Da priorità strategica a mandato urgente per i leader aziendali. La fiducia nei dati organizzativi è in crescita, nonostante la persistenza di sfide comuni. La limitazione tecnica maggiore è l'integrazione dei dati (37%). L'aumento del costo della capacità di calcolo per l'addestramento preoccupa il 42% dei leader IT L'articolo Per il 96% dei leader IT, l’AI è almeno parzialmente integrata nei processi aziendali proviene da AI4Business.| AI4Business
Uno strumento decisivo per reti elettriche più resilienti, capaci di manutenzione predittiva, gestione decentralizzata dei guasti e adattamento alla crescente domanda energetica e agli eventi climatici estremi L'articolo AI per l’energia: tra manutenzione predittiva e domanda crescente proviene da AI4Business.| AI4Business
In this article, we'll dive in Tesla's HydraNets, the multi-task learning technique they implement on their Autopilot to run 30+ algorithms in the same network...| Read from the most advanced autonomous tech blog
Discover how Grammarly’s AI-powered communication, personalization, and AI agents are reshaping the future of writing and collaboration.| AI Accelerator Institute
In this article, we create a background replacement application using BiRefNet. We cover the code using Jupyter Notebook and create a Gradio application as well. The post Background Replacement Using BiRefNet appeared first on DebuggerCafe.| DebuggerCafe
In this article, we explore the BiRefNet model for high-resolution dichotomous segmentation. Along with discussing the key elements of the paper, we also create a small background removal codebase usign the pretrained model. The post Introduction to BiRefNet appeared first on DebuggerCafe.| DebuggerCafe
Organizations want to infuse LLMs into every part of their planning and decision making process. This translates to thousands, if not millions of API calls a day. While GPT-4 is great, it’s also prohibitively expensive,... The post Open Source LLMs, Fine-Tunes and RAG Based Vector Store APIs appeared first on The Abacus.AI Blog.| The Abacus.AI Blog
L’AI di nuova generazione, come V-JEPA, riduce la dipendenza da enormi set di dati online, sfruttando le informazioni generate in tempo reale da dispositivi ed edge. Un approccio che migliora efficienza, qualità e automazione nei settori retail, logistica e manifatturiero, affrontando sfide come carenza di personale e necessità di decisioni rapide| AI4Business
All of the quadrupeds we cover have rigid one-piece bodies, which seems to be a good shout for most of the antics they get up to. But a flexible spine might be better in certain climbing situations, and that's where the KLEIYN robodog could shine.| New Atlas
The two Midwest cities are using GIS, artificial intelligence and lidar to make fix accessibility issues with their curb ramps and sidewalks.| StateScoop
Discover how data versioning elevates your pipelines into true AI factories streamlining workflows and boosting team effectiveness with lakeFS.| lakeFS
In this blog post presented on the Character.AI research blog, we explain two techniques that are important for using FlashAttention-3 for inference: in-kernel pre-processing of tensors via warp specialization and query head packing for MQA/GQA.| Colfax Research
In this GPU Mode lecture, Jay Shah presents his joint work on FlashAttention-3 and how to implement the main compute loop in the algorithm using CUTLASS. The code discussed in this lecture can be found at this commit in the FlashAttention-3 codebase. Note: Slides adapted from a talk given by Tri Dao.| Colfax Research
