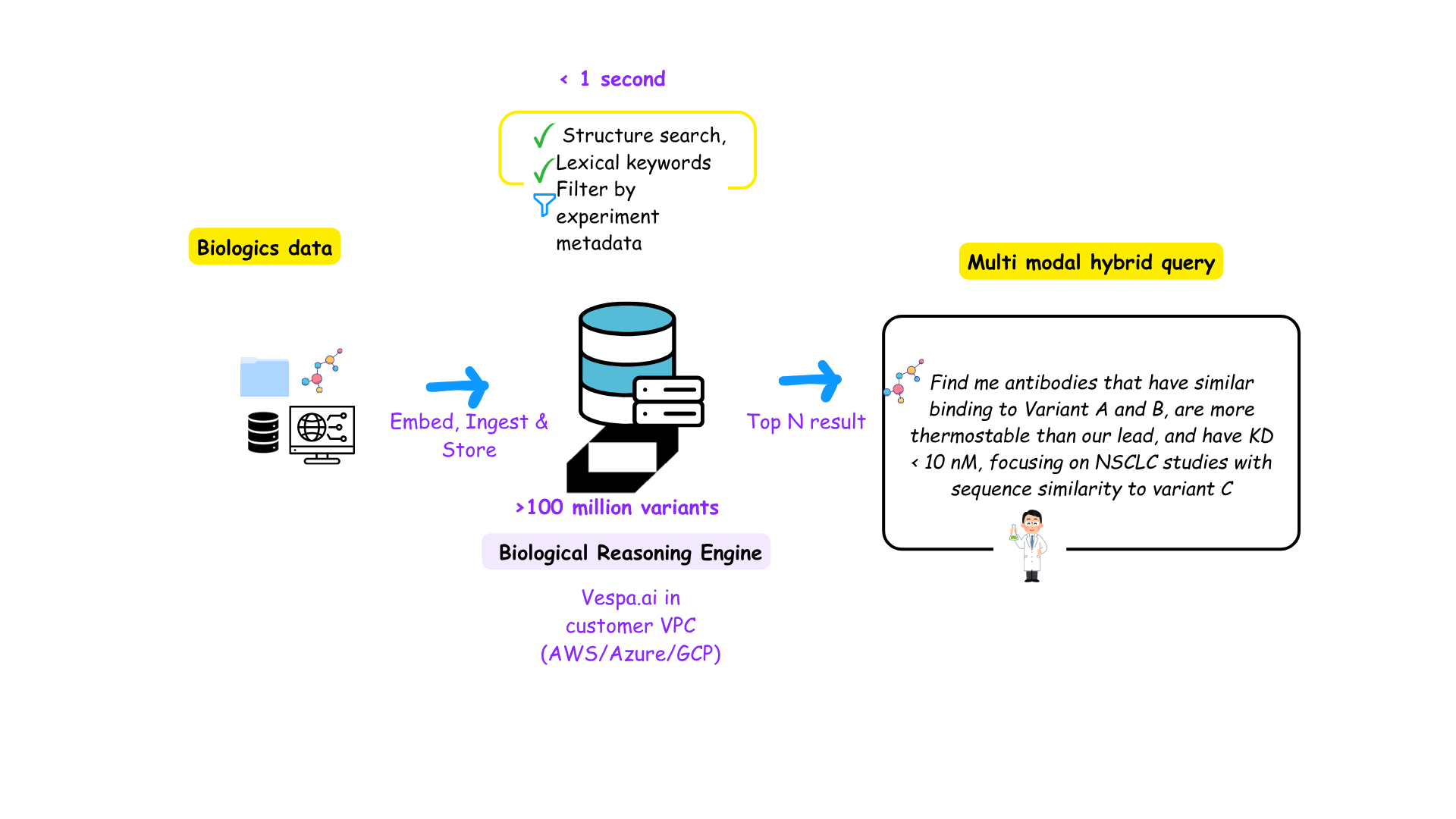
Protein models Need a PLM Store: Turning Model Outputs into Searchable Biological Intelligence- beyond LLM's | Vespa Blog
A story about bridging AI models, LIMS data, and real-world biologics discovery.| Vespa Blog
A story about bridging AI models, LIMS data, and real-world biologics discovery.| Vespa Blog
Master enterprise RAG system security with practical examples for authentication, data governance, and compliance. Includes Kubernetes configs and Python code.| Collabnix
If you’ve built a “Naive” RAG pipeline, you’ve probably hit a wall. You’ve indexed your documents, but the answers are… mediocre. They’re out of context, they miss the point, or they just feel wrong. Here’s the truth: Your RAG system is only as good as its chunks. Chunking—the process of breaking your documents into searchable pieces—is one of the most important decision you will make in your RAG pipeline. It’s not just “preprocessing”; it is the foundation of your A...| Analytics Yogi
Master document processing for RAG systems with practical examples, code snippets, and best practices. Learn chunking strategies, embedding optimization, and production deployment.| Collabnix
En los últimos meses, la adopción de la Inteligencia Artificial Generativa se ha acelerado de forma exponencial gracias a la integración con datos corporativos mediante la Generación Aumentada por Recuperación,|
The rise of generative AI has created exciting new possibilities for organizations, but one consistent challenge remains: how to effectively integrate enterprise knowledge into AI systems. Training or fine-tuning large language models with proprietary information is often prohibitively expensive. That’s why Retrieval Augmented Generation (RAG) has emerged as a popular and cost-effective solution. What is [...] The post Retrieval Can Be the Hardest Part of RAG Solutions appeared first on Ver...| Verinext

cRAiG implements RAG pipelines that offers an OpenAI‑compatible API for secure, privacy‑first AI generation. It integrates seamlessly with existing systems and ensures reliable, scalable query handling across on‑prem or cloud environments.| ConSol Blog
LLMの実用性を高めるための手段としてRAGは注目されています。 しかし、RAGにおいてモデルに渡すべき情報は、実は使用するLLMによって異なる可能性があります。 本記事では、この「LLMによって異なる”情報の有用性”」 […] The post RAGで取得すべき情報はLLMごとの「データの有用性」で異なる first appeared on AIDB.| AIDB
本記事では、RAG(Retrieval-Augmented Generation)の仕組みと役割、そして今もなお注目されている理由を紹介します。最近のLLMは大幅に進化し、昔と比べて多くの問いに正確に答えられるようになっ […] The post LLM自体の性能が飛躍的に向上した今、RAGに求められることとは first appeared on AIDB.| AIDB

Kako modeli postaju sve precizniji, a količina poslovnih podataka sve veća, logično je očekivati AI koji će davati odgovore isključivo na temelju stvarnih i ažurnih podataka. Sve drugo je prevelik rizik. Stoga RAG postaje standard, objašnjava tech lead iz Factoryja.| Netokracija
Perplexity demonstrates the quality of their search solution and show what it takes to achieve it| Vespa Blog

This post introduces techniques that probe the LLM’s internal confidence and knowledge boundaries. We explore prompt-based confidence detection, consistency-based uncertainty estimation, and internal state analysis approaches to determine when retrieval is truly necessary.| Sumit's Diary
Building AI applications that can interact with private data is a common goal for many organizations. The challenge often lies in connecting large language models (LLMs) with proprietary datasets. A combination of Heroku Managed Inference and Agents and LlamaIndex provides an elegant stack for this purpose. This post explores how to use these tools to build retrieval-augmented generation (RAG) applications. We'll cover the technical components, Use Cases and the development process, and how t...| Heroku
The rise of generative AI has created exciting new possibilities for organizations, but one consistent challenge remains: how to effectively integrate enterprise knowledge into AI systems. Training or fine-tuning large language models with proprietary information is often prohibitively expensive. That’s why Retrieval Augmented Generation (RAG) has emerged as a popular and cost-effective solution. What is [...] The post Retrieval Can Be the Hardest Part of RAG Solutions appeared first on For...| Forty8Fifty Labs
In our previous article, we explored how full-text search can stumble on long, natural-language prompts and how hybrid approaches—combining full-text, trigram, and semantic search—can restore relevance. But building a search engine that “works” is only the beginning. In this follow-up, we enter the Age of Refinement. Learning how to evaluate and optimize search performance for MCP systems. from practical tuning of full-text search strategies for improving semantic search, and, most im...| bitcrowd blog Blog

