
WHAT.WHY.HOW? Machine Learning Series: Linear Regression Model - DEV Community
WHAT is a Linear Regression Model Linear regression is a statistical method for modelling...| DEV Community
Introduction: Why “Kubernetes AI” Dominates 2025 Search Rankings If you’ve been following cloud computing trends in 2025, you’ve probably noticed one term consistently topping search results: Kubernetes AI. This isn’t just a passing fad—it represents the most significant shift in container orchestration since Kubernetes itself revolutionized cloud-native development. According to multiple industry reports and trend […]| Collabnix
On the last day of UX London this year, I was sitting and chatting with Rachel Coldicutt who was going to be giving the closing keynote. Inevitably the topic of converstation worked its way ’round to “AI”. I remember Rachel having a good laugh when I summarised my overall feeling: I kind of wish I could go into suspended animation and be woken up when all this is over and things have settled down one way or another. I still feel that way. Like Gina, I’d welcome a measured approach to ...| Adactio: Journal
Brian Eno, interviewed by Ezra Klein, recalled a moment some years ago when he was talking with the engineers at Yamaha about one of their synthesizers. Like most synthesizers, this one came with a series of preset tones but was also programmable, and Eno told the engineers that they should make the synthesizer easier to program. They replied that nobody ever programs the synthesizer, they just use the presets. There would be no value for Yamaha in investing the thought and effort into making...| The Homebound Symphony
Daring Fireball: If your opinion of a work art changes after you find out which tools were used to make it, or who the artist is or what they’ve done, you’re no longer judging the art. You’re making a choice not to form your opinion based on the work itself, but rather on something else. […] If an image, a song, a poem, or video evokes affection in your heart, and then that affection dissipates when you learn what tools were used to create it, that’s not a test of the work of art it...| The Homebound Symphony
When I talk about large language models, I make sure to call them large language models, not “AI”. I know it’s a lost battle, but the terminology matters to me. The term “AI” can encompass everything from a series of if/else statements right up to Skynet and HAL 9000. I’ve written about this naming collision before. It’s not just that the term “AI” isn’t useful, it’s so broad as to be actively duplicitous. While talking about one thing—like, say, large language models...| Adactio: Journal
WHAT is a Linear Regression Model Linear regression is a statistical method for modelling...| DEV Community
...| The Homebound Symphony
...| The Homebound Symphony
...| The Homebound Symphony

Whether you’re generating slop or code, underneath it’s the same shoggoth with a smiley face.| adactio.com
