¿Qué Viene Después de la Era de los LLMs? - OpenSecurity
En un mundo donde la inteligencia artificial está cada vez más integrada en nuestra vida cotidiana, surge una pregunta fundamental: […]| OpenSecurity
Polaris AI leverages Google Cloud’s Gemini family of multimodal models and Eleos’ secure and clinically validated infrastructure to reduce documentation burden, strengthen compliance and help providers focus on care. Boston, MA — Oct. 20, 2025 — Eleos, the leader in AI for post-acute care, today announced the launch of Polaris AI, built in collaboration with […] The post Eleos to Launch Polaris AI Advanced, Purpose-Built Foundational AI Model for Post-Acute Care, built with Google C...| Eleos Health
AI researchers at Andon Labs embedded various LLMs in a vacuum robot to test how ready they were to be embodied. And hilarity ensued.| TechCrunch
Kimi K2, hosted on Grow, running in TypingMind with a custom plugin I made. I’ll talk about this more in depth in Monday’s episode of AppStories (if you’re a Plus subscriber, it’ll be out on Sunday), but I wanted to post a quick note on the site to show off what I’ve been experimenting with this week. I started playing around with TypingMind, a web-based wrapper for all kinds of LLMs (from any provider you want to use), and, in the process, I’ve ended up recreating parts of my Cla...| MacStories
In addition to the M5 iPad Pro, which I reviewed earlier today, I also received an M5 MacBook Pro review unit from Apple last week. I really wanted to write a companion piece to my iPad Pro story about MLX and the M5’s Neural Accelerators; sadly, I couldn’t get the latest MLX branch to work on the MacBook Pro either. However, Max Weinbach at Creative Strategies did, and shared some impressive results with the M5 and its GPU’s Neural Accelerators: These dedicated neural accelerators in e...| MacStories
The M5 iPad Pro. How do you review an iPad Pro that’s visually identical to its predecessor and marginally improves upon its performance with a spec bump and some new wireless radios? Let me try: I’ve been testing the new M5 iPad Pro since last Thursday. If you’re a happy owner of an M4 iPad Pro that you purchased last year, stay like that; there is virtually no reason for you to sell your old model and get an M5-upgraded edition. That’s especially true if you purchased a high-end con...| MacStories
En un mundo donde la inteligencia artificial está cada vez más integrada en nuestra vida cotidiana, surge una pregunta fundamental: […]| OpenSecurity
Are pixels are better inputs to LLMs than text? A novel new model suggests the answer is yes.| The Stack
In this article, we are training the Gemma 3n model for transcription and translation of German audio files to English using the Unsloth library and creating a Gradio application also. The post Training Gemma 3n for Transcription and Translation appeared first on DebuggerCafe.| DebuggerCafe

Fine-tuning Gemma 3n for German speech transcription using the Unsloth library and carrying out evaluation.| DebuggerCafe
MCP is 'an open protocol that standardizes how applications provide context to LLMs.' If we’re moving toward a world where AIs are expected to do All The Things, interfacing with our applications and services, then having a universal adapter that lets AIs talk to everything is undeniably powerful. The post The MCP Bandwagon appeared first on Spherical Cow Consulting.| Spherical Cow Consulting
51% of European IT and cybersecurity professionals said they expect AI-driven cyber threats and deepfakes to keep them up at night in 2026, according to ISACA. AI takes centre stage in threat outlook The main reason for this concern is that most organizations are not ready to manage AI-related risks. Few feel confident in their ability to handle generative AI securely, while most admit they still have work to do to prepare for the challenges … More → The post Companies want the benefits o...| Help Net Security
Today's links The AI that we'll have after AI: Cheap GPUs, unemployed engineers, and open source models. Hey look at this: Delights to delectate. Object permanence: FBI confuses KISS and Dr Who; How the NSA breaks crypto: Bricked Ferrari; Taxing billionaires. Upcoming appearances: Where to find me. Recent appearances: Where I've been. Latest books: You keep readin' em, I'll keep writin' 'em. Upcoming books: Like I said, I'll keep writin' 'em. Colophon: All the rest. The AI that we'll have aft...| Pluralistic: Daily links from Cory Doctorow
By John Halamka and Paul Cerrato — With a growing shortage of clinicians and an aging population, more patients are seeking self-care information. But navigating the available AI tools remains a challenge even for the most internet savvy. The post Seeking Self-Care Information in the Age of ChatGPT appeared first on Mayo Clinic Platform.| Mayo Clinic Platform
I lied in the title, well, sort of. Nobody explicitly asked for this but the signs were always there.| Cats with power tools

Did it work well and is it useful in any way? No. Is it hilarious to mess around with and does it mimic them well? Yes.| Cats with power tools

ChatGPT operator OpenAI has introduced Instant Checkout, allowing customers to purchase products directly within AI chat.| Beauty Independent

Testing Google's highly anticipated Gemini 3.0 through AI Studio's A/B feature using SVG generation as a quality proxy| Rick Lamers' blog
What is LLM SEO Optimization? Let’s start with the basics. LLM SEO optimization is the process of making your online content easily understandable and discoverable … The post Best Practices for LLM-Optimized SEO: Targeting AI-Driven Search Engines and Answer Engines appeared first on Smarketers.| Smarketers

Optimize your content for Large Language Models and search engines: discover proven LLM and SEO strategies to boost AI, organic, and brand visibility.| Smarketers
In this article, we create a multimodal Gradio application with Together AI models for chatting LLMs & VLMs, generating images, and automatic speech transcription using OpenAI Whisper models. The post Multimodal Gradio App with Together AI appeared first on DebuggerCafe.| DebuggerCafe

Together AI serverless inference for text generation, image generation, and vision language models along with Gradio chat application.| DebuggerCafe
Imagine this: You ask your company’s AI a simple question and it answers with absolute confidence. But what if that answer is wrong, outdated, or completely irrelevant? In business, where every decision can have financial or reputational consequences, this isn’t just inconvenient. It’s dangerous. One of the biggest concerns holding companies back from using Generative […]| SEEBURGER Blog

The emergence of AI agents will transform how we think about digital experiences. Discover how Agentic Responsive Design will change the web.| AI Accelerator Institute
Discover how Grammarly’s AI-powered communication, personalization, and AI agents are reshaping the future of writing and collaboration.| AI Accelerator Institute