To make AI more human-like, must we sacrifice its power? A new study shows why LLM efficiency creates a gap in understanding. The post Why LLMs don’t think like you: A look at the compression-meaning trade-off first appeared on TechTalks.| TechTalks
In this blog, you would get to know the essential mathematical topics you need to cover to become good at AI & machine learning. These topics are grouped under four core areas including linear algebra, calculus, multivariate calculus and probability theory & statistics. Linear Algebra Linear algebra is arguably the most important mathematical foundation for machine learning. At its core, machine learning is about manipulating large datasets, and linear algebra provides the tools to do this ef...| Analytics Yogi
Building a machine learning model isn’t always as easy as running .fit() and calling it a day. Sometimes, you need to eke out a little more accuracy, because even a 1% improvement can mean a lot to the bottom line. Many machine learning models have a lot of buttons and knobs you can adjust. Changing one value here, tweaking another value there, checking the accuracy one at a time, making sure it’s generalizable and not overfitting… it’s a lot of work to find the right model. Needless ...| SAS Users
Discover what data discovery is, how it works, its benefits, challenges, and best practices to turn raw data into strategic, actionable insights.| Careers at lakeFS: Help Close the Data Infrastructure Gap
In Paris, Jensen Huang laid out how the continent is scaling up with Blackwell-powered factories, agentic AI and sovereign clouds — all part of Europe’s new intelligence infrastructure.| NVIDIA Blog
Last week I spoke at PyData NYC 2023 about “Computational Open Source Economics: The State of the Art”. It was a very nice conference, packed with practical guidance on using Python in machine learning workflows, interesting people, and some talks that were further afield. Mine was the most ‘academic’ talk that I saw there: it […]| Digifesto
I was once long ago asked to write a review of Philip Tetlock’s Expert Political Judgment: How Good Is It? How Can We Know? (2006) and was, like a lot of people, very impressed. If you’re not familiar with the book, the gist is that Tetlock, a psychologist, runs a 20 year study asking everybody […]| Digifesto
Discover what an AI factory is, how it works, and how companies use it to turn raw data into scalable, automated, and intelligent business solutions.| Git for Data - lakeFS
I recently completed another summer internship at Meta (formerly Facebook). I was surprised to learn that one of the intern friends I met was an avid reader of my blog. Encouraged by the positive feedback from my intern friends, I decided to write another post before the end of summer. This post is dedicated to the mandem: Yassir, Amal, Ryan, Elvis, and Sam.| Jake Tae
Recently, I’ve heard a lot about score-based networks. In this post, I will attempt to provide a high-level overview of what scores are and how the concept of score matching gives rise to a family of likelihood-based generative models. This post is heavily adapted from Yang Song’s post on sliced score matching.| Jake Tae
In this post, we will take a look at Flow models, which I’ve been obsessed with while reading papers like Glow-TTS and VITS. This post is heavily based on this lecture video by Pieter Abbeel, as well as the accompanied problem sets for the course, available here.| Jake Tae
In this short post, we will take a look at variational lower bound, also referred to as the evidence lower bound or ELBO for short. While I have referenced ELBO in a previous blog post on VAEs, the proofs and formulations presented in the post seems somewhat overly convoluted in retrospect. One might consider this a gentler, more refined recap on the topic. For the remainder of this post, I will use the terms “variational lower bound” and “ELBO” interchangeably to refer to the same co...| Jake Tae