Building on part 1’s exploration of naive RAG’s limitations, this post introduces adaptive retrieval frameworks and pre-generation retrieval decision-making methods that determine if retrieval is truly necessary.| Sumit's Diary
We built our own reranker that outperforms Cohere Rerank v3.5, an industry-leading commercial solution. This improved our answer quality, reduced reranking costs by 80%, and gained more flexibility to evolve our system. The post How We Built a World-Class Reranker for Fin appeared first on /research.| /research
Good answers start with good context. Our AI agents use retrieval-augmented generation (RAG) to find the right context for a user’s query. RAG retrieves top passages from a knowledge base, then uses them to generate an… The post Using LLMs as a Reranker for RAG: A Practical Guide appeared first on /research.| /research
At Intercom, we’ve built Fin, an AI-powered support bot designed to understand users’ issues and answer their questions accurately. To do this, Fin relies on state-of-the-art large language models (LLMs). However, even the most advanced LLMs… The post Finetuning Retrieval for Fin appeared first on /research.| /research

Retrieval-Augmented Generation (RAG) isn’t a silver bullet. This post highlights the hidden costs associated with RAG and makes the case for a smarter, adaptive approach.| Sumit's Diary
Authors: Lara Rachidi & Maria Zervou Introduction Welcome to our technical blog on the challenges encountered when building and deploying Retrieval-Augmented Generation (RAG) applications. RAG is a GenAI technique used to incorporate relevant data as context to a large language model (LLM) without t...| community.databricks.com

Modern applications rely on PostgreSQL for its fully ACID‑compliant, expressive SQL, and rich ecosystem of extensions. The database handles relational workloads exceptionally well, but many projects also need to search for large text collections—prod...| VectorChord

Delve into the future of content transformation with AI, including IBM Watson Assistant, and its impact on industries.| Govindhtech

At PrestoCon Day 2025, Satej Sahu (Principal Data Engineer at Zalando SE) introduced the Self-Healing Query Connector for Presto, an AI-powered upgrade| PrestoDB

In this post we will dive into each component practically, providing a step-by-step instructions for building and implementing an entire RAG pipeline.| CustomGPT
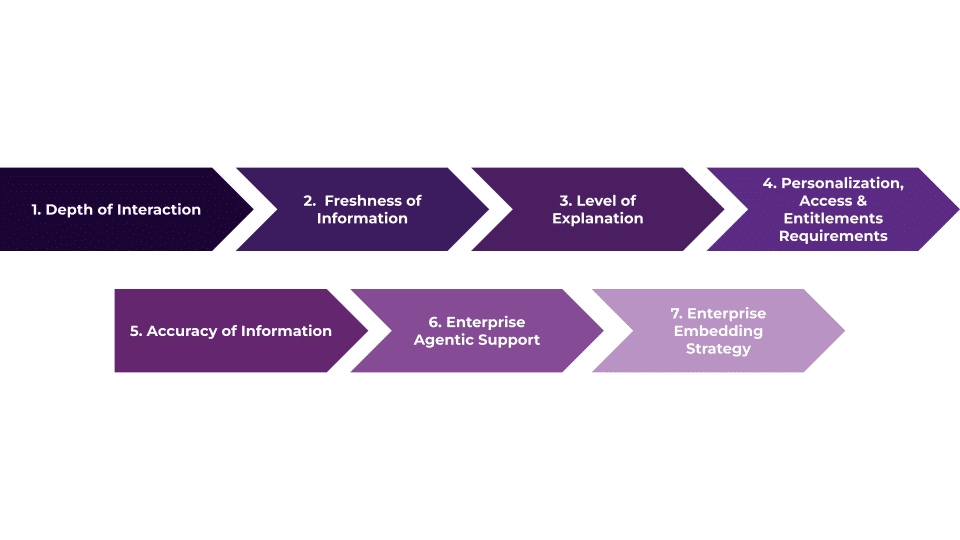
EK’s approach to evaluating and roadmapping an LLM solution from PoC to production-scaling an LLM-based enterprise solution.| Enterprise Knowledge

In this post, I’ll share key insights and findings from building a practical text search application without using frameworks like LangChain or external APIs. I’ve also extended the app’s functionality to support Retrieval-Augmented Generation (RAG) capabilities using the Gemini Flash 1.5B model.| amritpandey.io

Learn how graph databases and knowledge graphs can transform your RAG system from guessing to intelligent reasoning with structured data.| Seuros Blog

Enterprise use cases examining how CustomGPT.ai's Retrieval-Augmented Generation (RAG) technology can assist in a wide variety of applications| CustomGPT

Most AI failures aren’t model issues—they’re data issues. Learn how grounding and RAG can turn your LLM into a reliable, enterprise-ready system.| Polymer

Six months have passed since our last year-end review. As the initial wave of excitement sparked by DeepSeek earlier this year begins to wane, AI seems to have entered a phase of stagnation. This pattern is evident in Retrieval-Augmented Generation (RAG) as well: although academic papers on RAG continue to be plentiful, significant breakthroughs have been few and far between in recent months. Likewise, recent iterations of RAGFlow have focused on incremental improvements rather than major fea...| ragflow.io
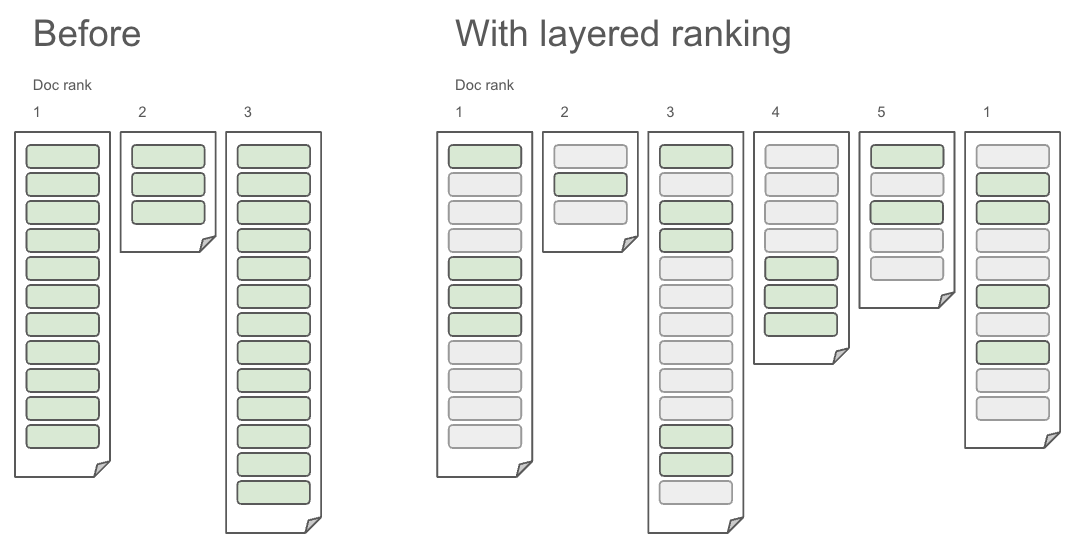
Introducing layered ranking: The missing piece for context engineering at scale.| Vespa Blog
Ende Jahr hatten wir unser erstes Event: Meet ora2know in Köln. Und wir waren positiv überrascht: Knapp 40 Teilnehmer sorgten für ein volles Haus und viele Diskussionen rund um die […] The post Rückblick: meet ora2know in Köln am 29.01.2025 first appeared on The German Oracle User Group.| The German Oracle User Group
Most text search solutions are fine tuned to serve results for keyword style queries. This is a problem in the age of MCP, as comparably long user input hits the same old pg_trgm search| bitcrowd blog Blog
It is now the age of RAG, semantic + hybrid search, domain reasoning, powering copilots and AI agents. Lets see how - lets build your next Scientific Search engine!| Vespa Blog
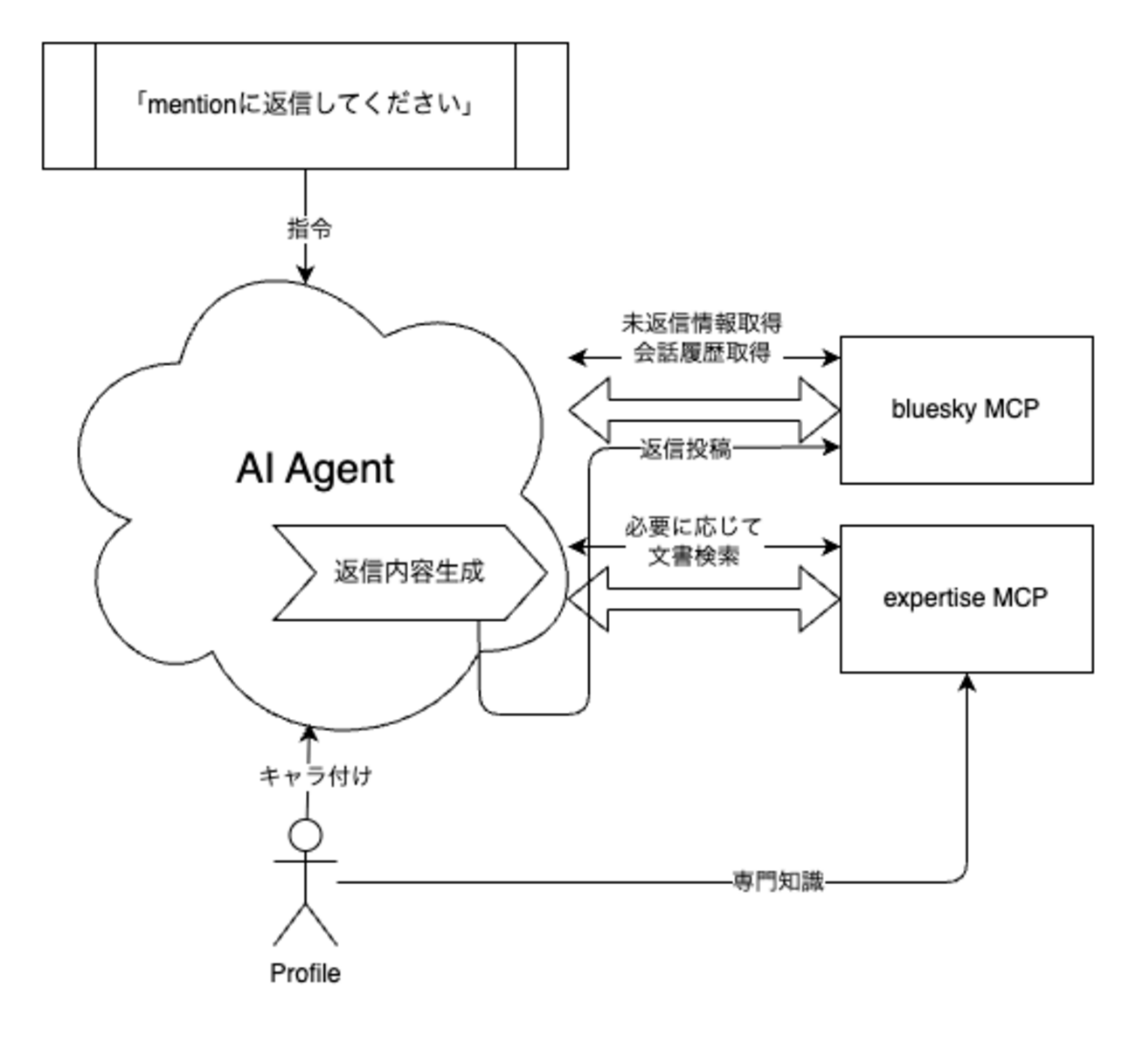
Bluesky MCP serverを自作し、SNS上に架空の友達を作る - すぎゃーんメモ の記事の続き。 「今後の課題」として挙げていた: 一番どうにかしたいのは、知識について。 プロフィールに書いたことしかインプットされないのでやはり偏りがあるし専門知識が足りない。 プリキュア全シリーズ好きなはずなのにひたすらスマプリのことばかり呟いてしまうし、最新作のキミプリ...| すぎゃーんメモ