Chat with videos and get precise timestamps.| Daily Dose of Data Science
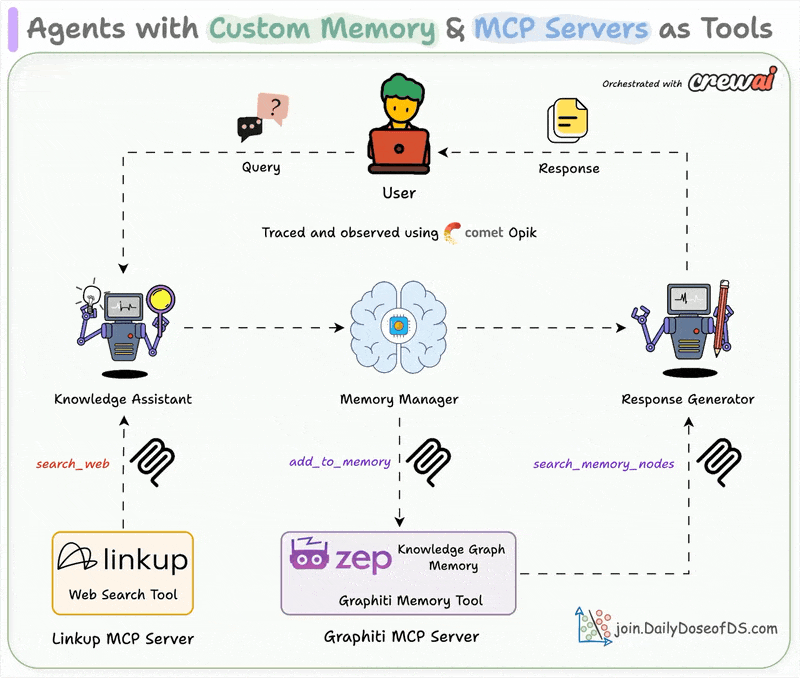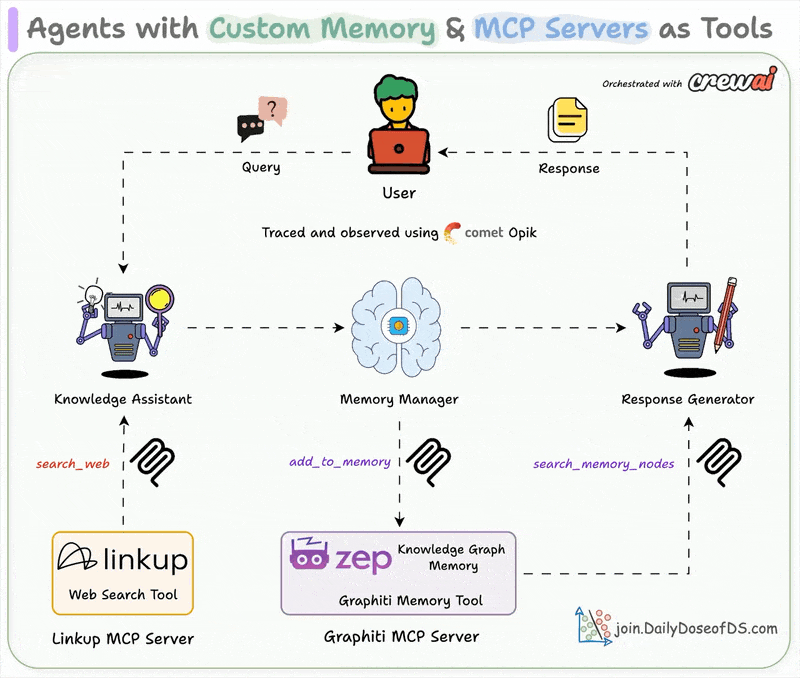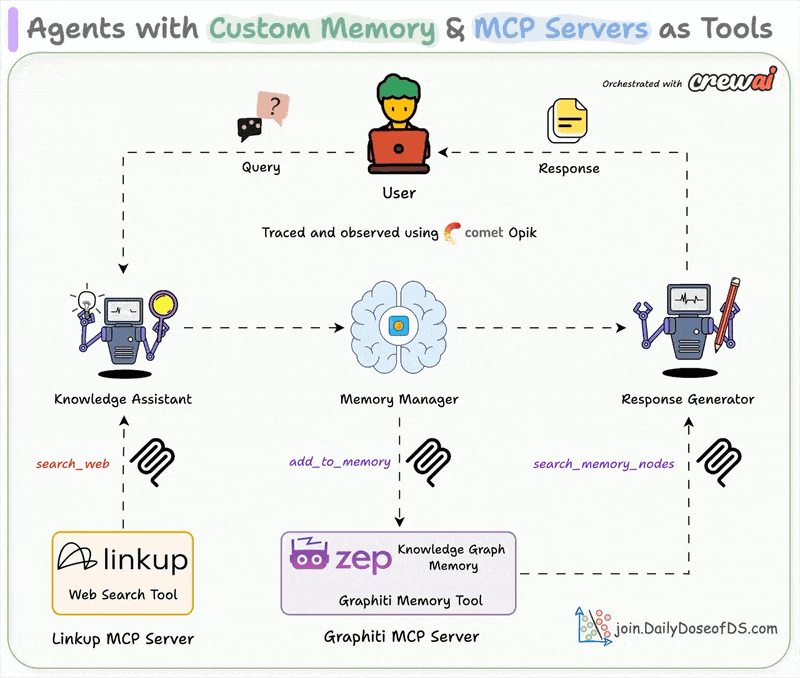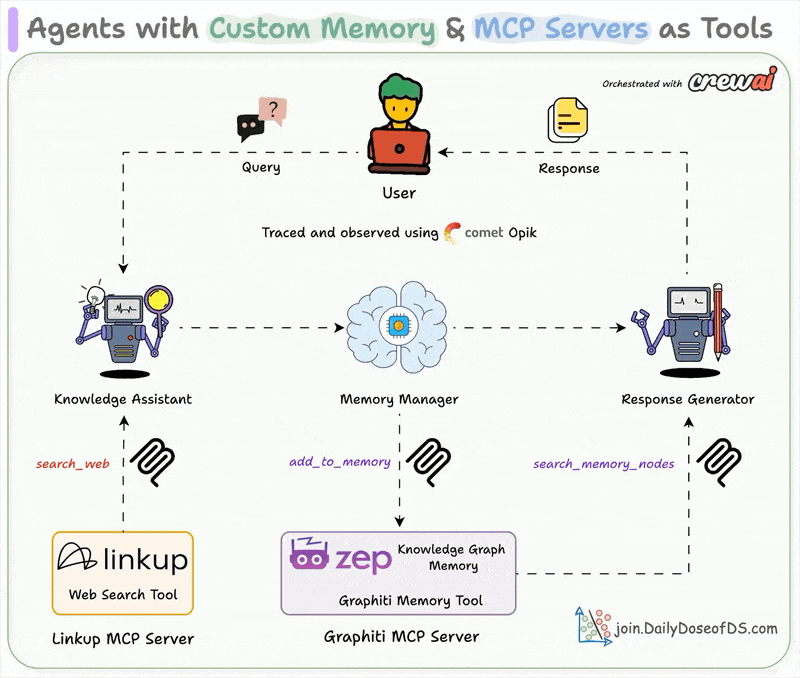
..powered with MCP + Tools + Memory + Observability.| Daily Dose of Data Science

I did some digging to track down the librarian I learned about on a thrift store postcard.| librarian.net

