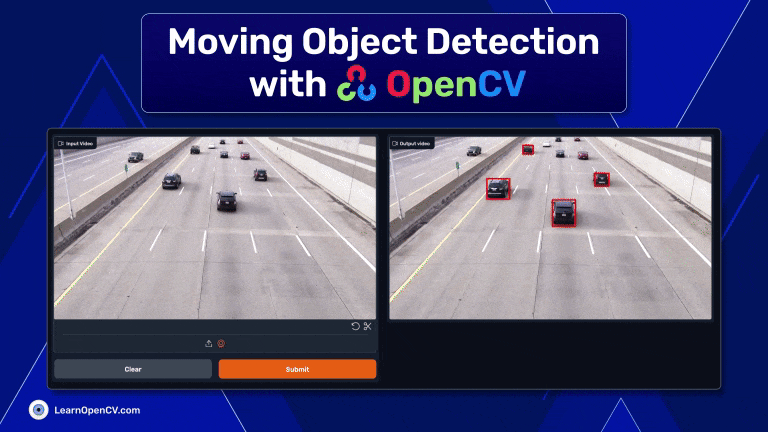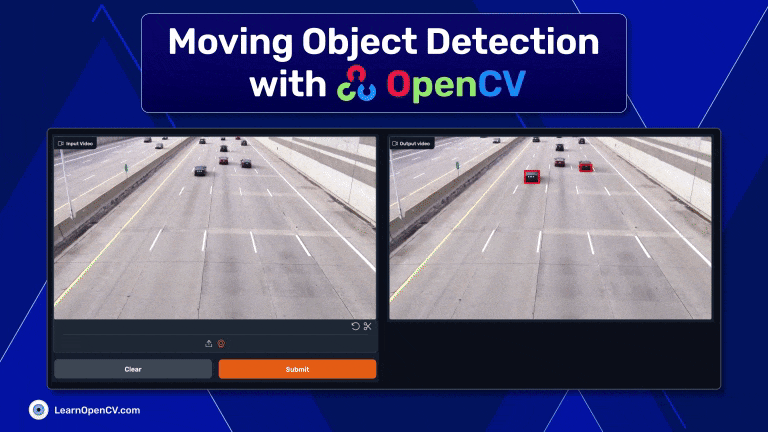
Discover moving object detection using OpenCV, blending contour detection with background subtraction for real-time application in security and traffic.| LearnOpenCV – Learn OpenCV, PyTorch, Keras, Tensorflow with code, & tutorials
My recent experiences with using WebRTC in a mobile application gave me a chance to get familiar with its capabilities and limitations, namely being reliant ...| spieswl.github.io