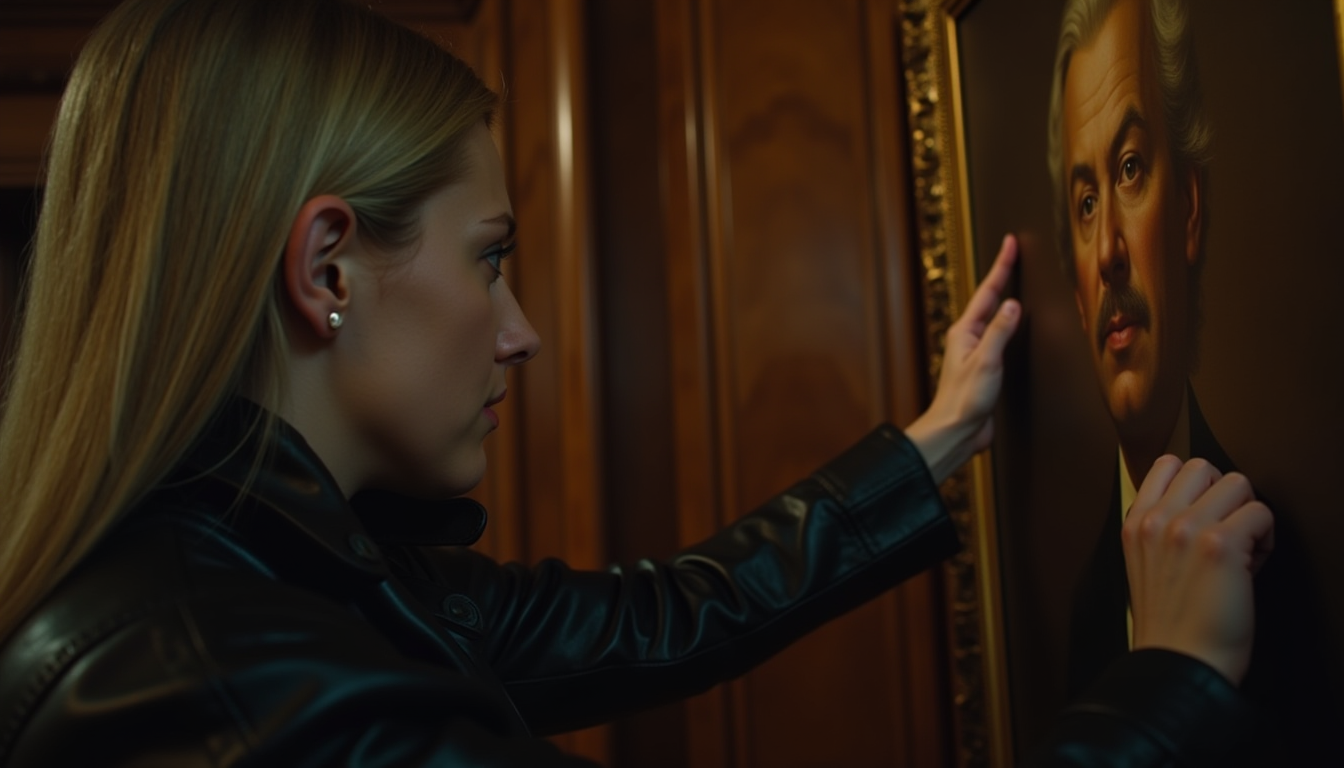Qwen Image Edit is a competent AI image editing model. You can use it to edit images using a text prompt alone or with an editing mask. In this tutorial, you will learn how to use Qwen Image Edit using multiple images. Workflow 1: Change a person’s clothes using a reference image. Workflow 2: Interaction… Continue reading Qwen Image Edit: Multiple-image workflow <p>The post Qwen Image Edit: Multiple-image workflow first appeared on Stable Diffusion Art.</p>| Stable Diffusion Art
Qwen Image Edit is an image-editing AI model. It can be used to edit the image with text prompts alone. The edit can change any part of the image. What if you only want to change a certain part of the image, keeping the rest unchanged? In the AI world, you have to do inpainting… Continue reading Qwen Image Edit Inpaint – Precise mask edit <p>The post Qwen Image Edit Inpaint – Precise mask edit first appeared on Stable Diffusion Art.</p>| Stable Diffusion Art
AI image generators such as Flux and SDXL generate good virtual AI influencers, but their skins can look plastic, like making out of rubber. This workflow enhances the skin of your AI influencer to look more realistic. You must be a member of this site to download the following ComfyUI workflow. Software How does this… Continue reading Skin Detailer: Realistic skins for AI influencers <p>The post Skin Detailer: Realistic skins for AI influencers first appeared on Stable Diffusion Art.</p>| Stable Diffusion Art
Qwen Image Edit is an image-editing model. It enables you to make precise edits to images, from subtle retouches to complex scene transformations, all through| Stable Diffusion Art
Outpainting in ComfyUI on RunDiffusion lets you expand any image with full creative control. This guide walks through how to perform outpainting in comfyui.| RunDiffusion
Learn how to use the Qwen-Image-Edit-2509 image model in ComfyUI on RunDiffusion. Supports multi-image editing, pose transfer, product showcase, and ControlNet. Step-by-step guide and examples.| RunDiffusion
Wan2.2 Animate generates new video clips guided by an input video, a reference image, and a prompt. RunDiffusion now hosts a workflow using this model so you can produce character swapped or stylized videos directly in the cloud.| RunDiffusion
Change backgrounds. Swap objects. Add stuff. Remove stuff. Adjust styles. All through simple text prompts instead of wrestling with complicated tools. Qwen is Alibaba's image editing model, built on their 20B-parameter foundation. It handles object manipulation, style transfers, and even text editing inside images. The results are surprisingly realistic, and| ThinkDiffusion