Play nice in the enterprise development sandbox with this one simple trick.| Port 1433
Background| hillman.dev
Patrick Hoefler| Blog
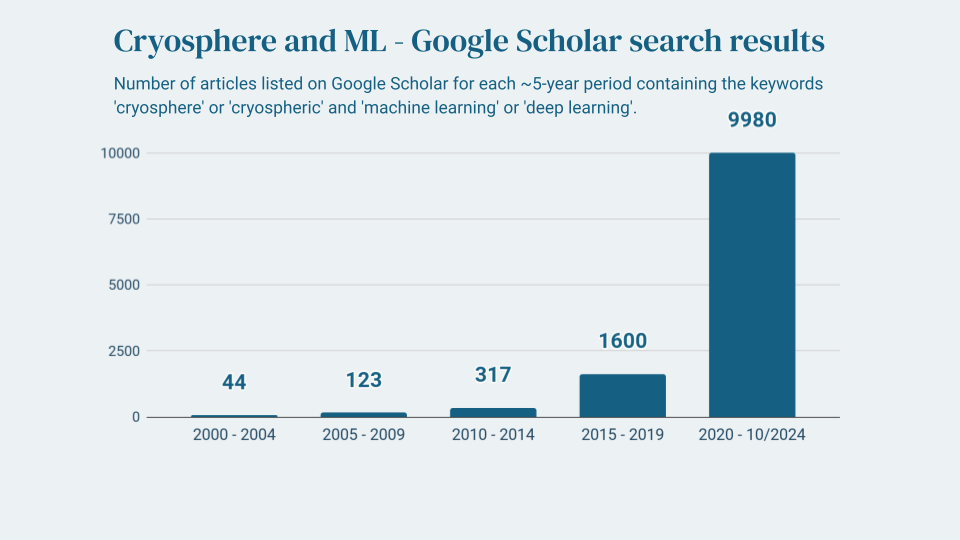
Recently, Machine Learning (ML) has emerged as a powerful tool within cryospheric sciences, offering innovative and effective solutions for observing, modelling and understanding the frozen regions of the Earth. From learning snowfall patterns and predicting avalanche dynamics to speeding up the process of modelling ice sheets, ML has transformed cryospheric sciences and bears many opportunities for future research. Case study: Sea ice As an example, let’s consider how ML can help us observ...| Cryospheric Sciences
Self-hosted sabotage as a form of collective action.| adactio.com
A quick look into the biology and machine learning behind DeepMind's new AlphaFold| daleonai.com
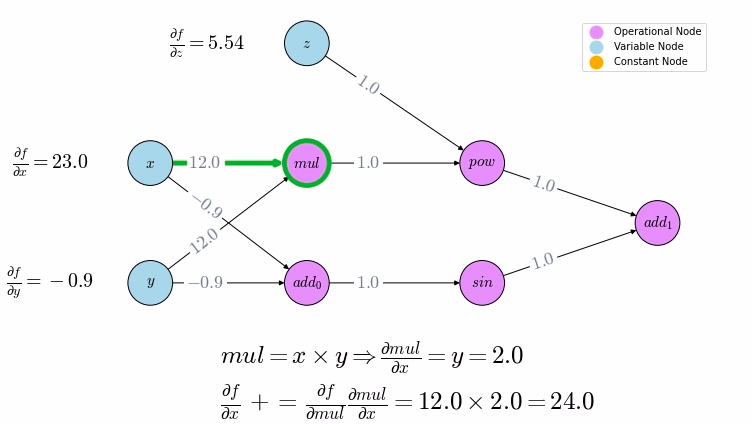
Wandering in a lifelong journey seeking after truth| Mostafa Samir's Blog
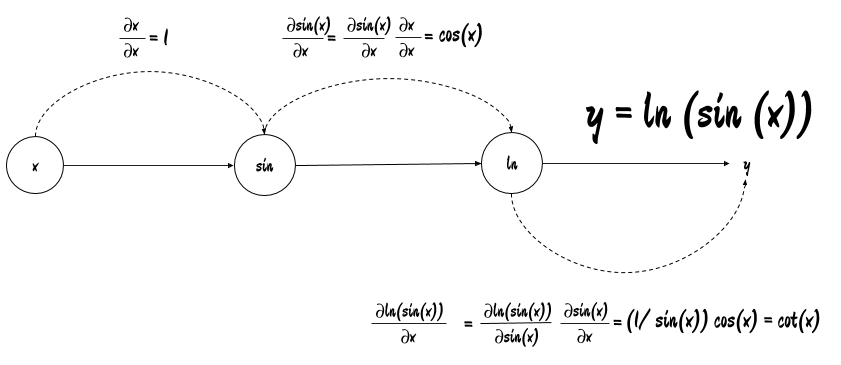
Wandering in a lifelong journey seeking after truth| Mostafa Samir's Blog
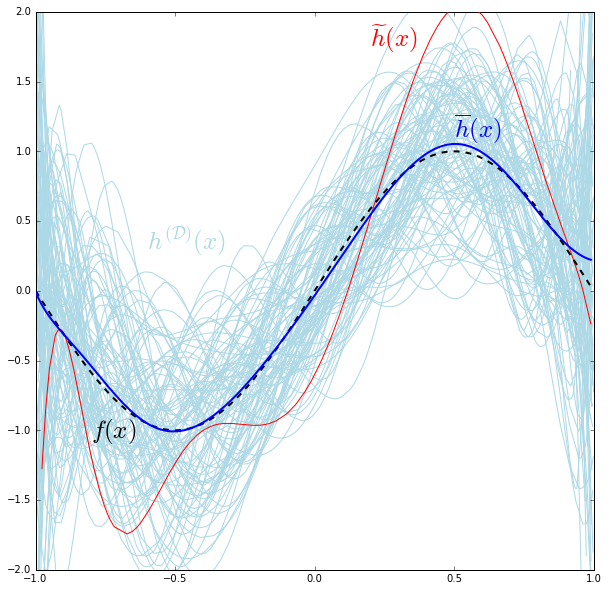
Wandering in a lifelong journey seeking after truth| Mostafa Samir's Blog
Scribd offers a variety of publisher and user-uploaded content to our users and while the publisher content is rich in metadata, user-uploaded content typically is not. Documents uploaded by the users have varied subjects and content types which can make it challenging to link them together. One way to connect content can be through a taxonomy - an important type of structured information widely used in various domains. In this series, we have already shared how we identify document types and...| Scribd Technology
Extracting metadata from our documents is an important part of our discovery and recommendation pipeline, but discerning useful and relevant details from text-heavy user-uploaded documents can be challenging. This is part 2 in a series of blog posts describing a multi-component machine learning system the Applied Research team built to extract metadata from our documents in order to enrich downstream discovery models. In this post, we present the challenges and limitations the team faced when...| Scribd Technology
User-uploaded documents have been a core component of Scribd’s business from the very beginning, understanding what is actually in the document corpus unlocks exciting new opportunities for discovery and recommendation. With Scribd anybody can upload and share documents, analogous to YouTube and videos. Over the years, our document corpus has become larger and more diverse which has made understanding it an ever-increasing challenge. Over the past year one of the missions of the Applied Res...| Scribd Technology
Everything you wanted to know about AI on Google Cloud, and much more| daleonai.com
GPU ML on Intel Arc| hillman.dev