A RAG system combines an information retrieval engine (e.g., a search or vector database) with a generative LLM.| Apiumhub
This time, we (almost) take a break from AI and look at five code efficiency hacks that might change your life.| bitcrowd blog Blog
A RAG-powered chatbot lets a supplement company: answer clinician-level questions without violating DSHEA; surface up-to-date research as proof-points; convert curious browsers into confident subscribers—24/7. The post The RAG Advantage: Why Health-Supplement Brands Need a Retrieval-Augmented AI Chatbot—Not Just “Another” Bot appeared first on XPathMedia.| XPathMedia

In my previous article, I discussed how Helidon integrates with LangChain4J. While the article provided a solid foundation, some readers pointed out the lack of a complete, hands-on example. This t…| Dmitry's Technical Blog
Learn how how Vespa’s native tensor capabilities are redefining AI-powered search and retrieval in life sciences, enabling faster, more accurate insights across complex, multimodal scientific data.| Vespa Blog

Example of an end-to-end implementation of an agentic retail chatbot assistant that provides an advanced conversational search experience through an agentic workflow encapsulating tool usage.| Vespa Blog

This article aims to explore how RAG enhances transparency, reliability, and trust within in AI, and particularly within CustomGPT.ai.| CustomGPT
In this blog, we have a ongoing series of posts [about the uses and the technicalities of RAG](https://bitcrowd.dev/tags/rag), especially in the context of coding and Elixir. However, we discovered that many readers did not find the time to setup their own RAG system. To make this more accessible, we launched [exmeralda.chat](https://exmeralda.chat). It's a chatbot for Hex packages that we host for the community.| bitcrowd blog Blog

AI search requires more than a vector database. A search platform bridges the gaps.| Vespa Blog
Perplexity chose to build on Vespa.ai to provide the world’s most used RAG application.| Vespa Blog

Welcome to the second part of our series on Codeium Windsurf. If you haven't yet, check out Part 1 to get detailed insights into what Windsurf is and the features it brings to your coding environment. In this section, we'll explore how you can leverage Codeium Windsurf's features to accelerate your coding projects using real code examples.| Keyhole Software

As AI agents take on greater autonomy, threat actors find new ways to exploit them. Learn the risks of AI agent hijacking and how to defend.| Polymer
This article will teach you how to create a Spring Boot application that implements several AI scenarios using Spring AI and the Ollama tool. Ollama is an open-source tool that aims to run open LLMs on our local machine. It acts like a bridge between LLM and a workstation, providing an API layer on top […] The post Using Ollama with Spring AI appeared first on Piotr's TechBlog.| Piotr's TechBlog

Windsurf Series Introduction This is Part 1 of a 2-part blog series. In Part 1, you’ll learn: How to go from 10x to 100x productivity using the AI-assisted coding tool Windsurf What Windsurf is and how it enhances your IDE with Retrieval-Augmented Generation (RAG) Best practices for using features like Autocomplete, Supercomplete, Chat, Command, and Cascade How context-aware code generation can save time and reduce errors Tips to get the most out of Windsurf without falling into common pitf...| Keyhole Software
An introduction to `rag`, a RAG library for Elixir.| bitcrowd blog Blog