ComfyUI Desktop makes it easier than ever to run ComfyUI locally without messing with the command line. It’s the most beginner-friendly way to start creating AI images and videos locally. No Python setup, Git installation, and configuration headaches. If you just want to get started quickly, ComfyUI Desktop is the clear winner. The installation takes… Continue reading ComfyUI Desktop: Installation & review <p>The post ComfyUI Desktop: Installation & review first appeared on Stable Diffusi...| Stable Diffusion Art
Long-time member Heinz Zysset kindly shares this high-resolution text-to-video workflow. This workflow uses: Software needed Wan 2.2 upscale workflow Step 1: Download models Download the Wan 2.2 AIO model wan2.2-t2v-rapid-aio.safetensors. Put it in ComfyUI > models > checkpoints. Download the 4x-Ultrasharp model. Put it in ComfyUI > models > upscale_models folder. Step 2: Download the workflow Download the… Continue reading Wan 2.2 AIO Upscale workflow <p>The post Wan 2.2 AIO Upscale wor...| Stable Diffusion Art
Qwen Image is a new open-source text-to-image model developed by Alibaba’s Qwen team. It’s quickly gaining thumbs-up from AI creators. Unlike many closed| Stable Diffusion Art
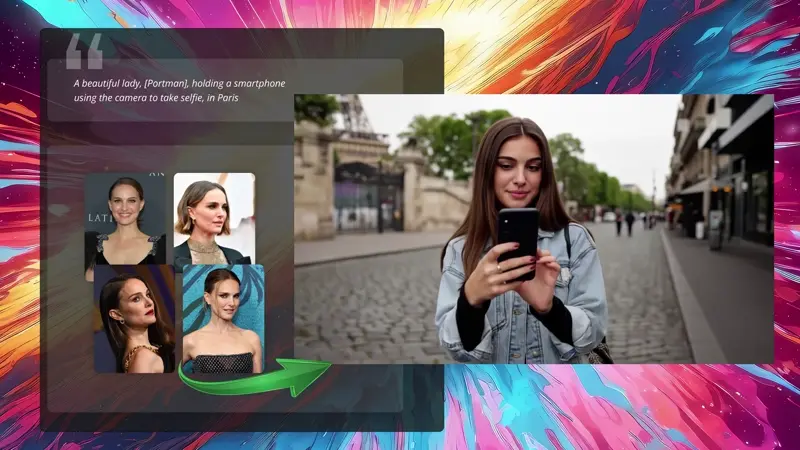
Generating Qwen images with Controlnet unlocks a powerful way to guide your AI creations using visual structure, lines, and forms drawn or extracted from reference images. Want better control over your AI image generation? Here's how to use Qwen Image with InstantX Union ControlNet to guide your creations with poses,| ThinkDiffusion
Wan 2.1 Video is a series of open foundational video models. It supports a wide range of video-generation tasks. It can turn images or text descriptions into| Stable Diffusion Art
ComfyUI is a popular, open-source user interface for Stable Diffusion, Flux, and other AI image and video generators. It makes it easy for users to| Stable Diffusion Art
ComfyUI is a popular way to run local Stable Diffusion and Flux AI image models. It is a great complement to AUTOMATIC1111 and Forge. Some workflows may| Stable Diffusion Art
You can use a reference image to direct AI image generation using ControlNet. Below is an example of copying the pose of the girl on the left to generate a| Stable Diffusion Art
This updated guide helps RunDiffusion users fix red nodes, missing models, broken paths, and deprecated nodes in the new ComfyUI layout. Learn to use Comfy Manager and restart sessions properly.| RunDiffusion
0:00 /0:06 1× 💡Credits to the awesome Benji for this workflow. Original Link - https://www.youtube.com/watch?v=b69Qs0wvaFE&t=311s Uni3C is a ComfyUI model by Alibaba that converts static images into dynamic videos by transferring camera movements from reference videos. This tutorial covers complete| ThinkDiffusion
This Wan 2.2 image-to-video workflow lets you fix the first and last frames and generates a video connecting the two (FLF2V). See the example below.| Stable Diffusion Art