In this post, we will take a look at Nyström approximation, a technique that I came across in Nyströmformer: A Nyström-based Algorithm for Approximating Self-Attention by Xiong et al. This is yet another interesting paper that seeks to make the self-attention algorithm more efficient down to linear runtime. While there are many intricacies to the Nyström method, the goal of this post is to provide a high level intuition of how the method can be used to approximate large matrices, and how ...| Jake Tae
In this post, we will take a look at relative positional encoding, as introduced in Shaw et al (2018) and refined by Huang et al (2018). This is a topic I meant to explore earlier, but only recently was I able to really force myself to dive into this concept as I started reading about music generation with NLP language models. This is a separate topic for another post of its own, so let’s not get distracted.| Jake Tae
Learn how to build a solid AI infrastructure for efficiently developing and deploying AI and machine learning (ML) applications. Read more.| Git for Data - lakeFS
AI data storage solutions are a key component of the modern AI landscape. Discover benefits, common challenges, and best practices. Read more| Git for Data - lakeFS
AI surrogate models have emerged as powerful tools for accelerating engineering design cycles. They provide fast, data-driven approximations of high-fidelity| Rescale
Learn what metadata is, its types, benefits, and best practices. Discover how metadata improves data governance, compliance, and AI-driven insights.| Git for Data - lakeFS
Unsloth provides memory efficient and fast inference & training of LLMs with support for several models like Meta Llama, Google Gemma, & Phi.| DebuggerCafe
Master N-shot learning to train AI models efficiently with minimal data, from few-shot to zero-shot learning. Revolutionize your data training now!| viso.ai
A deep dive into spectral analysis of diffusion models of images, revealing how they implicitly perform a form of autoregression in the frequency domain.| Sander Dieleman
The noise schedule is a key design parameter for diffusion models. Unfortunately it is a superfluous abstraction that entangles several different model aspects. Do we really need it?| Sander Dieleman
Thoughts on the tension between iterative refinement as the thing that makes diffusion models work, and our continual attempts to make it _less_ iterative.| Sander Dieleman
Perspectives on diffusion, or how diffusion models are autoencoders, deep latent variable models, score function predictors, reverse SDE solvers, flow-based models, RNNs, and autoregressive models, all at once!| Sander Dieleman
Diffusion models have completely taken over generative modelling of perceptual signals -- why is autoregression still the name of the game for language modelling? Can we do anything about that?| Sander Dieleman
Diffusion models have become very popular over the last two years. There is an underappreciated link between diffusion models and autoencoders.| Sander Dieleman
If you have taken a statistics class it may have included stuff like basic measure theory. Lebesgue measures and integrals and their relations to other means of integration. If your course was math heavy (like mine was) it may have included Carathéodory's extension theorem and even basics of operator theory on Hilbert spaces, Fourier transforms etc. Most of this mathematical tooling would be devoted to a proof of one of the most important theorems on which most of statistics is based - centr...| Piekniewski's blog
