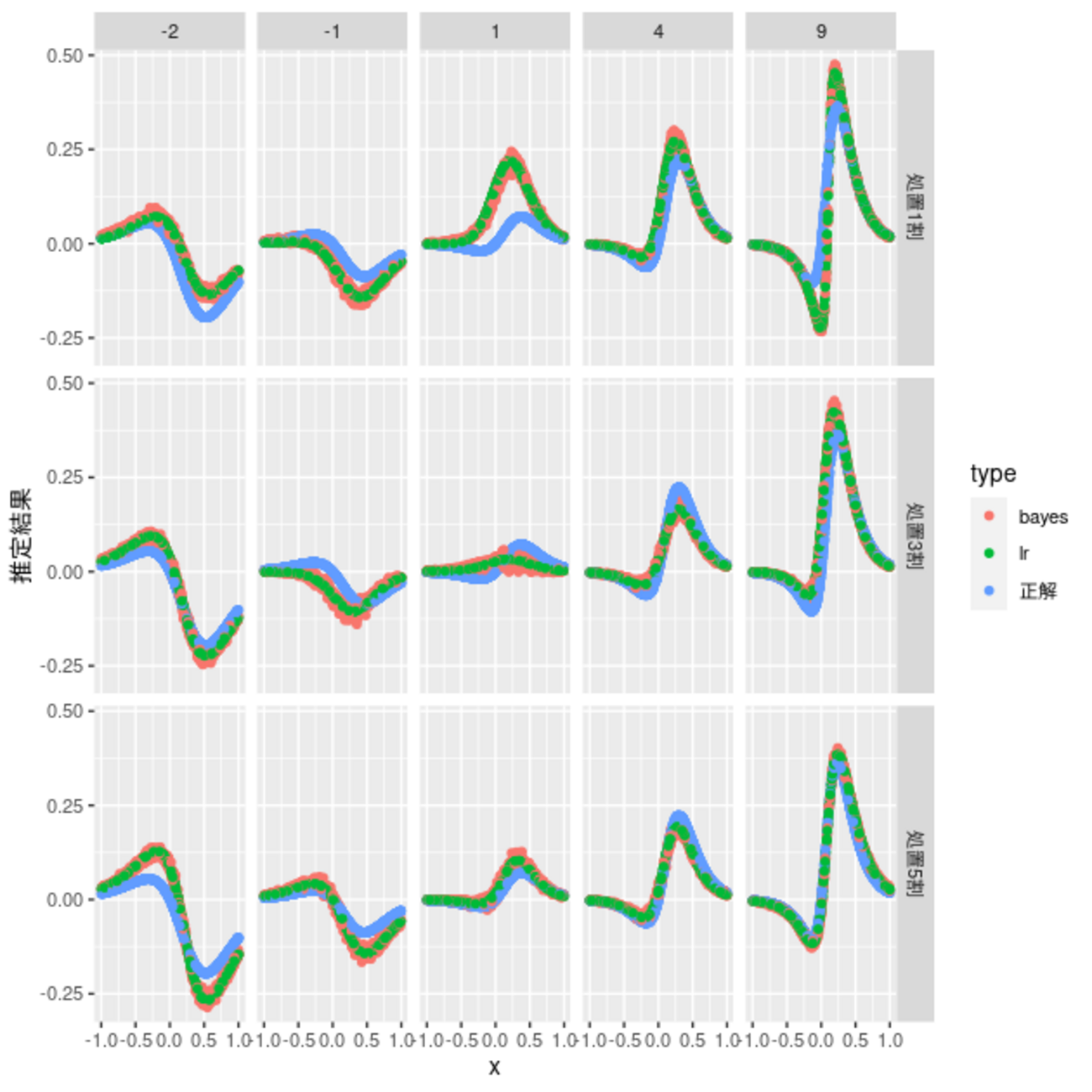
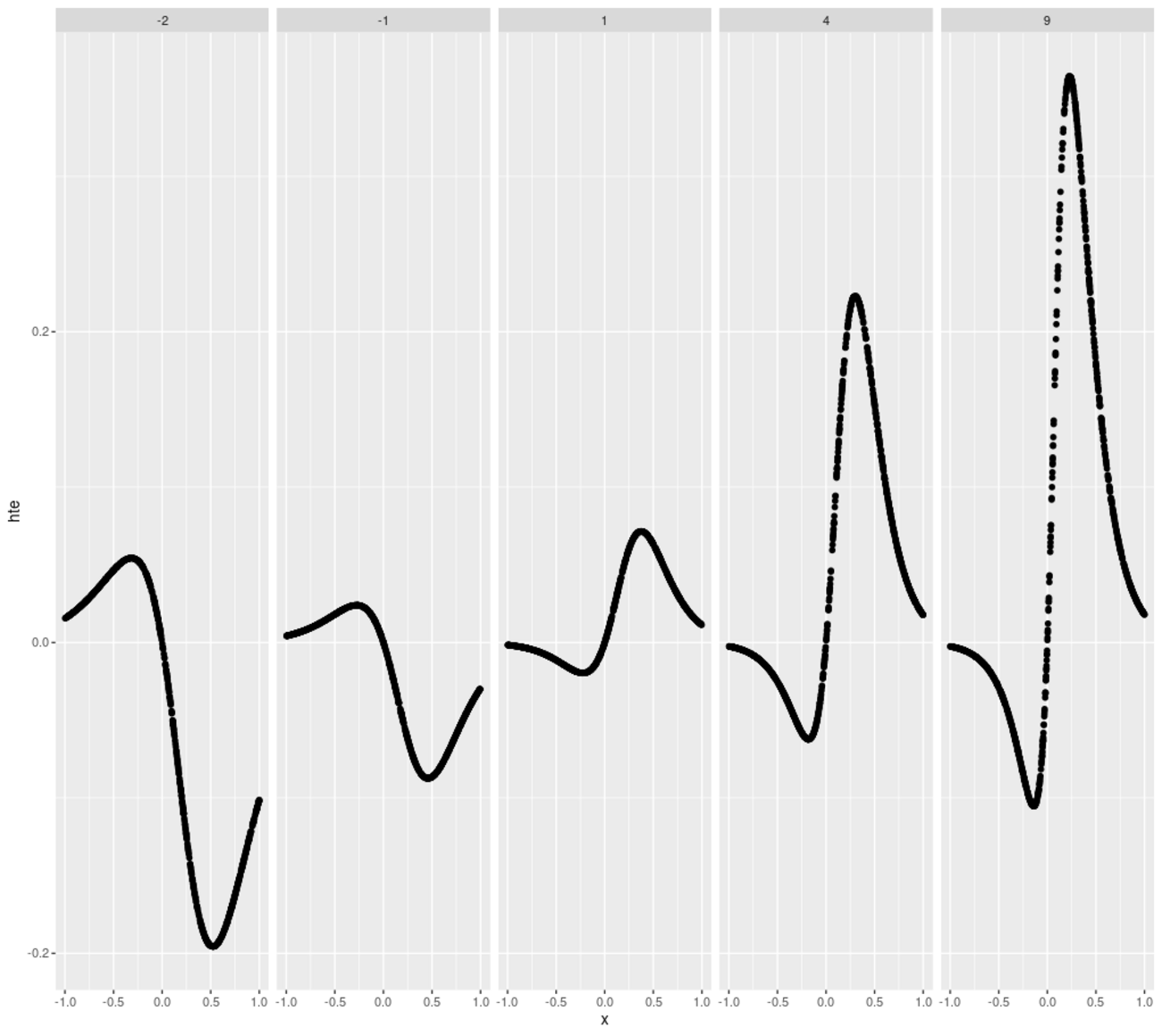
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回も前回に引き続きアウトカムが2値のHeterogeneous Treatment Effects(HTE)に関する簡単な検証実験を扱います。ベイズを利用してT-Learnerに事前知識を組み込むことで推定が改善されるのかを調べたものです。コードはRとStanです。前回の記事は以下。 analytics.livesense.co.jp データ データは前回の記事で利...| LIVESENSE Data Analytics Blog
こんにちは、リブセンスでデータサイエンティストをしている北原です。今回はStanを使ったレコメンデーション用FM(Factorization Machines)を扱います。 FMはシンプルなモデルなのでStanで簡単に実装することができます。