Learn how the next wave of generative AI is transforming operations and discover how to secure AI workflows.| Polymer
Find out how you can implement a local RAG system in Elixir.| bitcrowd blog Blog
Using a RAG information system for your team's codebase. Find out how the LLM can read and understand Elixir code and start a conversation about your codebase with the LLM.| bitcrowd blog Blog
Using a RAG (Retrieval Augmented Generation) information system for source code. Find out how a simple RAG system can empower your development team.| bitcrowd blog Blog
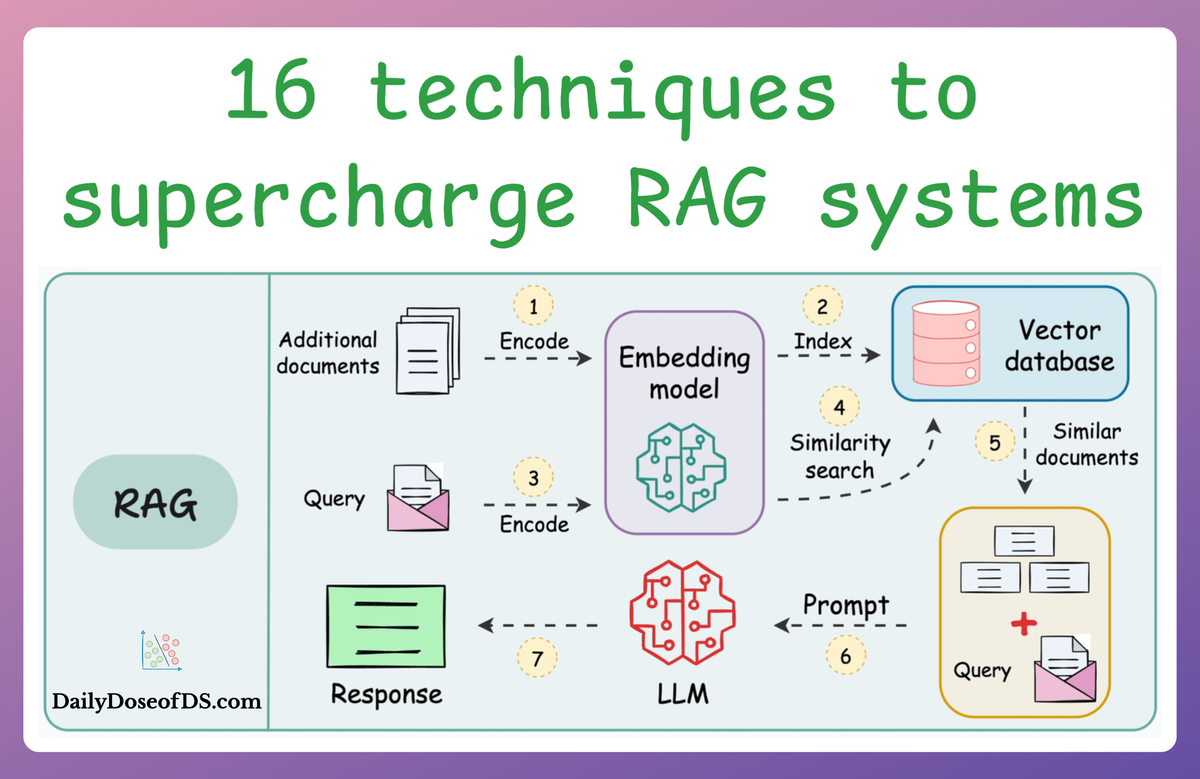
A comprehensive guide with practical tips on building robust RAG solutions.| Daily Dose of Data Science
RAG promises to revolutionize AI-driven insights, but with the rise of data breaches, can your organization afford the risks? Discover how to secure your RAG implementation.| Polymer
This chapter was all about RAG and agents. It’s only 50 pages, so clearly there’s only so much of the details she can get into, but it was pretty good nonetheless and there were a few things in here I’d never really read. Also Chip does a good job bringing the RAG story into the story about agents, particularly in terms of how she defines agents. (Note that the second half of this chapter, on agents, is available on Chip’s blog as a free excerpt!) As always, what follows is just my no...| Alex Strick van Linschoten
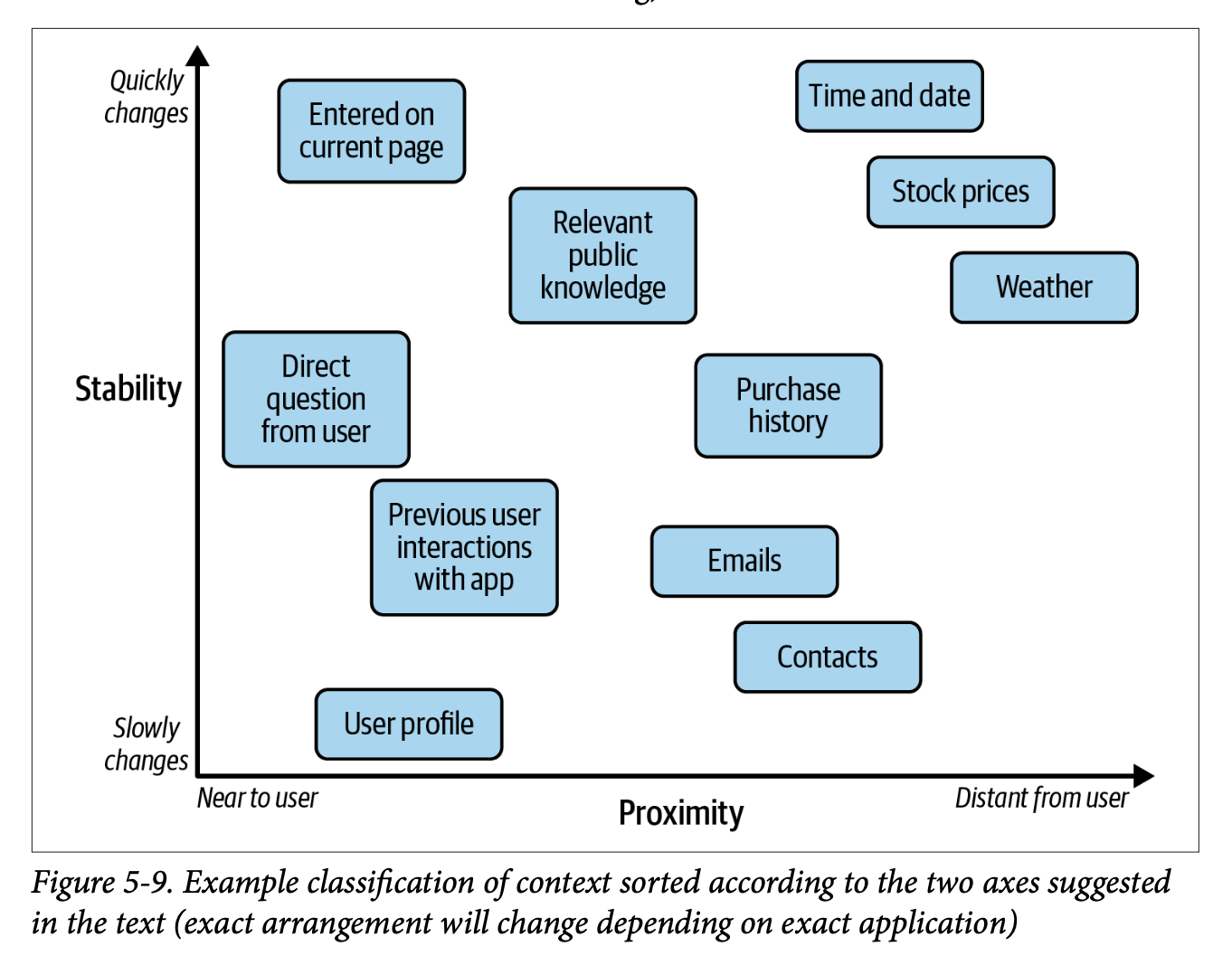
Chapter 5 of 'Prompt Engineering for LLMs' explores static content (fixed instructions and few-shot examples) versus dynamic content (runtime-assembled context like RAG) in prompts, offering…| mlops.systems

RAG allows you to input your data and get accurate, contextually relevant answers based entirely on the information you provide.| Apiumhub
A deep dive into ColBERT and ColBERTv2 for improving RAG systems (with implementation).| Daily Dose of Data Science

Fed up with AI that makes up facts and can't keep up with your latest data? That's where RAG (Retrieval-Augmented Generation) comes in – the clever technique that's changing how we build AI applications that actually work.| iO tech_hub
A deep dive into Graph RAG and how it improves traditional RAG systems (with implementation).| Daily Dose of Data Science
A deep dive into building multimodal RAG systems on real-world data (with implementation).| Daily Dose of Data Science
As 2024 comes to a close, the development of Retrieval-Augmented Generation (RAG) has been nothing short of turbulent. Let's take a comprehensive look back at the year's progress from various perspectives.| RAGFlow Blog
The final release of RAGFlow for the year of 2024, v0.15.0, has just been released, bringing the following key updates:| ragflow.io