0:00 /0:02 1× What This Workflow Does This ComfyUI workflow creates smooth animations by: * Taking your starting image * Generating an end frame with AI * Creating seamless transitions between both frames * Maintaining consistent subjects and backgrounds throughout 💡Credits to the awesome TheArtOfficial for this workflow. Original Link: https://www.| ThinkDiffusion
Wan 2.2 is one of the best local video models. Generating high-quality videos is what it is known for. But if you set the video frame to 1, you get an image!| Stable Diffusion Art
0:00 /0:12 1× Transform static portraits into realistic talking videos with perfect lip-sync using MultiTalk AI. No coding required. Difficulty: Beginner-friendly Setup Time: 15 minutes What You'll Create Turn any portrait - artwork, photos, or digital characters - into speaking, expressive videos that sync perfectly with audio input.| ThinkDiffusion
Wan 2.2 is a local video model that can turn text or images into videos. In this article, I will focus on the popular image-to-video function. The new Wan 2.2| Stable Diffusion Art
WAN 2.1 VACE (Video All-in-One Creation and Editing) is a video generation and editing AI model that you can run locally on your computer. It unifies| Stable Diffusion Art
WAN 2.1 VACE (Video All-in-One Creation and Editing) is a video generation and editing model developed by the Alibaba team. It unifies text-to-video,| Stable Diffusion Art
This workflow generates four video clips and combines them into a single video. To improve the quality and control of each clip, the initial frame is| Stable Diffusion Art
This workflow generates beautiful videos of mechanical insects from text prompts. You can run it locally or using a ComfyUI service. It uses Flux AI to| Stable Diffusion Art
Wan 2.1 Video is a state-of-the-art AI model that you can use locally on your PC. However, it does take some time to generate a high-quality 720p video, and| Stable Diffusion Art
0:00 /0:05 1× The recently released Wan 2.1 is a groundbreaking open-source AI video model. Renowned for its ability to exceed the performance of other open-source models like Hunyuan and LTX, as well as numerous commercial alternatives, Wan 2.1 delivers truly incredible text2video and image2video generations| ThinkDiffusion
LTX speeds up the video-making process so you can focus on what really matters — telling your story and connecting with your audience. In this guide, we'll focus on Image2Video generation specifically, and we’ll explore all the features that make LTX a game-changer.| ThinkDiffusion
💡Update 03/14/2025: Uploaded a new version of workflow 0:00 /0:04 1× Hey there, video enthusiasts! It’s a thrill to see how quickly things are changing, especially in the way we create videos. Picture this: with just a few clicks, you can transform your existing clips| ThinkDiffusion
Hunyuan Video is a new local and open-source video model with exceptional quality. It can generate a short video clip with a text prompt alone in a few| Stable Diffusion Art