しかし、レコメンデーションで使う場合はスパースデータに対応したものにしないと無駄な計算が多く計算に非常に時間がかかってしまったりメモリを大...| LIVESENSE Data Analytics Blog
前回に続きコンテキストを扱えるFactorization Machines(FM)をモデルとした、Bayesian Personalized Ranking(BPR)(以下ではBPR-FMと略)を紹介します。今回はBPR-FMのモデルパラメータ推定の実装の話をします。実装にはJuliaを使います。モデルやアルゴリズムの詳細については下記の記事をご参照ください。| LIVESENSE Data Analytics Blog
今回から3回にわたって暗黙的評価データを使ったコンテキスト対応レコメンデーションの紹介をしようと思います。具体的には、コンテキストを扱えるFactorization Machines(FM)をモデルとした、Bayesian Personalized Ranking(BPR)を紹介します。今回はアルゴリズムとモデル、次回は実装、最後は実務での応用の話をします。| LIVESENSE Data Analytics Blog
こんにちは、リブセンスで統計や機械学習関係の仕事をしている北原です。今回はレコメンデーションにも使えるFactorization Machines(FM)の効率的な学習アルゴリズムの紹介です。実装にはJuliaを使います。 実務で必要な要件を満たす機械学習ライブラリがなくて、機械学習モデルをカスタマイズすることってありますよね。最近はTensorFlowのような機械学習フレームワーク...| LIVESENSE Data Analytics Blog
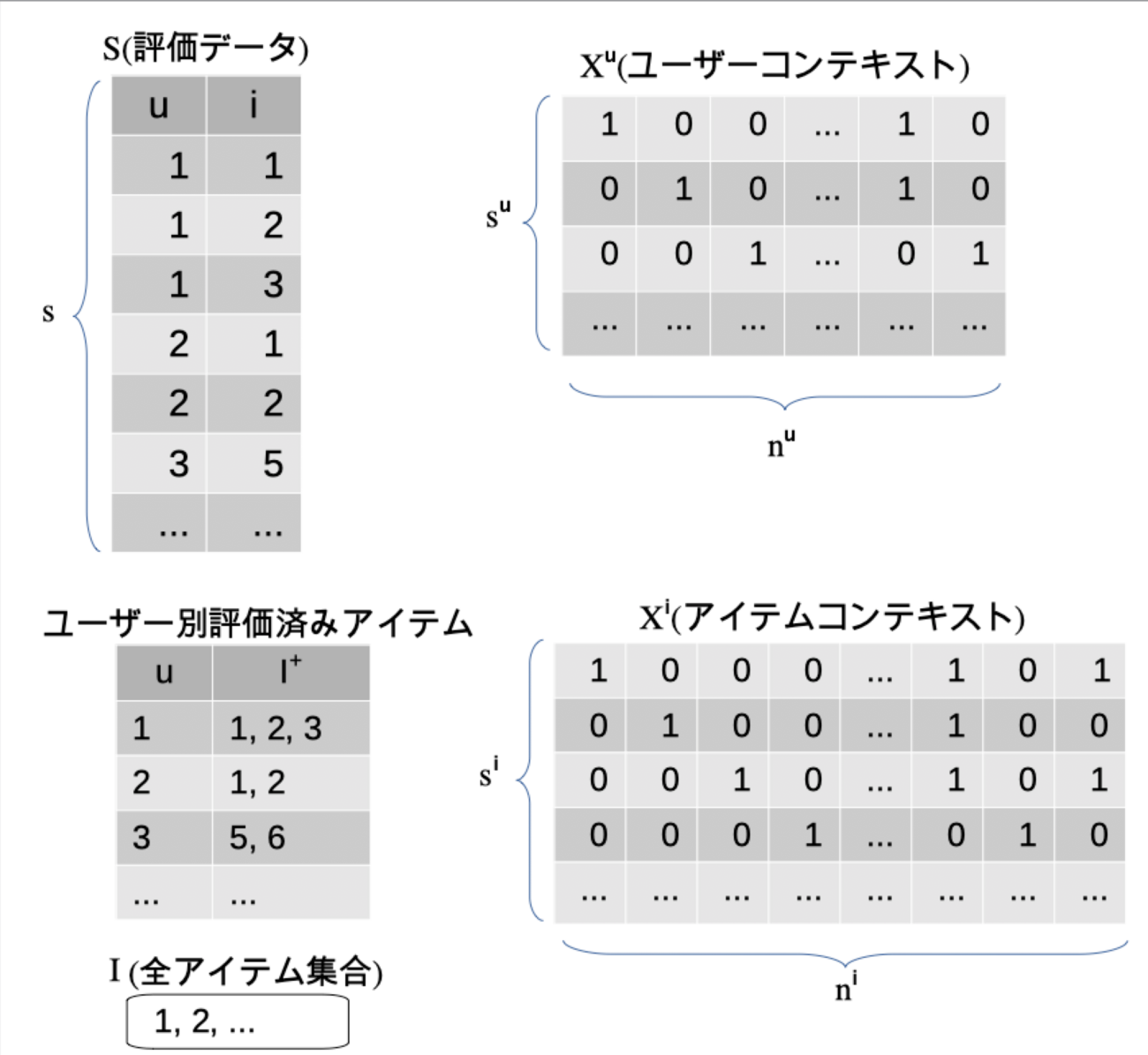
こんにちは、リブセンスで機械学習関係の仕事をしている北原です。 弊社の転職ナビアプリには求人をレコメンドする機能が実装されていて、求人の好みを回答すると各ユーザーに合った求人がレコメンドされるようになっています。このサービスではいくつかのレコメンドアルゴリズムが使われているのですが、その中にBPMF(Bayesian Probabilistic Matrix Factorization)というア...| LIVESENSE Data Analytics Blog