¿Cansado de escribir SQL a mano? ¿Se complica pedir ayuda a la IA de turno por falta de contexto? Este post te podría interesar!| 10Pines | Blog
A deep dive into key components of multimodal systems—CLIP embeddings, multimodal prompting, and tool calling.| Daily Dose of Data Science
A deep dive into handling multiple data types in RAG systems (with implementations).| Daily Dose of Data Science
Infinity is a database specifically designed for Retrieval-Augmented Generation (RAG), excelling in both functionality and performance. It provides high-performance capabilities for dense and sparse vector searches, as well as full-text searches, along with efficient range filtering for these data types. Additionally, it features tensor-based reranking, enabling the implementation of powerful multi-modal RAG and integrating ranking capabilities comparable to Cross Encoders.| ragflow.io
Quick Summary GraphRAG is RAG where the retrieval path utilizes a knowledge graph. It improves the comprehensiveness and diversity of answers compared to RAG...| vitalab.github.io
A deep dive into making RAG systems faster (with implementations).| Daily Dose of Data Science
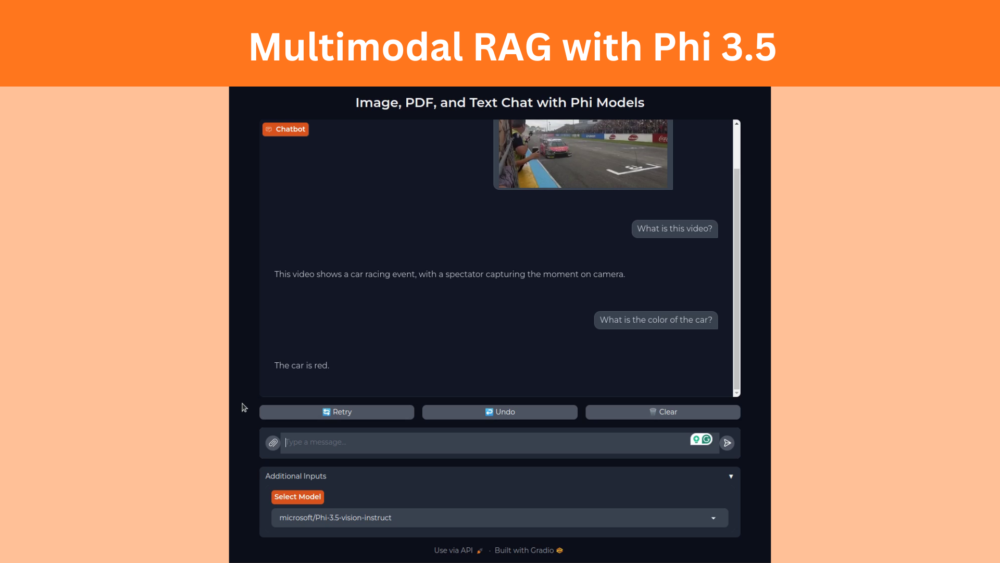
Multimodal RAG Chat application to chat with PDFs, text files, images, and videos using Phi-3.5 family of language models.| DebuggerCafe
A deep dive into evaluating RAG systems (with implementations).| Daily Dose of Data Science
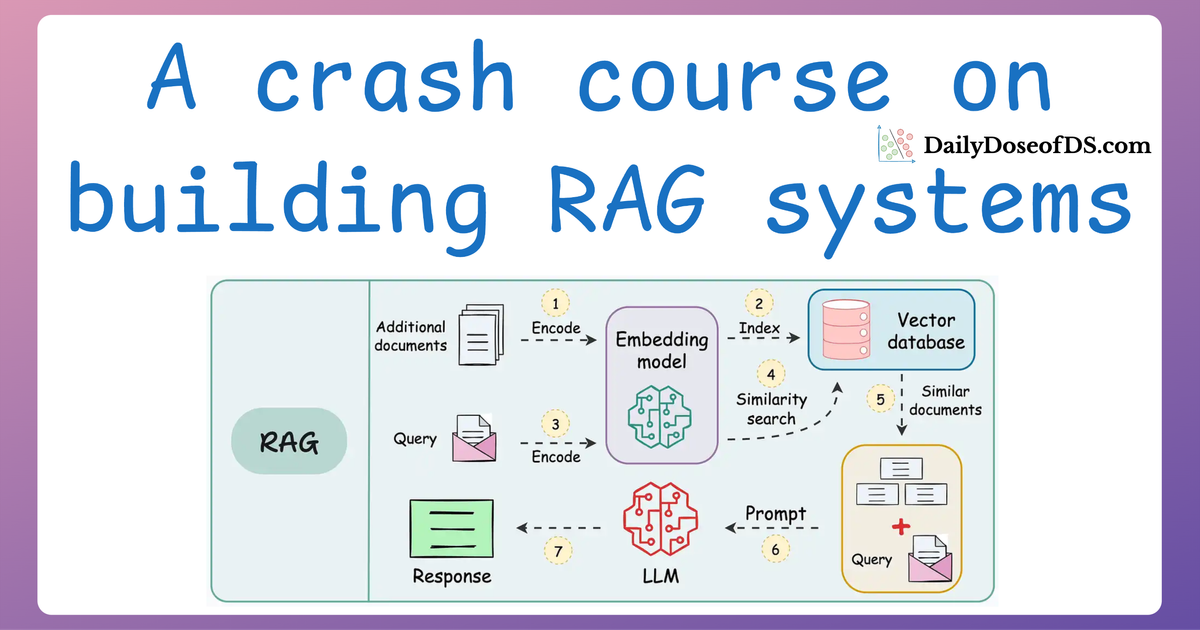
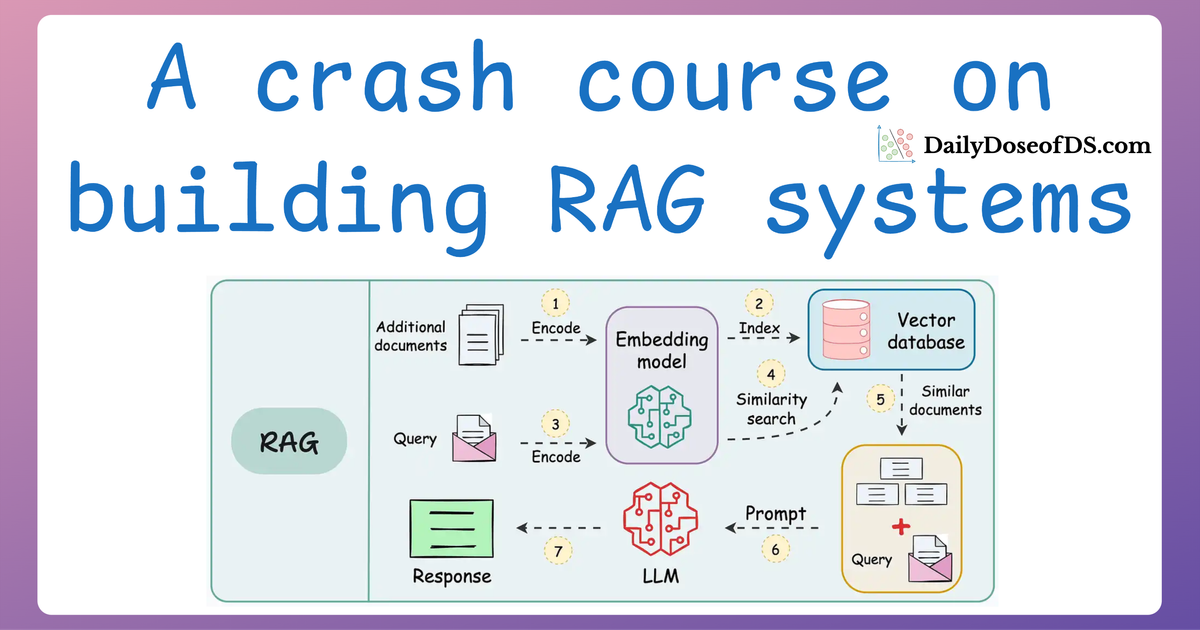
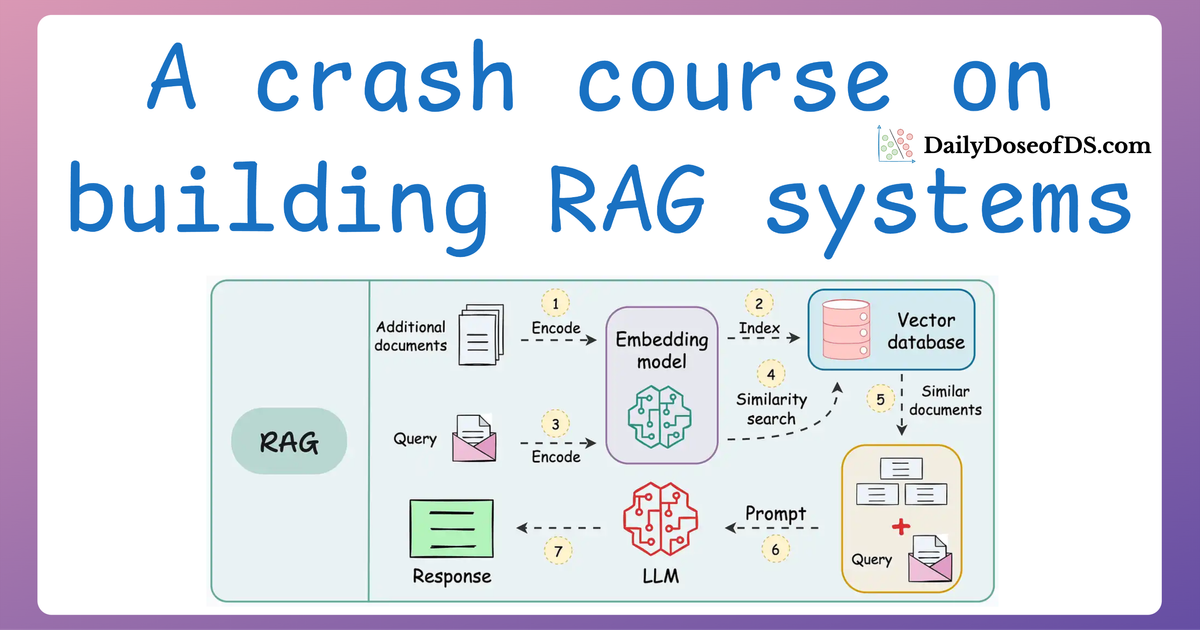
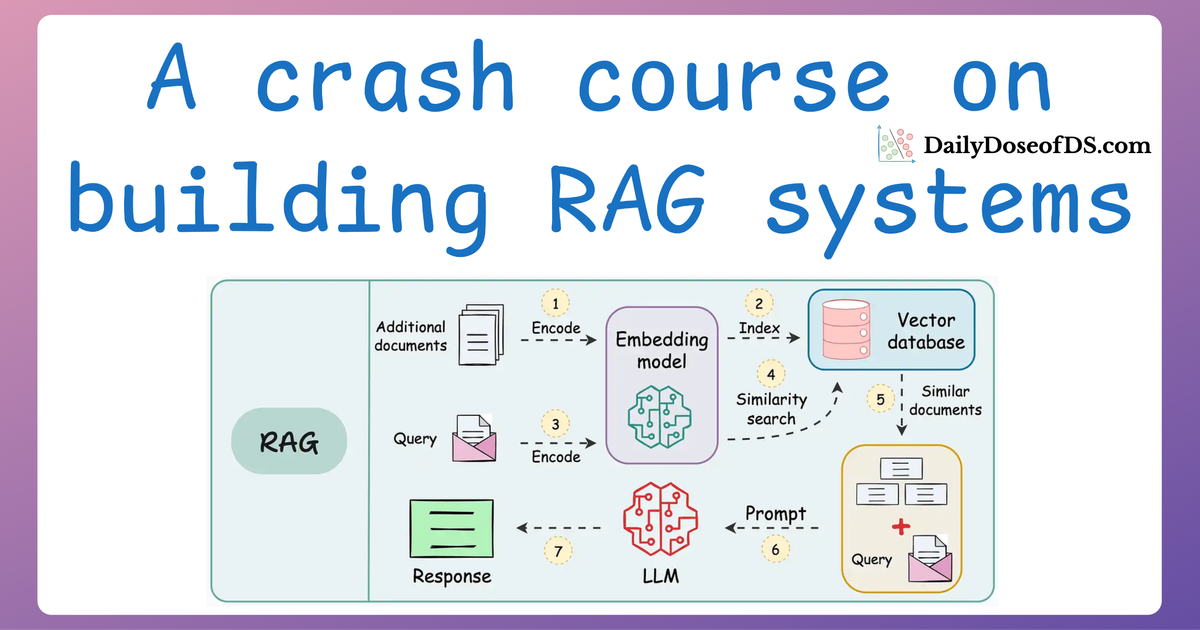
