
JEPA Series Part 1: Introduction to I-JEPA
I-JEPA methodoly teaches a vision transformer model to predict parts of an image in the latent space rather than the pixel space.| DebuggerCafe
I-JEPA methodoly teaches a vision transformer model to predict parts of an image in the latent space rather than the pixel space.| DebuggerCafe
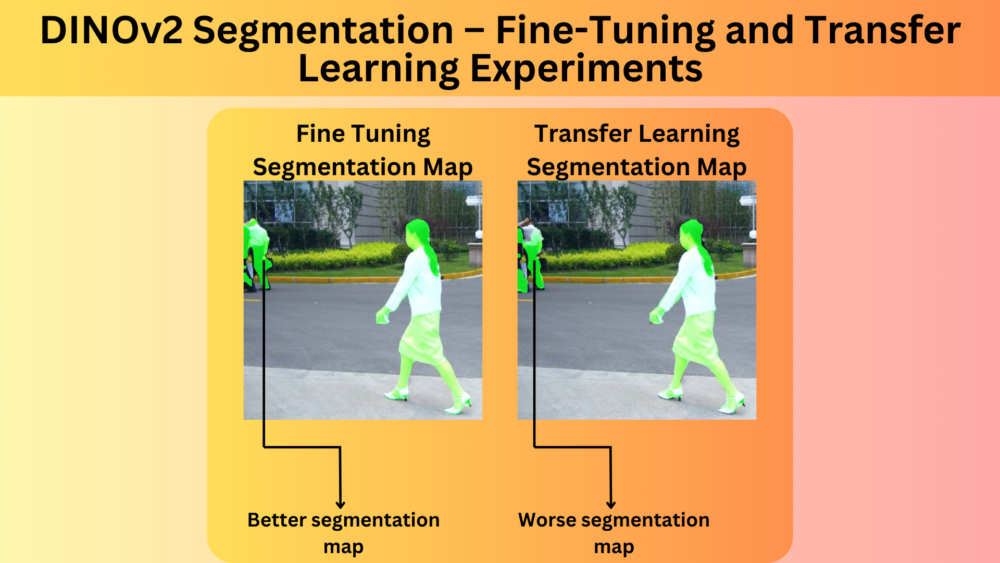
Carrying out DINOv2 segmentation experiments for fine-tuning and transfer learning and comparing the results.| DebuggerCafe

Modifying the DINOv2 model for semantic segmentation and training the model on the Penn-Fudan Pedestrian Segmentation Dataset.| DebuggerCafe

RT-DETR is a Real-Time Detection Transformer model with state-of-the-art performance and speed on image and video inference using PyTorch.| DebuggerCafe
