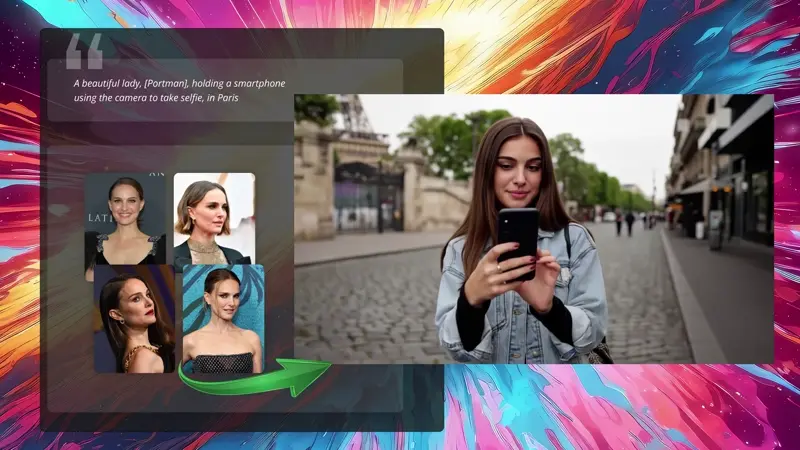
Discover why Wan 2.1 is the best AI video model right now.
0:00 /0:05 1× The recently released Wan 2.1 is a groundbreaking open-source AI video model. Renowned for its ability to exceed the performance of other open-source models like Hunyuan and LTX, as well as numerous commercial alternatives, Wan 2.1 delivers truly incredible text2video and image2video generations| ThinkDiffusion