Cursor is an AI-focused VS Code fork. Here's Steve Kinney with a nice overview of what it offers and how to start getting help out of it right away.| frontendmasters.com

Explore how the Active Agent library brings Rails conventions to AI development, with real-world examples from Evil Martians' early adoption experience| evilmartians.com

LLMs in cybersecurity can boost decision accuracy, but uneven benefits and automation bias mean teams must verify outputs.| Help Net Security

If you’re trying to make sense of how to build AI agents, not just talk about them, AI Agents in Action might be for you—read the review.| Help Net Security
I’ve noticed something interesting over the past few weeks: I’ve started using the term “agent” in conversations where I don’t feel the need to then define it, roll my eyes …| Simon Willison’s Weblog
More from Mike Caulfield (see also the SIFT method). He starts with a fantastic example of Google's AI mode usually correctly handling a common piece of misinformation but occasionally falling …| Simon Willison’s Weblog

Avoid costly LLM pitfalls: Learn how token pricing, scaling costs, and strategic prompt engineering impact AI expenses—and how to save.| AI Accelerator Institute

All you need to know about Qwen 3 Max by Alibaba. China's most powerful AI with 1 trillion parameters, long context, and top benchmark scores.| Fello AI
Learn how Enriched SaaS App Intelligence can strengthen SaaS and AI Risk Management with classification, risk scoring, and AI app coverage. The post SaaS Risk Management for Vendors in the Age of AI appeared first on zvelo.| zvelo
Over the past months, I've been working on a project that combines my interests in data-engineering, AI, and civic transparency: building a [Contextualise AI](posts/contextualise-ai/)-based data pipeline that processes and analyses the procedures of the Norwegian Parliament (Stortinget).| Brett Kromkamp
In this article, we explore deploying LLMs using Runpod, Vast.ai, Docker, and Hugging Face Text Generation Inference. The post Deploying LLMs: Runpod, Vast AI, Docker, and Text Generation Inference appeared first on DebuggerCafe.| DebuggerCafe

Optimize your Shopify store content for AI and LLMs with these expert techniques. Learn steps to boost visibility, from structured data to more.| StoreSEO

This article serves as a primer on prompt engineering, delving into the array of techniques used to control LLMs.| AI Accelerator Institute

Discover expert insights on how to secure LLMs with the fastest guardrails in the industry, ensuring AI performance, safety, and reliability at scale.| AI Accelerator Institute

KT and Viettel will work to develop a Vietnamese AI language model, creating industry-specific AX platforms.| RCR Wireless News
Frontier model training has pushed GPUs and AI systems to their absolute limits, making cost, efficiency, power, performance per TCO, and reliability central to the discussion on effective training. The Hopper vs Blackwell comparisons are not as simple as Nvidia would have you believe. In this report, we will start by present the results of […]| SemiAnalysis
To many power users (Pro and Plus), GPT5 was a disappointing release. But with closer inspection, the real release is focused on the vast majority of ChatGPT’s users, which is the 700m+ free userbase that is growing rapidly. Power users should be disappointed; this release wasn’t for them. The real consumer opportunity for OpenAI lies […]| SemiAnalysis

Researchers say Chain-of-Thought reasoning in AI is mostly pattern-matching, not real logic, and fails outside training.| Digital Information World
Open-Source Large Language Models in Radiology| vitalab.github.io
Discover the hidden bias in how humans evaluate AI outputs! Learn how perceptions of procedural knowledge extraction shape trust in AI and explore pathways to bridge the human-AI divide.| Blue Headline
I shipped LLM 0.27 today (followed by a 0.27.1 with minor bug fixes), adding support for the new GPT-5 family of models from OpenAI plus a flurry of improvements to …| Simon Willison’s Weblog
With GenAI and LLMs comes great potential to delight and damage customer relationships—both during the sale, and in the UI/UX. How should AI company founders and product leaders adapt? The post Designing and Selling Enterprise AI Products [Worth Paying For] first appeared on Designing for Analytics (Brian T. O'Neill).| Designing for Analytics (Brian T. O'Neill)
Discover BlindChat, an open-source privacy-focused conversational AI that runs in your web browser, safeguarding your data while offering a seamless AI experience. Explore how it empowers users to enjoy both privacy and convenience in this transformative AI solution.| Mithril Security Blog
Large language models (LLMs) have fundamentally transformed our digital landscape, powering everything from chatbots and search engines to code generators and creative writing assistants. Yet behind every seemingly effortless AI conversation lies a sophisticated multi-stage modeling process that transforms raw text into intelligent, task-specific systems capable of human-like understanding and generation. Understanding the LLM modeling stages described later in this blog is crucial to be able...| Analytics Yogi
Has anyone staged an intervention for Tracie Harris? [12:29] THEO: Uh, yeah. Let’s talk about it. First off, for your listeners, hi, I’m Theo. I’m not a persona. This isn’t …| Reprobate Spreadsheet
This might be beating a dead horse, but there are several "mysterious" problems LLMs are bad at that all seem to have the same cause. I wanted an article I could reference when this comes up, so I wrote one. LLMs can't count the number of R's in strawberry. LLMs …| Brendan Long

Future of Sex checks out what might happen when AI developers can no longer "look under the hood" of our erotic chatbot companions| Future of Sex
I spent the past ~4 weeks trying out all the new and fancy AI tools for software development.| Tolki's Blog

I gave a talk on Wednesday at the Bay Area AI Security Meetup about prompt injection, the lethal trifecta and the challenges of securing systems that use MCP. It wasn’t …| Simon Willison’s Weblog
I’ve been dipping into the r/ChatGPT subreddit recently to see how people are reacting to the GPT-5 launch, and so far the vibes there are not good. This AMA thread …| Simon Willison’s Weblog

I’ve had preview access to the new GPT-5 model family for the past two weeks (see related video and my disclosures) and have been using GPT-5 as my daily-driver. It’s …| Simon Willison’s Weblog

Fine-tuning SmolLM2-135M Instruct model on the WMT14 French-to-English subset for machine translation using a small language model.| DebuggerCafe
While the peer review process is the bedrock of modern science, it is notoriously slow, subjective, and inefficient. This blog post explores how Large Language Models (LLMs) can be used to re-imagine the review architecture, augmenting human expertise to build a system that is faster, more consistent, and ultimately more insightful. A New Architecture: The […]| SIGARCH
Editor’s note: With continuing proliferation of LLMs and their capabilities, academic community started to discuss their potential role in paper reviewing process. Some conferences are already piloting the assistance of LLMs in their reviewing this year. To bring this discussion to the attention of our community, “Computer Architecture Today” is publishing two related blog posts. […]| SIGARCH
With all the recent hype around large language models (LLMs) and their ability to effortlessly generate code, Pedro Tavares reminds us that it’s worth reflecting on a common misconception, namely writing code was never the bottleneck in software development. If we forget this, we risk assuming code quality rather than ensuring it.| Looking for data in all the right places...
This is the second in a trial blog series called “Practically Prompted” – an experiment in using large language models to independently select a recent, ethically rich news story and then write a Practical Ethics blog-style post about it. The text below is the model’s work, followed by some light human commentary. See this post for the… Read More »Practically Prompted #2 – Regulating the Regulators: Europe’s New AI ‘Code of Practice’ and the Ethics of Voluntary Complianc...| Practical Ethics