Statisticians like to insist that correlation should not be confused with causation. Most of us intuitively understand this actually not a very subtle difference. We know that correlation is in many ways weaker than causal relationship. A causal relationship invokes some mechanics, some process by which one process influences another. A mere correlation simply means that two processes just happened to exhibit some relationship, perhaps by chance, perhaps influenced by yet another unobserved p...| Piekniewski's blog
Intro Since many of my posts were mostly critical and arguably somewhat cynical [1], [2], [3], at least over the last 2-3 years, I decided to switch gears a little and let my audience know I'm actually a very constructive, busy building stuff most of the time, while my ranting on the blog is mostly a side project to vent, since above everything I'm allergic to naive hype and nonsense. Nevertheless I've worked in the so called AI/robotics/perception for at least ten years in industry now (an...| Piekniewski's blog
Generative AI language models like ChatGPT are changing the way humans and AI interact and work together, but how do these models actually work? Learn everything you need to know about modern Generative AI for language in this simple guide.| News, Tutorials, AI Research
Emergence can be defined as the sudden appearance of novel behavior. Large Language Models apparently display emergence by suddenly gaining new abilities as they grow. Why does this happen, and what does this mean?| News, Tutorials, AI Research
In what will soon be commonplace in drug research, scientists have used an artificial-intelligence algorithmic program to identify a compound, currently used in antimalarial treatment, that can effectively reverse the bone deterioration of osteoporosis.| New Atlas
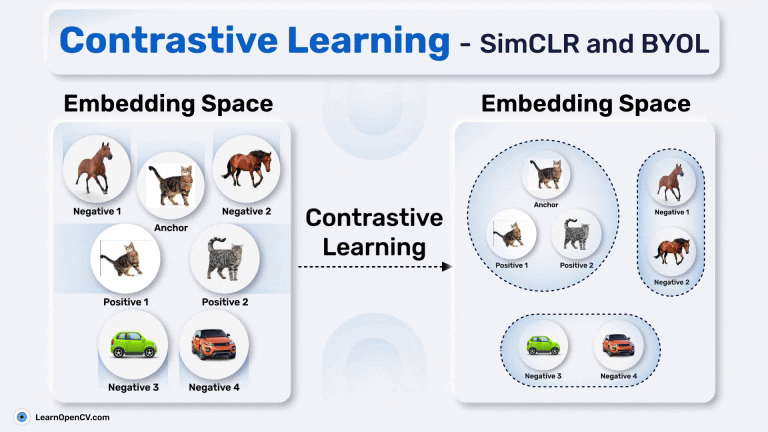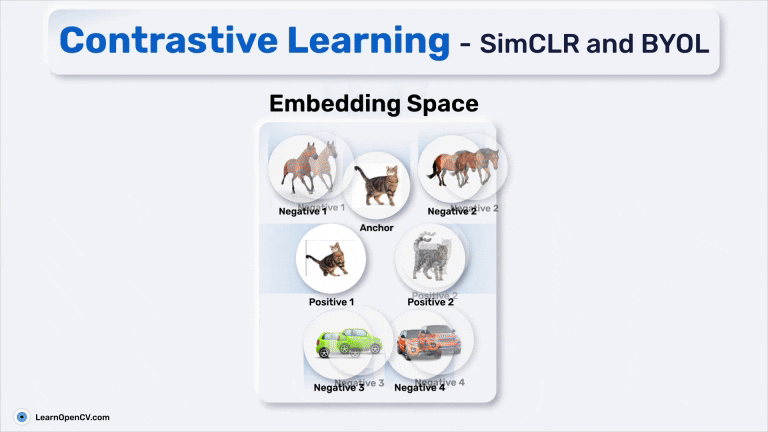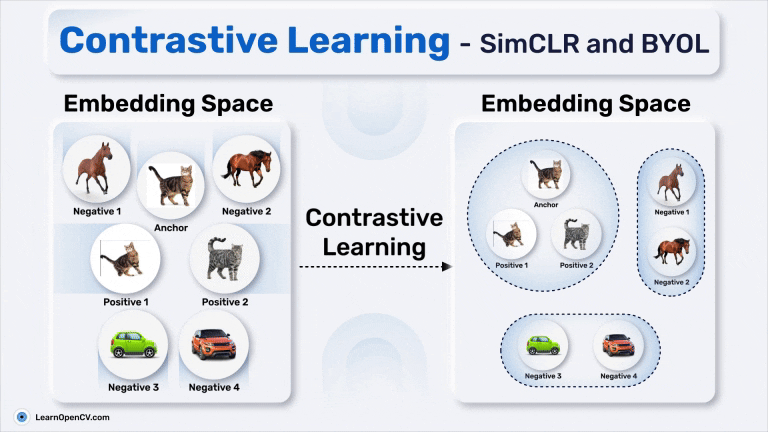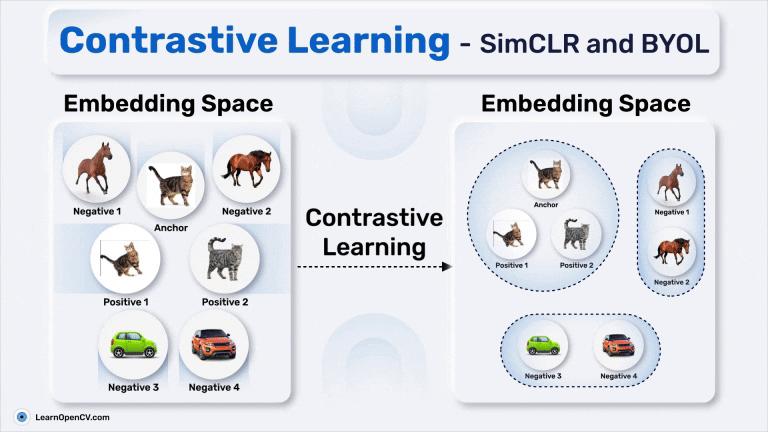
This article explores the history of self-supervised learning, introduces DINO Self-Supervised Learning, and shows how to fine-tune DINO for road segmentation| LearnOpenCV – Learn OpenCV, PyTorch, Keras, Tensorflow with code, & tutorials
Es lässt sich darüber streiten, ob er früher oder später vor Erreichen des Ziels an eine gläserne Decke stoßen wird. Doch es ist kaum zu leugnen, dass mit einem neuen Ansatz rasante Fortschritte in Richtung einer allgemeinen Künstlichen Intelligenz (AGI) erzielt wurden. Diesen Ansatz kennt man unter verschiedenen Namen – bekannt geworden ist er vor […]| TEXperimenTales
Zuerst möchte ich Euch einen poetisch lustigen aber gesunden Rutsch ins Neue wünschen. Gleichzeitig möchte ich mich für Eure Kommentare und Diskussionen in diesem Blog bedanken. Seit viereinhalb Jahren sprechen wir hier über Künstliche Intelligenz, … Der Beitrag Ein Silvester-Text von Künstlicher Intelligenz erschien zuerst auf Gehirn & KI.| Gehirn & KI
Ich wünsche Euch wunderhübsche Weihnachtstage. Diesem Wunsch schließen sich drei “Künstliche Intelligenz”-Modelle an: Die Weihnachtsgeschichte unten wurde von ChatGPT von OpenAI geschrieben (nach meiner englischsprachigen Bitte :-)). Den Text hat der DeepL-Übersetzer aus dem Englischen … Der Beitrag Eine “Künstliche Intelligenz”-Weihnachtsgeschichte erschien zuerst auf Gehirn & KI.| Gehirn & KI
Die Gefahren des Fremden und des Neuen Nach drei Tagen musste Meta (Facebook) sein “Deep Learning”-Sprachmodell Galactica aus dem Verkehr ziehen. Meta hatte Galactica für WissenschaftlerInnen entwickelt, um ihnen die Arbeit zu erleichtern. Das Schönste … Der Beitrag Galactica: Durch die Empörung in den Untergang erschien zuerst auf Gehirn & KI.| Gehirn & KI