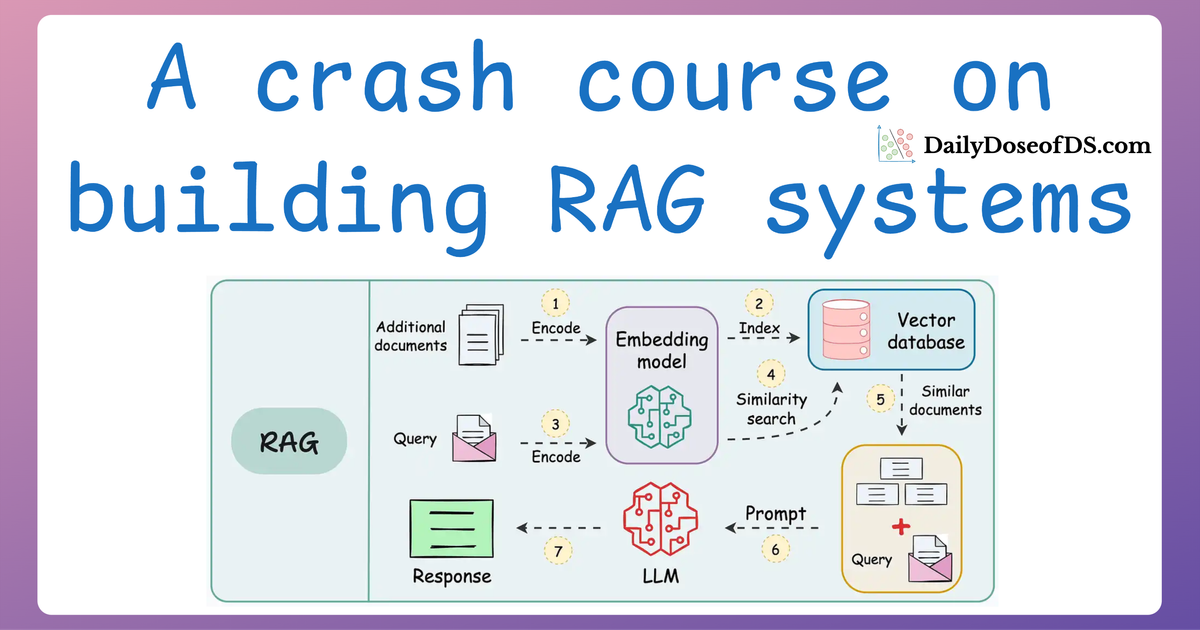
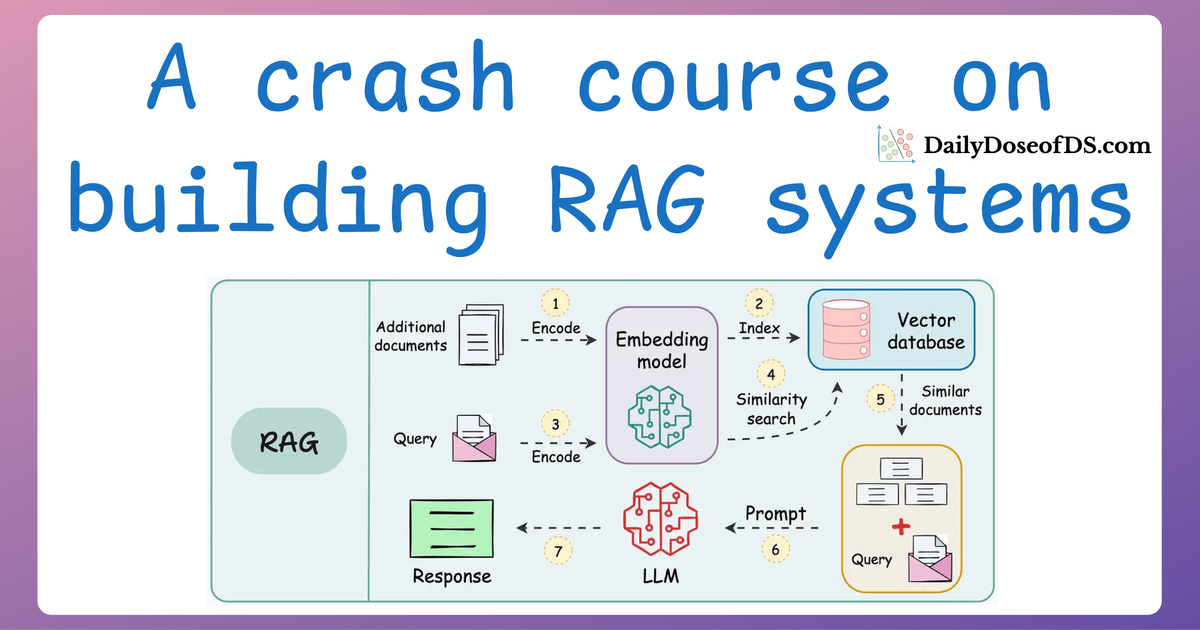
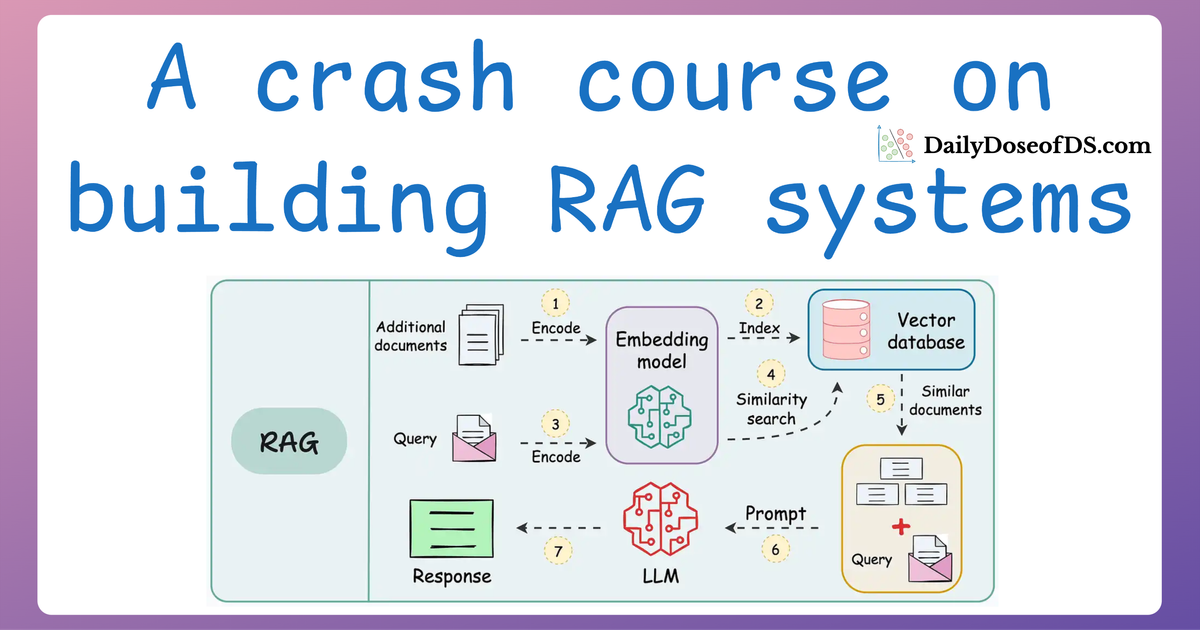
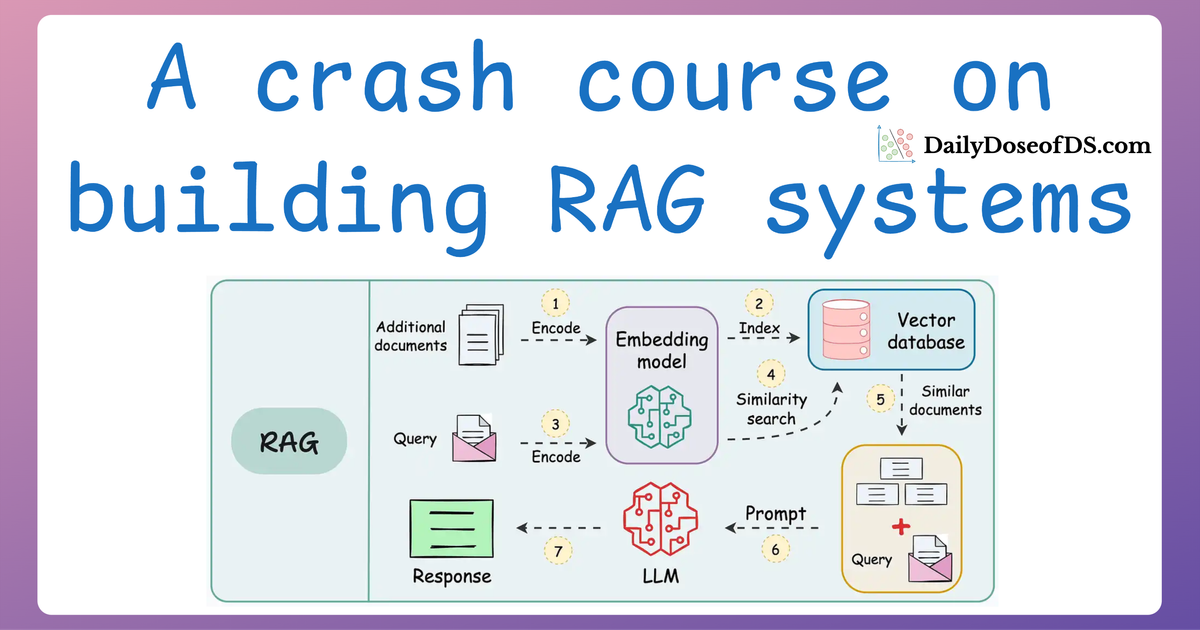
A practical and beginner-friendly crash course on building RAG apps (with implementations).| Daily Dose of Data Science
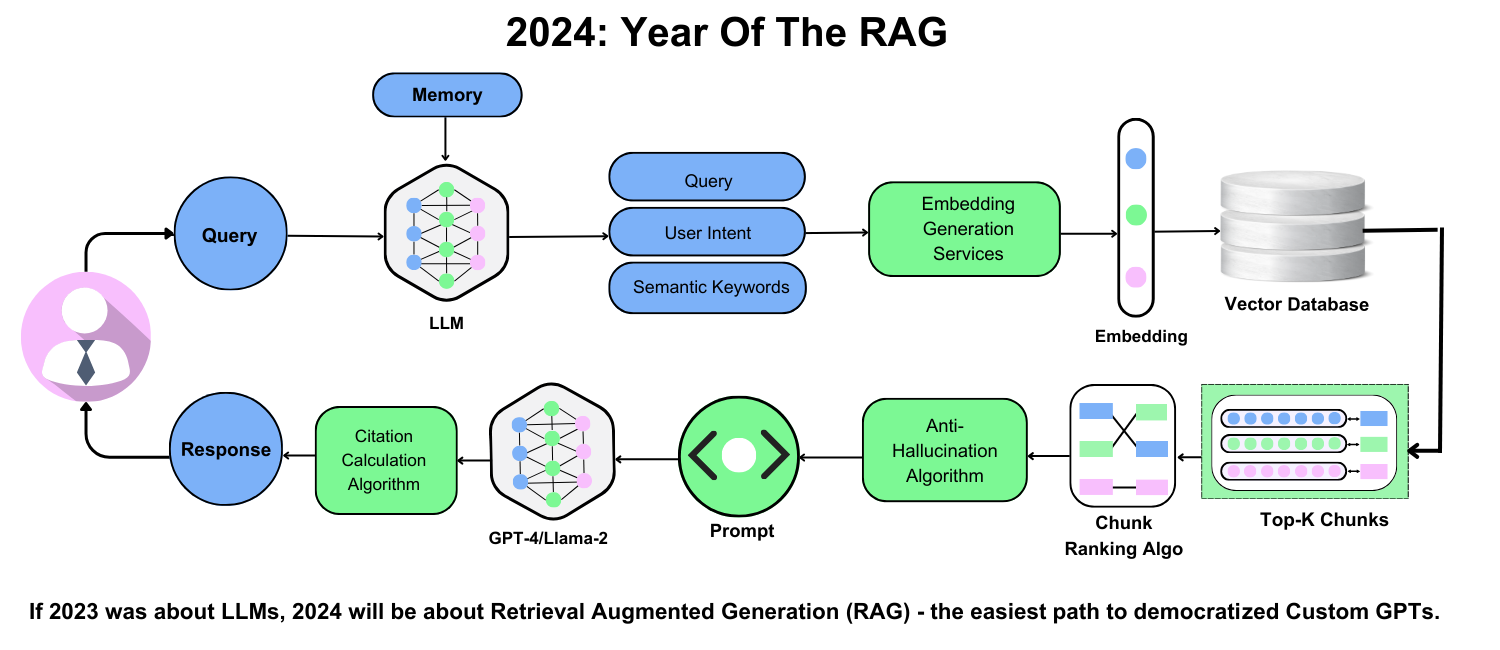
Discover the power of rag for beginners in 2024 with this comprehensive guide, covering the fundamentals of Retrieval Augmented Generation, its implementation, and its impact on AI innovation.| CustomGPT
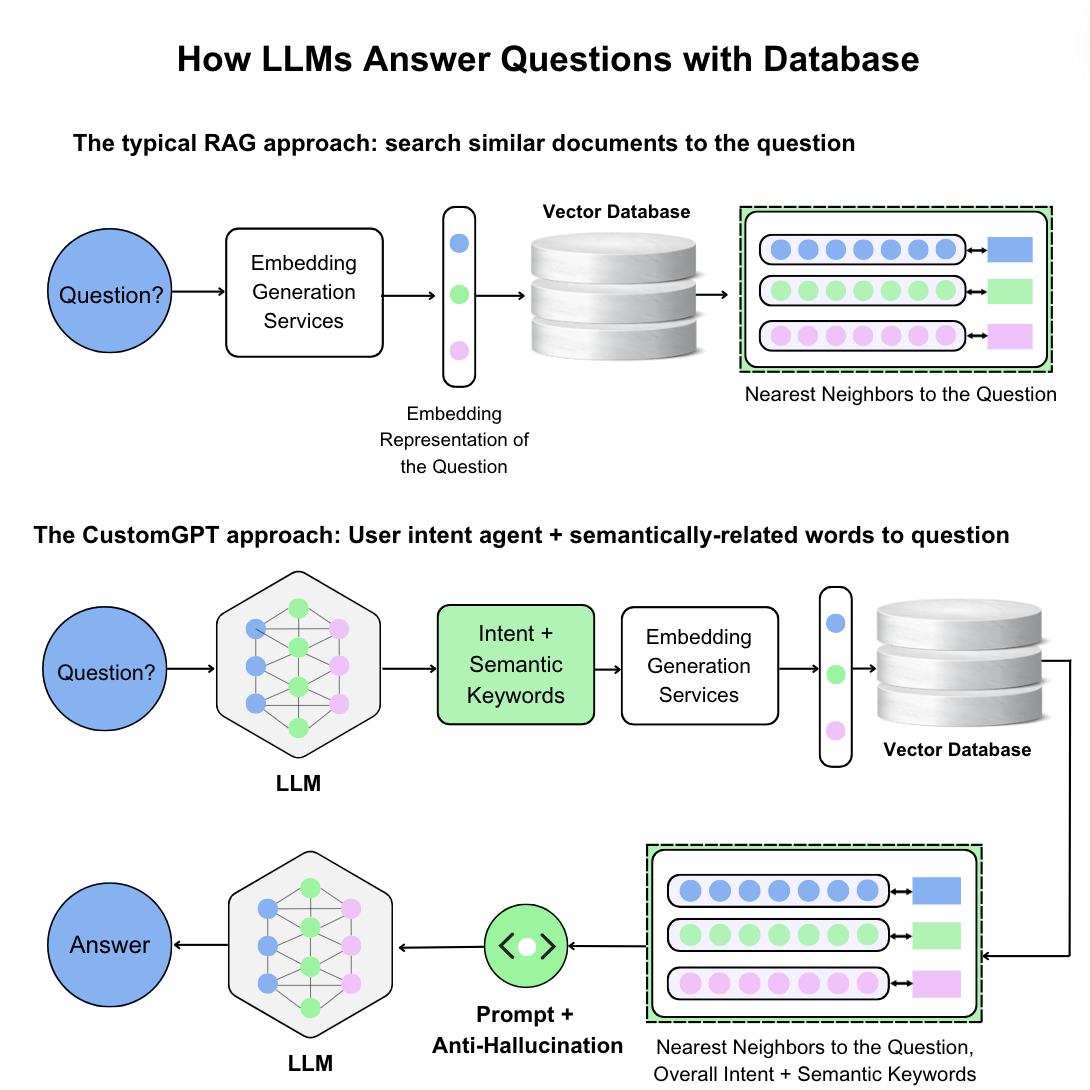
Explore the importance of RAG data sync for Retrieval Augmented Generation systems. Learn how keeping your data synchronized prevents outdated chatbot responses and ensures a reliable RAG system.| CustomGPT