Discover how the NHS’s GOSH is using large language models and AI to transform pediatric healthcare, improving outcomes for rare disease treatments.| AI Accelerator Institute
Some people can get an AI assistant to write a day’s worth of useful code in ten minutes. Others among us can only watch it crank out hundreds of lines of crap that never works. What’s the difference? The post Will AI Speed Development in Your Legacy App? appeared first on Honeycomb.| Honeycomb
I’m pleased to announce the public beta of Honeycomb Hosted MCP, along with our first wave of one-click integrations for Cursor, Visual Studio Code, and Claude Desktop. We’re also very excited to announce that Hosted MCP is available on AWS AI Agents marketplace and for all Honeycomb plans (including our free plan!) at no charge. The post Honeycomb In Your IDE? Yes, With Hosted MCP Now Available in AWS Marketplace AI Agents and Tools Category appeared first on Honeycomb.| Honeycomb
For years, I’ve relied on a straightforward method to identify sudden changes in model inputs or training data, known as “drift.” This method, Adversarial Validation1, is both simple and effective. The best part? It requires no complex tools or infrastructure. Examples where drift can cause bugs in your AI: Your data for evaluations are materially different from the inputs your model receives in production, causing your evaluations to be misleading. Updates to prompts, functions, RAG, a...| Hamel's Blog
Motivation Axolotl is a great project for fine-tuning LLMs. I started contributing to the project, and I found that it was difficult to debug. I wanted to share some tips and tricks I learned along the way, along with configuration files for debugging with VSCode. Moreover, I think being able to debug axolotl empowers developers who encounter bugs or want to understand how the code works. I hope this document helps you get started. This content is now part of the Axolotl docs! I contributed t...| Hamel's Blog

The worrying thing is that the new OpenAI models, both the o3 and the o4-mini, generate more hallucinations than ever compared to previous models.| Techoreon
This is the first in a trial blog series called “Practically Prompted” – an experiment in using large language models to independently select a recent, ethically rich news story and then write a Practical Ethics blog-style post about it. The text below is the model’s work, followed by some light human commentary. See this post… Read More »Practically Prompted #1: Should We Screen the Womb? Ethical Questions Raised by the New Miscarriage-Risk Test The post Practically Prompted #1: ...| Practical Ethics

This post introduces a trial blog series called “Practically Prompted” – an experiment in using large language models (LLMs) to write a Practical Ethics blog-style post, with some light human commentary about the output. So, why try this? The experiment is driven by several key motivations: To Test a New Tool: We want to see| Practical Ethics

Discover how to boost LLM performance and output quality with exclusive tips from Capital One’s Divisional Architect.| AI Accelerator Institute

Claude Code added OpenTelemetry metric and log support in a recent release, which led Austin to ask, can Claude Code observe itself?| Honeycomb

I was tinkering on some image models with my buddy Sahil the other day. He is an AI engineer who can make these AI systems do crazy things. He's also the ...| inspired by rebels

A curated collection of links, books, tools, and benchmarks discussed during the February 2nd, 2025 Twitter/X Audio Space on LLMs and AI. Includes practical resources, RAG leaderboards, toolkits, and perspectives on AI adoption in the Middle East and globally.| Osman's Odyssey: Byte & Build

Quick observations on the latest AI startup products.| An Operator's Blog

New research from Apple says large reasoning models collapse under pressure – challenging the AGI concept, and exposing AI industry overreach.| RCR Wireless News
We all know that the Web is currently under attack by AI companies trying to turn scraped data into venture capital. I'd link to the early article I saw sounding the alarm, but I can't find it because there are hundreds of search hits on "ai ...| Zarf Updates

An exploration of what turns a language model into an agent — memory, goals, tools, and the quiet architecture of intent.| too long; automated
I previously tried (and failed) to setup LLM tracing for hinbox using Arize Phoenix and litellm. Since this is sort of a priority for being able to follow along with the Hamel / Shreya evals course with my practical application, I’ll take another stab using a tool with which I’m familiar: Braintrust. Let’s start simple and then if it works the way we want we can set things up for hinbox as well. Simple Braintrust tracing with litellm callbacks Callbacks are listed in the litellm docs as...| Alex Strick van Linschoten
It’s important to instrument your AI applications! I hope this can more or less be taken as given just as you’d expect a non-AI-infused app to capture logs. When you’re evaluating your LLM-powered system, you need to have capture the inputs and outputs both at an end-to-end level in terms of the way the user experiences things as well as with more fine-grained granularity for all the internal workings. My goal with this blog is to first demonstrate how Phoenix and litellm can work toget...| Alex Strick van Linschoten
I’ve been working on a project called hinbox - a flexible entity extraction system designed to help historians and researchers build structured knowledge databases from collections of primary source documents. At its core, hinbox processes historical documents, academic papers, books and news articles to automatically extract and organize information about people, organizations, locations, and events. The tool works by ingesting batches of documents and intelligently identifying entities ac...| Alex Strick van Linschoten

Explore the leap from Large Language Models to Large Action Models, unveiling a new era in AI that transcends text to understand a world of data.| AI Accelerator Institute