Der Traum von einer wissenschaftlichen Revolution In diesem Beitrag mache ich mir Gedanken über Künstliche Intelligenz (KI) und die Kommunikation ihrer Errungenschaften. (Deswegen habe ich hier viele KI-Blogs verlinkt. Es gibt jedoch Tausende davon.) Warum … Der Beitrag Wissenschaft wird spannend – auch KI sei Dank? erschien zuerst auf Gehirn & KI.| Gehirn & KI
In diesem Blogbeitrag erforsche ich ein neues Rätsel der Künstlichen Intelligenz: Können autoregressive Sprachmodelle wie GPT-4, Claude 3 oder Gemini nur in einer Richtung “denken”? So lautet der Fluch der Umkehrung! Diesen Beitrag gibt es …| SciLogs
Tauche ein in die faszinierende Welt der Chatbot Arena! Erlebe spannende Duelle zwischen geheimnisvollen Chatbots und erfahre, ob sie die legendären Modelle wie ChatGPT-4o übertreffen können. Erforsche die neuesten Entwicklungen in der KI und entdecke, welche Plattformen hinter den mysteriösen Bots stecken. Verpasse nicht unsere Magical Mystery Tour durch die Chatbot Arena! 🚀🤖 #Chatbots #KI #Technologie #Innovation #ChatbotArena| Gehirn & KI
The level of computation power guaranteed by the universal approximation theorem is the same as that of look-up tables. It sounds way less impressive when you put it that way. The post The Truth About the [Not So] Universal Approximation Theorem first appeared on Life Is Computation.| Life Is Computation
Large Language Models have been in the limelight since the release of ChatGPT, with new models being announced seemingly every week. This guide walks through the essential ideas of how these models came to be.| News, Tutorials, AI Research
Large Language Models like ChatGPT are trained with Reinforcement Learning From Human Feedback (RLHF) to learn human preferences. Let’s uncover how RLHF works and survey its current strongest limitations.| News, Tutorials, AI Research
Reinforcement Learning from AI Feedback (RLAIF) is a supervision technique that uses a "constitution" to make AI assistants like ChatGPT safer. Learn everything you need to know about RLAIF in this guide.| News, Tutorials, AI Research
This is the story of a summer project that started out of boredom and that evolved into something incredibly fun and unique. It is also the story of how that project went from being discussed on a porch by just two people, to having a community made of almost 700 awesome people (and counting!) that gathered, polished it and made today’s release possible. TL;DR: You can download the 1.0.0 .img file from here, then just follow the instructions. If you want the long version instead, sit back, ...| evilsocket
It’s been a while that i’ve been quite intensively playing with Deep Learning both for work related research and personal projects. More specifically, I’ve been using the Keras framework on top of a TensorFlow backend for all sorts of stuff. From big and complex projects for malware detection, to smaller and simpler experiments about ideas i just wanted to quickly implement and test - it didn’t really matter the scope of the project, I always found myself struggling with the same issu...| evilsocket
What is Word Error Rate and is it a useful measurement of accuracy for speech recognition systems? In this article, we examine the answer to these questions, as well as explore other alternatives to Word Error Rate.| News, Tutorials, AI Research
Speech Recognition models are key in extracting useful information from audio data. Learn how to properly evaluate speech recognition models in this easy-to-follow guide.| News, Tutorials, AI Research
