
The 10 Top Sights of Barcelona - Anne Travel Foodie
I'm sharing the top 10 sights of Barcelona here. You can't leave Barcelona without seeing these ten iconic spots.| Anne Travel Foodie
I'm sharing the top 10 sights of Barcelona here. You can't leave Barcelona without seeing these ten iconic spots.| Anne Travel Foodie
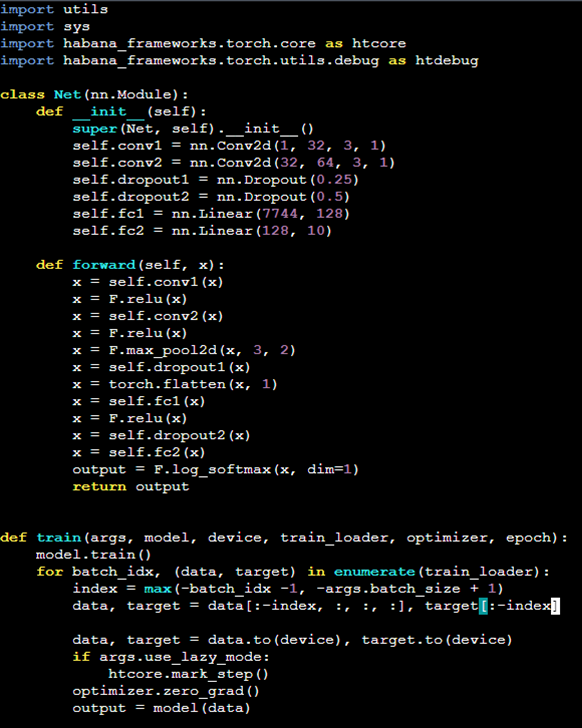
In training workloads, there may occur some scenarios in which graph re-compilations occur. This can create system latency and slow down the overall training process with multiple iterations of graph compilation.| Intel Gaudi Developers

In this post, we show you how to run Habana’s DeepSpeed enabled BERT1.5B model from our Model-References repository.| Habana Developers

In this post, we will learn how to run PyTorch stable diffusion inference on Habana Gaudi processor, expressly designed for the purpose of efficiently accelerating AI Deep Learning models.| Habana Developers
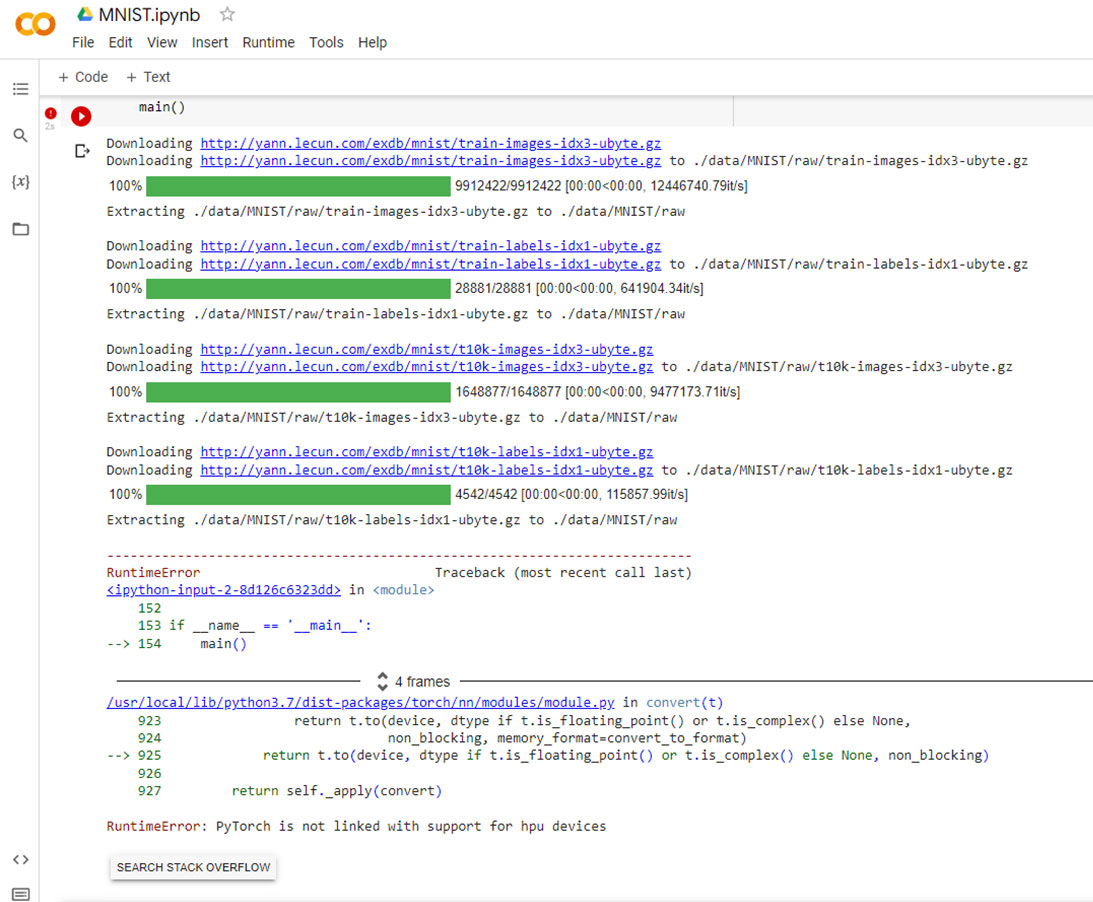
Sometimes we want to run the same model code using different type of AI accelerators. For example, this can be required if your development laptop has a GPU, but your training server is using Gaudi.| Habana Developers

Fine tuning GPT2 with Hugging Face and Habana Gaudi. In this tutorial, we will demonstrate fine tuning a GPT2 model on Habana Gaudi AI processors using Hugging Face optimum-habana library with DeepSpeed.| Habana Developers

Optimize your deep learning with data parallel processes on Intel Gaudi using DeepSpeed. Enhance efficiency in training with our expert insights.| Intel Gaudi Developers