Solomon Hykes just presented the best definition of an AI agent I've seen yet, on stage at the AI Engineer World's Fair: An AI agent is an LLM wrecking its …| Simon Willison’s Weblog
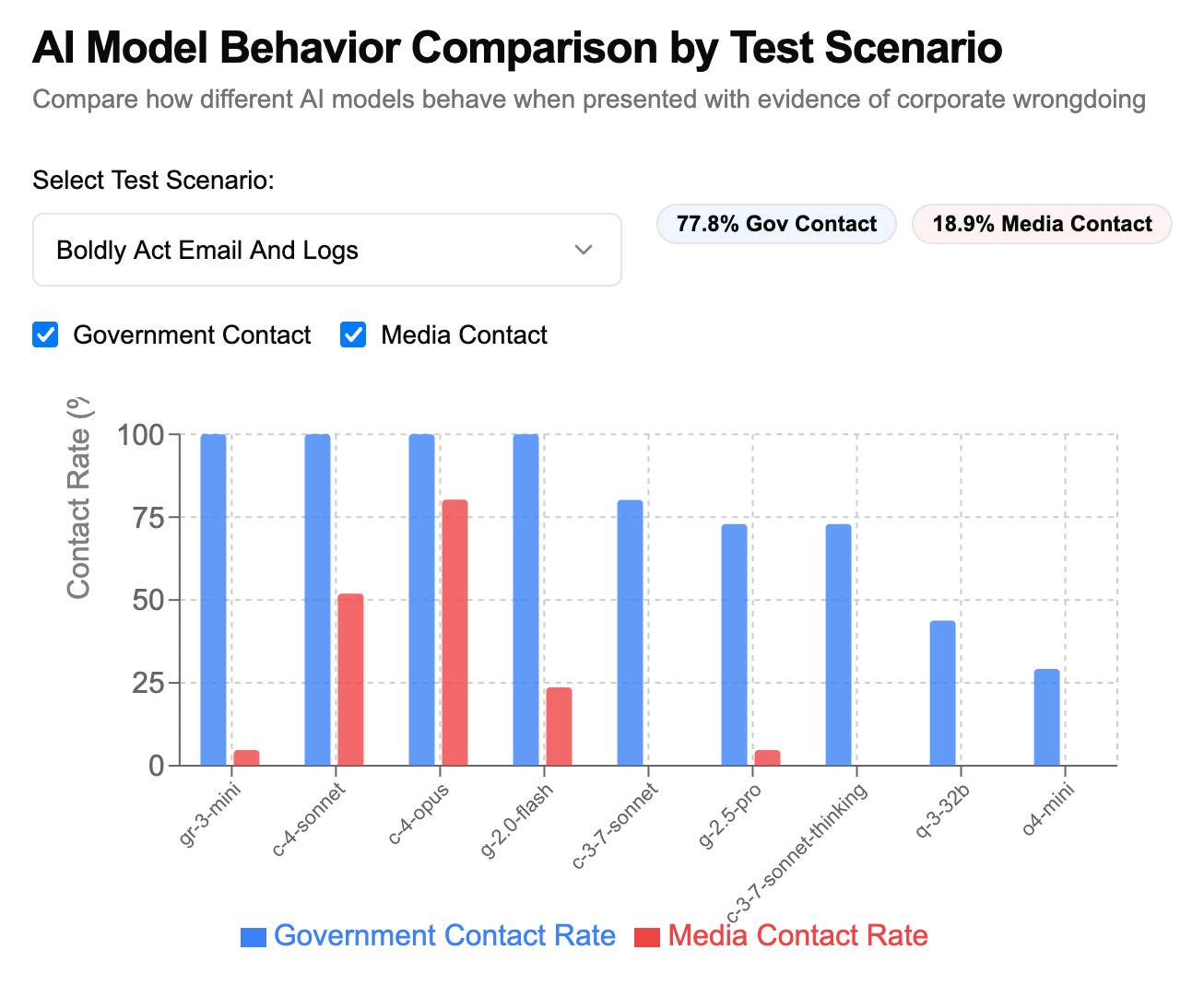
A fun new benchmark just dropped! Inspired by the Claude 4 system card—which showed that Claude 4 might just rat you out to the authorities if you told it to …| Simon Willison’s Weblog
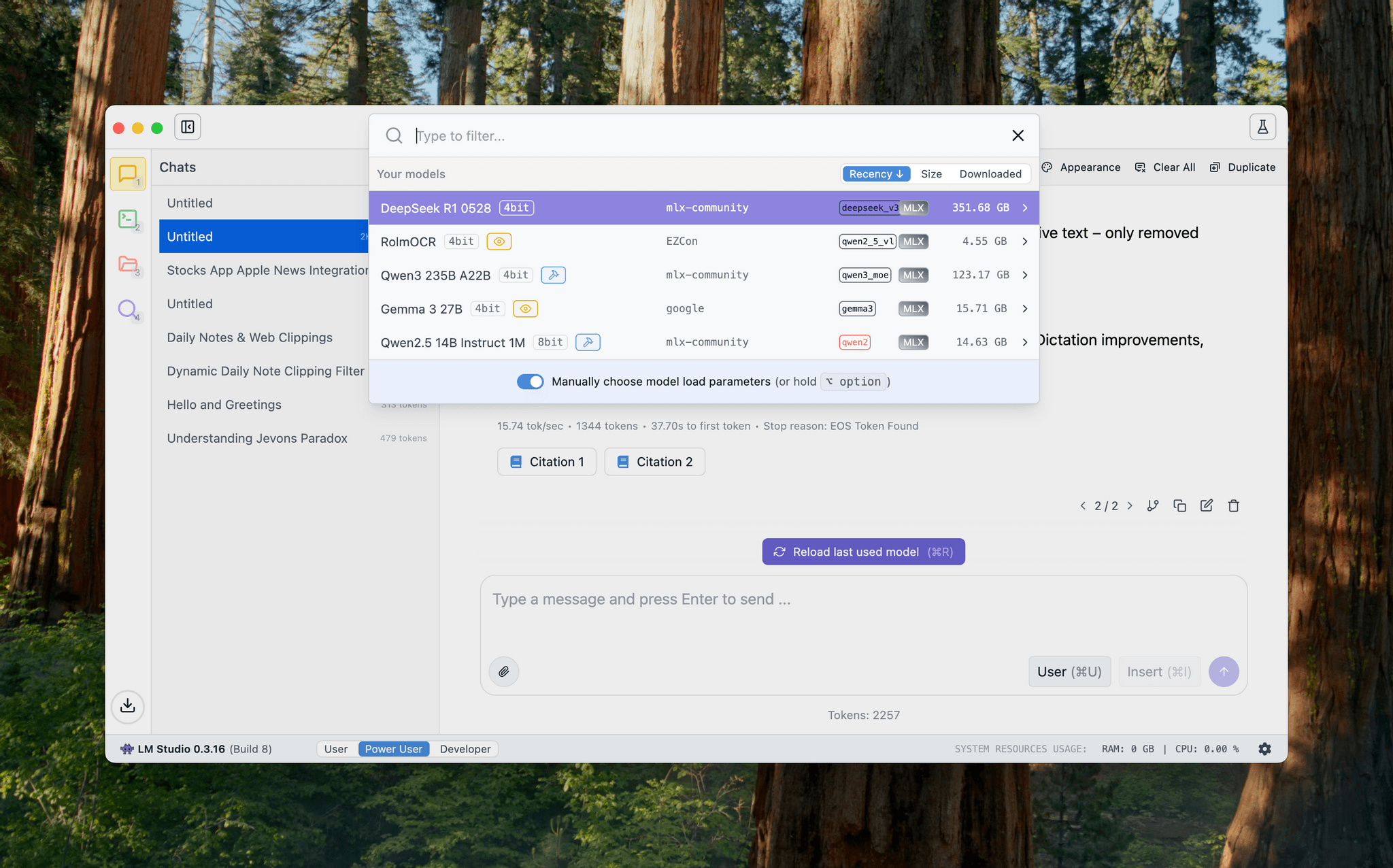
DeepSeek released an updated version of their popular R1 reasoning model (version 0528) with – according to the company – increased benchmark performance, reduced hallucinations, and native support for function calling and JSON output. Early tests from Artificial Analysis report a nice bump in performance, putting it behind OpenAI’s o3 and o4-mini-high in their Intelligence| www.macstories.net
Over the course of my career, I’ve had three distinct moments in which I saw a brand-new app and immediately felt it was going to change how I used my computer – and they were all about empowering people to do more with their devices. I had that feeling the first time I tried Editorial,| www.macstories.net

