
IBM releases Granite 4 series of Mamba-Transformer language models - SiliconANGLE
IBM releases Granite 4 series of Mamba-Transformer language models - SiliconANGLE| SiliconANGLE
Salesforce AI Research released CoDA-1.7B, a diffusion-based language model for code that generates by denoising whole sequences with bidirectional context, updating multiple tokens in parallel rather than left-to-right next-token prediction. The research team published both Base and Instruct checkpoints and an end-to-end training/evaluation/serving stack. Understanding the architecture and training CoDA adapts a 1.7B-parameter backbone to […] The post Salesforce AI Research Releases CoDA-1...| MarkTechPost
We will build a Regression Language Model (RLM), a model that predicts continuous numerical values directly from text sequences in this coding implementation. Instead of classifying or generating text, we focus on training a transformer-based architecture that learns quantitative relationships hidden within natural language descriptions. We start by generating synthetic text-to-number data, tokenizing it efficiently, […] The post A Coding Implementation to Build a Transformer-Based Regressi...| MarkTechPost
What if, instead of re-sampling one agent, you could push Gemini-2.5 Pro to 34.1% on HLE by mixing 12–15 tool-using agents that share notes and stop early? Google Cloud AI Research, with collaborators from MIT, Harvard, and Google DeepMind, introduced TUMIX (Tool-Use Mixture)—a test-time framework that ensembles heterogeneous agent styles (text-only, code, search, guided variants) […] The post Google Proposes TUMIX: Multi-Agent Test-Time Scaling With Tool-Use Mixture appeared first on M...| MarkTechPost
Researchers from Cornell and Google introduce a unified Regression Language Model (RLM) that predicts numeric outcomes directly from code strings—covering GPU kernel latency, program memory usage, and even neural network accuracy and latency—without hand-engineered features. A 300M-parameter encoder–decoder initialized from T5-Gemma achieves strong rank correlations across heterogeneous tasks and languages, using a single text-to-number decoder […] The post Can a Small Language Model ...| MarkTechPost
IBM releases Granite 4 series of Mamba-Transformer language models - SiliconANGLE| SiliconANGLE

Alibaba Releases Tongyi DeepResearch: A 30B-Parameter Open-Source Agentic LLM Optimized for Long-Horizon Research| MarkTechPost

IBM releases GraniteDocling, an open-source compact document AI model with improved accuracy, multilingual support, and enterprise readiness| MarkTechPost

In this tutorial, we’ll walk through how to:Load and use a pre-trained router. Calibrate it for your own use case. Test routing prompts.| MarkTechPost
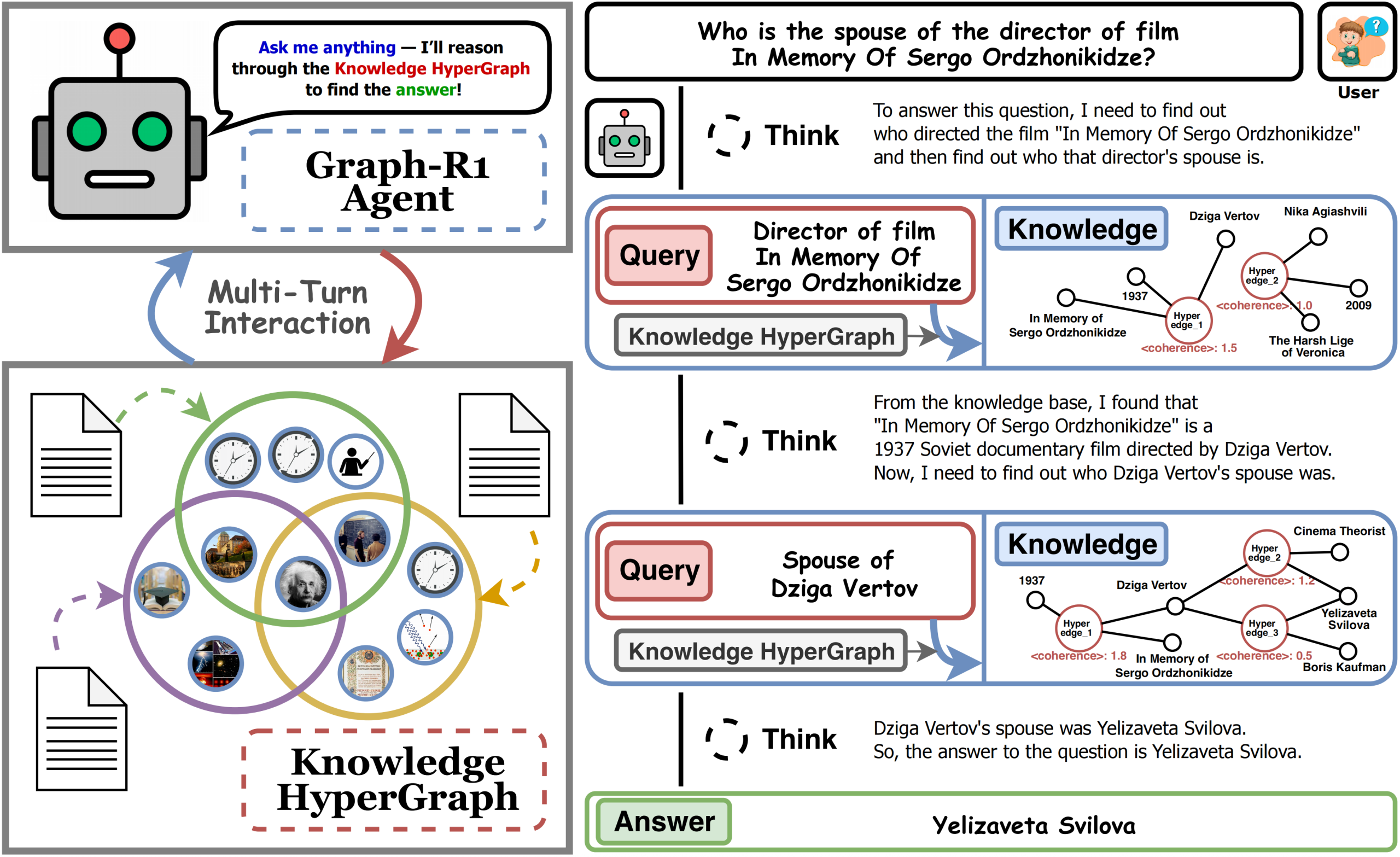
Graph-R1, an advanced agentic GraphRAG framework using hypergraph knowledge and reinforcement learning for accurate, efficient QA| MarkTechPost

Mixture-of-Experts MoE Architecture Comparison: Qwen3 30B-A3B vs. GPT-OSS 20B| MarkTechPost
We have been training language models (LMs) for years, but finding valuable resources about the data pipelines commonly used to build the datasets for training The post Large language model data pipelines and Common Crawl (WARC/WAT/WET) first appeared on Terra Incognita.| Terra Incognita

s1: A Simple Yet Powerful Test-Time Scaling Approach for LLMs| MarkTechPost

Learn about Large Language Models (LLMs) in this article, covering basics and advanced concepts for understanding.| Triple A Review