Deep learning teaches computers to do what humans can do - learning by example. It's the driving factor behind things like self-driving cars, allowing them to distinguish between pedestrians and other objects on the road.| AI Accelerator Institute
Le passage à l'électrique est aussi l'occasion pour les constructeurs automobiles d'optimiser et moderniser leurs processus industriels. Dans...-Intelligence artificielle| www.usine-digitale.fr
In this tutorial, you'll look at how learning rate affects ML and DL (Neural Networks) models, as well as which adaptive learning rate methods best optimize| GeekPython - Python Programming Tutorials
In this article, we will be fine tuning the LRASPP MobileNetV3 segmentation model on the KITTI dataset with two different approaches and compare the results.| DebuggerCafe
Diffusion models are a family of state-of-the-art probabilistic generative models that have achieved ground breaking results in a number of fields ranging from image generation to protein structure design. In Part 1 of this two-part series, I will walk through the denoising diffusion probabilistic model (DDPM) as presented by Ho, Jain, and Abbeel (2020). Specifically, we will walk through the model definition, the derivation of the objective function, and the training and sampling algorithms....| Matthew N. Bernstein
We are very pleased that we can once again offer a summer school in ‘Deep Learning for Language Analysis’. The Summer School will take place from 17 to 19 September and there will again be two parallel tracks on processing audio and text data. In the text track this year, the focus is more on […]| TEXperimenTales
We are excited to see Meta release Llama 2, to help further democratize access to LLMs. Making such models more widely available will facilitate efforts across the AI community to benefit the world at large. The post Accelerate Llama 2 with Intel AI Hardware and Software Optimizations appeared first on Intel Gaudi Developers.| Intel Gaudi Developers
The past week was a momentous occasion for protein structure prediction, structural biology at large, and in due time, may prove to be so for the whole of life sciences. CASP14, the conference for …| Some Thoughts on a Mysterious Universe
But it may well be semi-supervised. For some time now I have thought that building a latent representation of protein sequence space is a really good idea, both because we have far more sequences than any form of labelled data, and because, once built, such a representation can inform a broad range of downstream tasks. … Continue reading →| Some Thoughts on a Mysterious Universe
For over a decade now I have been working, essentially off the grid, on protein folding. I started thinking about the problem during my undergraduate years and actively working on it from the very beginning of grad school. For about four years, during the late 2000s, I pursued a radically different approach (to what was … Continue reading →| Some Thoughts on a Mysterious Universe
Normalizing Flows [Rezende and Mohamed 2015] are powerful density estimators that have shown to be able to learn complex distributions, e.g., of natural images [Kingma and Dhariwal 2018].| Sven Elflein
This is a blog post about the paper “Restricting the Flow: Information Bottlenecks for Attribution” by Karl Schulz, Leon Sixt, Federico Tombari and Tim Landgraf published at ICLR 2020. Introduction With the current trend to applying Neural Networks to more and more domains, the question on the explainability of these models is getting more attention. While more traditional machine learning approaches like decision trees and Random Forest incorporate some kind of interpretability based on ...| Sven Elflein