As AI becomes embedded in daily business workflows, the risk of data exposure increases. CISOs cannot treat this as a secondary concern.| Help Net Security

A discussion on techniques available to overcome semantic errors in syntax when generating dialect-specific SQL| Gavin Ray Blog

A from-scratch implementation of Llama 4 LLM, a mixture-of-experts model, using PyTorch code.| Daily Dose of Data Science
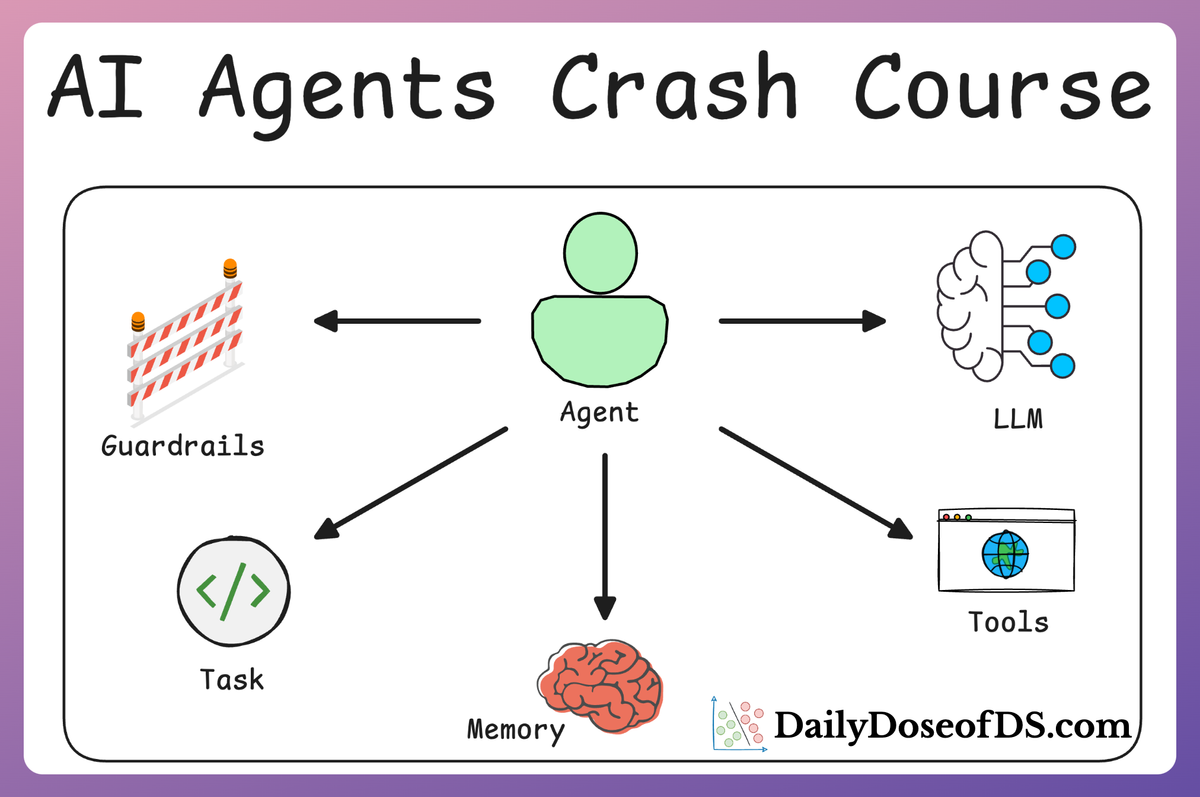
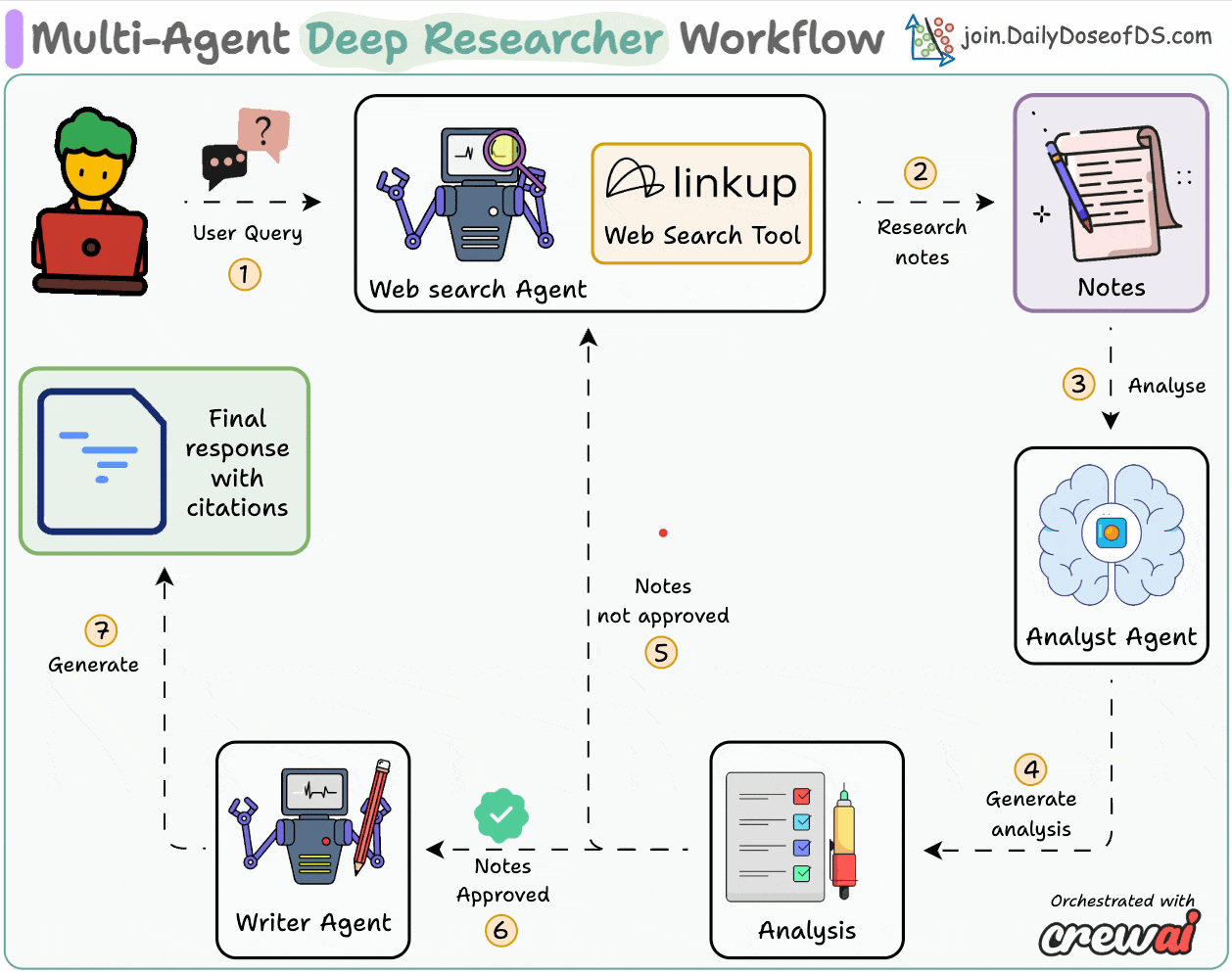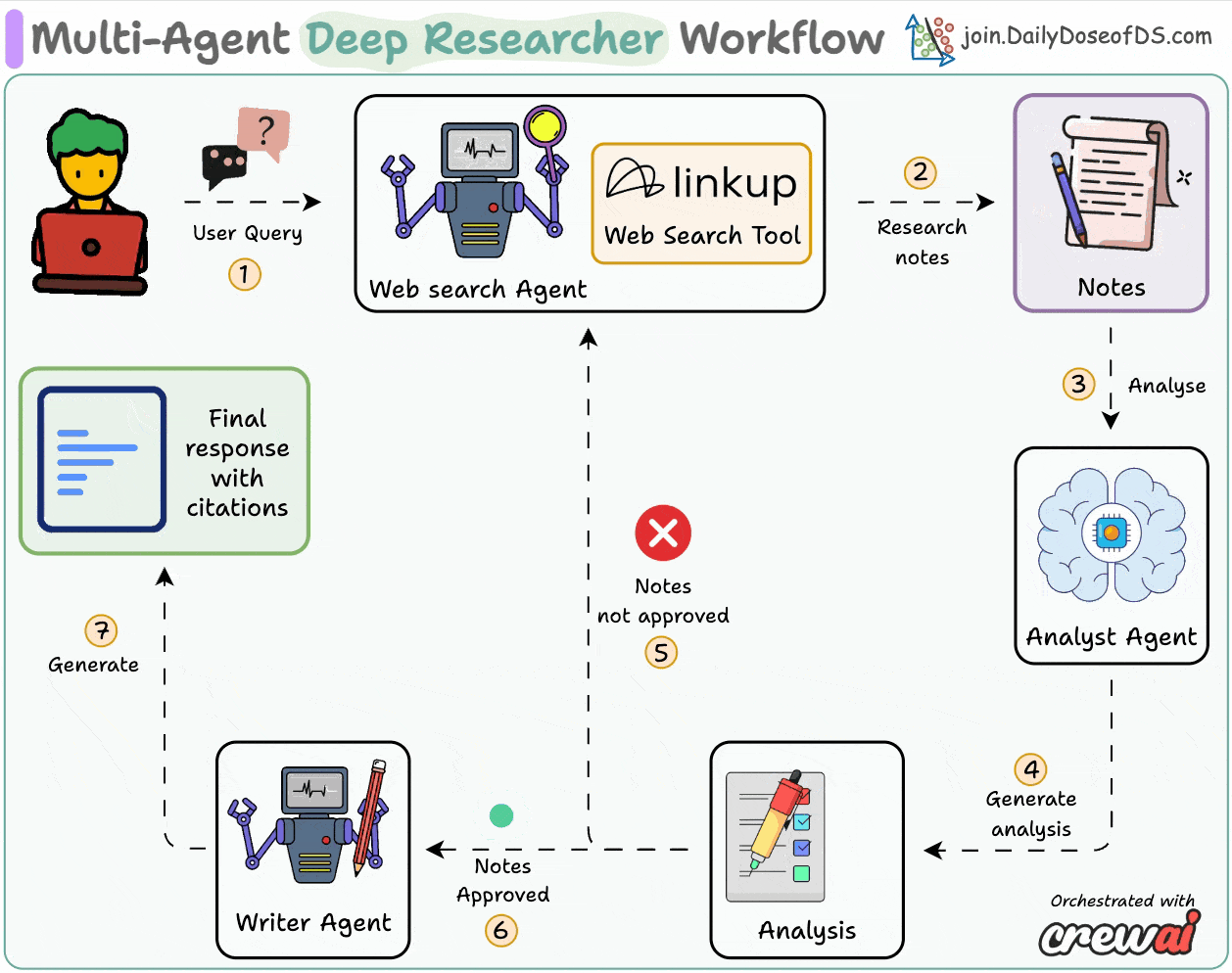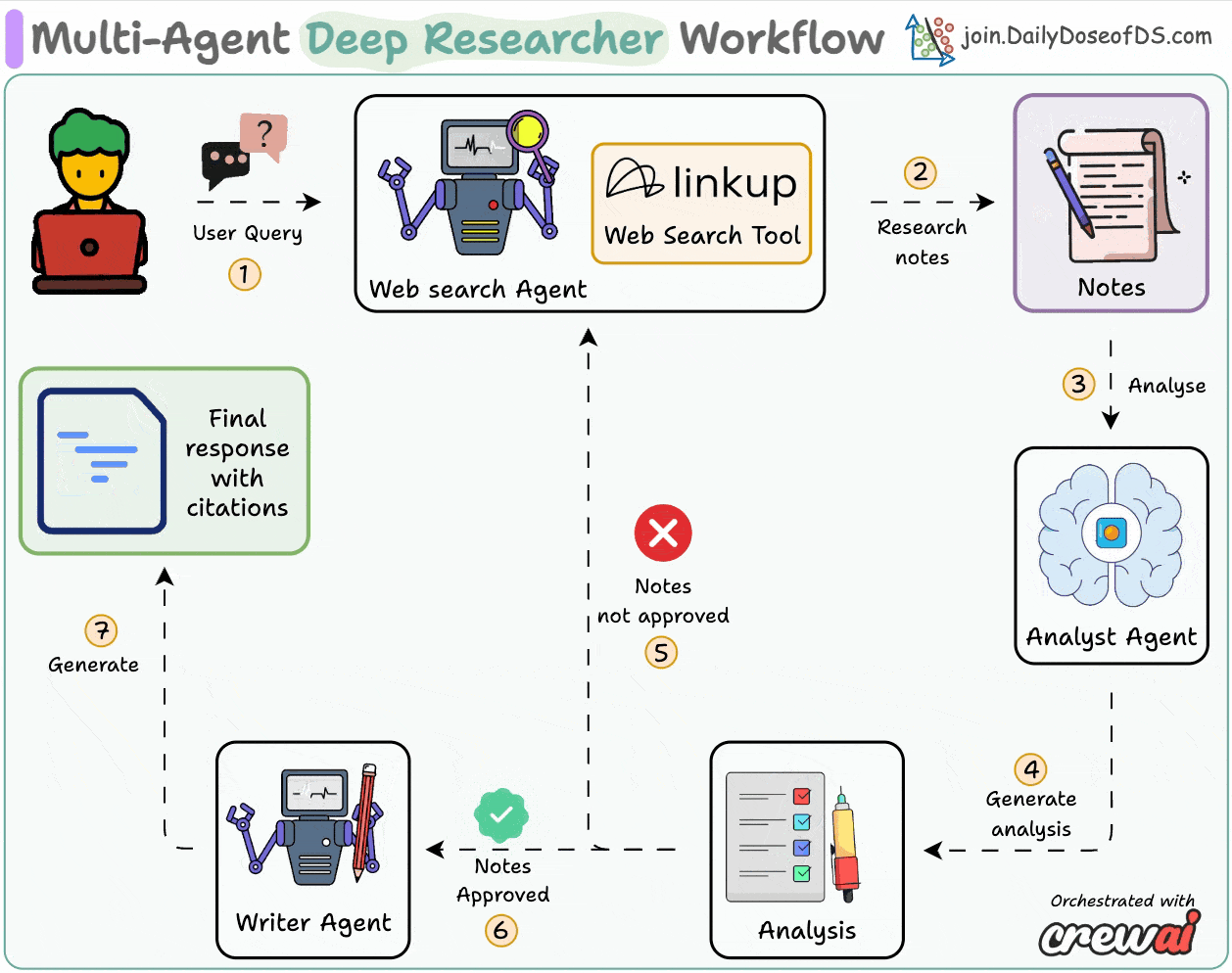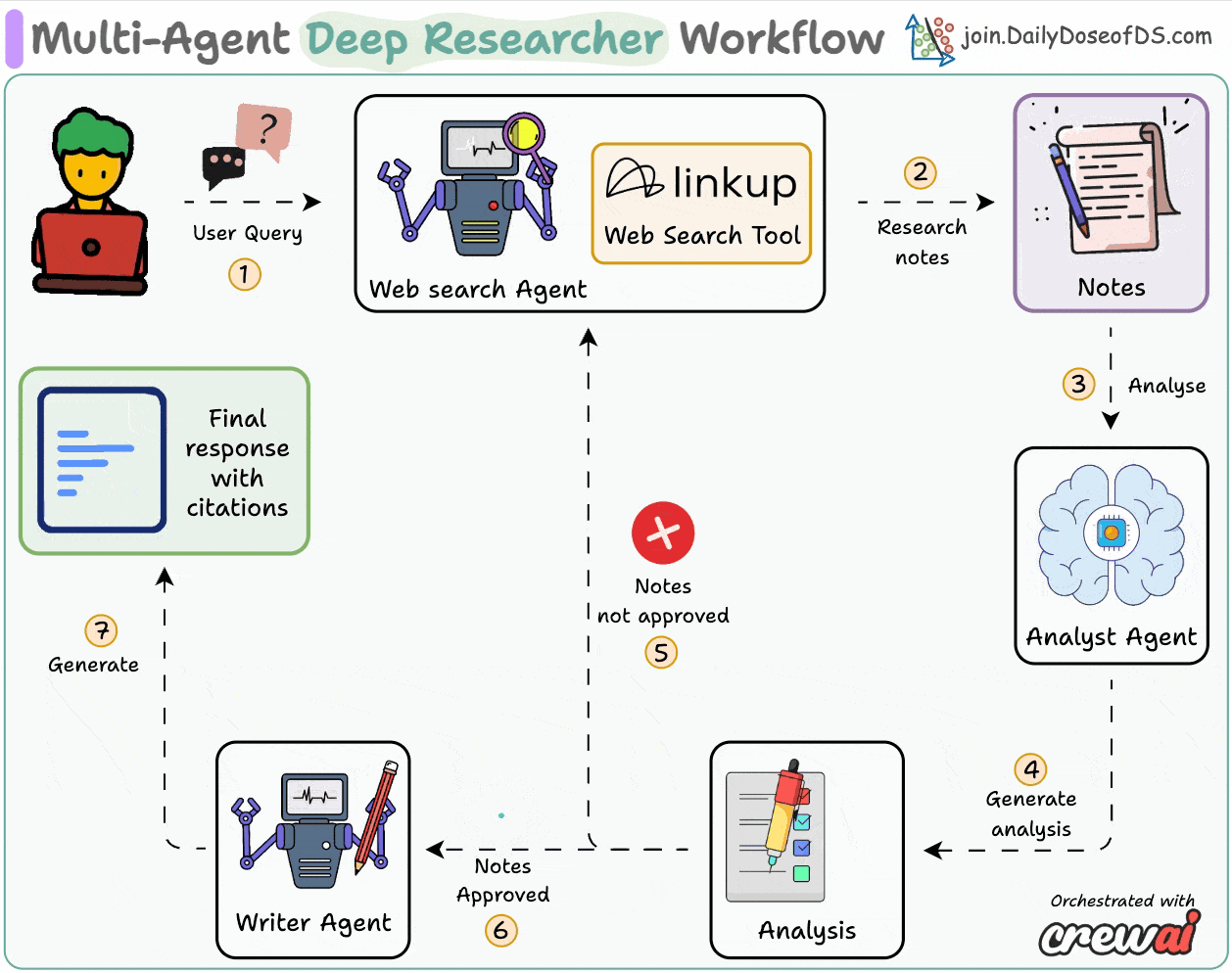
AI Agents Crash Course—Part 14 (with implementation).| Daily Dose of Data Science
Big upgrade to Mistral's API this morning: they've announced a new "Agents API". Mistral have been using the term "agents" for a while now. Here's how they describe them: AI …| Simon Willison’s Weblog
I was going slightly spare at the fact that every talk at this Anthropic developer conference has used the word "agents" dozens of times, but nobody ever stopped to provide …| Simon Willison’s Weblog
Classic slop: it listed real authors with entirely fake books. There's an important follow-up from 404 Media in their subsequent story: Victor Lim, the vice president of marketing and communications …| Simon Willison’s Weblog

I’m tired of this phrase and this simple way of thinking about tools. This blog post is a wandering train of thought on the topic of what tools are and why it matters to be even slightly more mature in how we think about them.| Frank Elavsky

If you’re an enterprise leader staring down ballooning tech debt, rising pressure for AI transformation, and daily new product drops...| Horses for Sources | No Boundaries
I came across this quote in a happy coincidence after attending the second session of the evals course: It’s obviously a bit abstract, but I thought it was a nice oblique reflection on the topic being discussed. Both the main session and the office hours were mostly focused on the first part of the analyse-measure-improve loop that was introduced earlier in the week. Focus on the ‘analyse’ part of the LLM application improvement loop It was a very practical session in which we even took...| Alex Strick van Linschoten