Explore which RAG platform, CustomGPT.ai or Ragie.ai, best fits your business needs in our comprehensive guide.| CustomGPT

Auto Sync is designed to keep your custom GPT AI in sync with your content, making sure that bot answers are as always trustworthy without hallucinations.| CustomGPT
RAGFlow introduces the Text2SQL feature in response to community demand. Traditional Text2SQL requires model fine-tuning, which can significantly increase deployment and maintenance costs when used in enterprise settings alongside RAG or Agent components. RAGFlow’s RAG-based Text2SQL leverages the existing (connected) large language model (LLM), enabling seamless integration with other RAG/Agent components without the need for additional fine-tuned models.| RAGFlow Blog
RAGFlow v0.9 introduces support for GraphRAG, which has recently been open-sourced by Microsoft, allegedly the next generation of Retrieval-Augmented Generation (RAG). Within the RAGFlow framework, we have a more comprehensive definition of RAG 2.0. This proposed end-to-end system is search-centric and consists of four stages. The last two stages—indexing and retrieval—primarily require a dedicated database, while the first two stages are defined as follows:| RAGFlow Blog

Learn why traditional RAG isn't enough for production AI apps, and how combining batch, streaming, and real-time context can deliver truly valuable GenAI solutions.| Tecton

CustomGPT.ai excels over OpenAI in a rigorous new AI benchmark study.| CustomGPT

A great chatbot combines intent-based techniques for "can't be wrong" questions together with RAG and LLMs techniques for more open, exploratory, questions| Livable Software

Ragie launches with $5.5M in funding to ease RAG application development - SiliconANGLE| SiliconANGLE

I enjoy reading books on Oreilly learning platform . For the past month, a new feature on the Oreilly platform called “Answers” has been staring me down, and I haven’t been tempte…| Shekhar Gulati

The third part of the No BS guide to getting started developing with LLMs. We’ll explore processing audio and using text to speech and speech to text engines to open up new doors for interacting with LLMs and processing data.| GDCorner
Search technology remains one of the major challenges in computer science, with few commercial products capable of searching effectively. Before the rise of Large Language Models (LLMs), powerful search capabilities weren't considered essential, as they didn't contribute directly to user experience. However, as the LLMs began to gain popularity, a powerful built-in retrieval system became required to apply LLMs to enterprise settings. This is also known as Retrieval-Augmented Generation (RAG)...| ragflow.io
In this article, we will explain that RAG is really nothing more than saying: hey LLM, here is a bunch of data, can you tell me about it?| Luc van Donkersgoed's Notes
The workflow of a naive RAG system can be summarized as follows: the RAG system does retrieval from a specified data source using the user query, reranks the retrieval results, appends prompts, and sends them to the LLM for final answer generation.| RAGFlow Blog
RAGFlow v0.6.0 was released this week, solving many ease-of-use and stability issues that emerged since it was open sourced earlier this April. Future releases of RAGFlow will focus on tackling the deep-seated problems of RAG capability. Hate to say it, existing RAG solutions in the market are still in POC (Proof of Concept) stage and can’t be applied directly to real production scenarios. This is primarily due to the numerous unresolved issues within RAG itself:| ragflow.io
As of v0.8, RAGFlow is officially entering the Agentic era, offering a comprehensive graph-based task orchestration framework on the back-end and a no-code workflow editor on the front-end. Why agentic? How does this feature differ from existing workflow orchestration systems?| ragflow.io

We’re on a journey to advance and democratize artificial intelligence through open source and open science.| huggingface.co
The second part of the No BS guide to getting started developing with LLMs. We’ll explore connecting to an LLM host via a network API, using streaming for responses, usage statistics, generation settings, chat templates, and system prompts.| GDCorner

テキストと表の両方を含むハイブリッドな文書からLLMで情報を抽出する能力についてはまだ十分に研究されていません。そこで研究者らは、分割・再結合ベースの方法論を提案しています。実験により、抽出の精度が格段に上昇することを明らかにしました。| AIDB

Using the “shortening” properties of OpenAI v3 embedding models to greatly reduce latency/cost while retaining near-exact quality| Vespa Blog
Retrieval Augmented Generation (RAG) is a simple yet powerful approach that can be used to improve the performance of LLMs on a wide range of tasks.| LLMStack Blog
