
Instrumental convergence and power-seeking (Part 3: Turner et al.) - Reflective altruism
The most-discussed modern power-seeking theorem, due to Alex Turner and colleagues, also won't do the trick| Reflective altruism
The most-discussed modern power-seeking theorem, due to Alex Turner and colleagues, also won't do the trick| Reflective altruism
In this post we break down Microsoft's Reinforcement Pre-Training, which scales up reinforcement learninng with next-token reasoning The post Microsoft’s Reinforcement Pre-Training (RPT) – A New Direction in LLM Training? appeared first on AI Papers Academy.| AI Papers Academy
DeepSeekMath is the fundamental GRPO paper, the reinforcement learning method used in DeepSeek-R1. Dive in to understand how it works The post GRPO Reinforcement Learning Explained (DeepSeekMath Paper) appeared first on AI Papers Academy.| AI Papers Academy
Explore DAPO, an innovative open-source Reinforcement Learning paradigm for LLMs that rivals DeepSeek-R1 GRPO method. The post DAPO: Enhancing GRPO For LLM Reinforcement Learning appeared first on AI Papers Academy.| AI Papers Academy

Discover the key machine learning fraud prevention benefits.| Signifyd
I split this off from clickbait bandits for discoverability, and because it has grown larger than its source notebook. Figure 1 Since the advent of the LLM era, the term human reward hacking has become salient. This is because we fine tune lots of LLMs using reinforcement learning, and RL algorithms are notoriously prone to “cheating” in a manner we interpret as “reward hacking”. Things I have been reading on this theme: Benton et al. (2024), Greenblatt et al. (2024), Laine et al. (2...| The Dan MacKinlay stable of variably-well-consider’d enterprises
GPT-5 and GPT-5 Thinking are large language models recently realeased by OpenAI, after a long series of annoucements and hype. Results on benchmarks are impressive. How good these reasoning models are in chess? Using a simple four-move sequence, I suceed to force GPT-5 and GPT-5 Thinking into an illegal move. Basically as GPT3.5, GPT4, DeepSeek-R1, o4-mini, o3 (see all my posts). There are other concerning insights… Though it is a very specific example, it is not a good sign.| Mathieu Acher
o3 and o4-mini are large language models recently realeased by OpenAI and augmented with chain-of-thought reinforcement learning, designed to “think before they speak” by generating explicit, multi-step reasoning before producing an answer. How good these reasoning models are in chess? Using a simple four-move sequence, I suceed to force o3 into an illegal move, and across multiple matches both o3 and o4-mini struggle dramatically, by generating illegal moves in over 90% of cases and even...| blog.mathieuacher.com
AI models are often overconfident. A new MIT training method teaches them self-doubt, improving reliability and making them more trustworthy. The post A new way to train AI models to know when they don’t know first appeared on TechTalks.| TechTalks
I come to the conclusion that DeepSeek-R1 is worse than a 5 years-old version of GPT-2 in chess… The very recent, state-of-art, open-weights model DeepSeek R1 is breaking the 2025 news, excellent in many benchmarks, with a new integrated, end-to-end, reinforcement learning approach to large language model (LLM) training. I am personally very excited about this model, and I’ve been working on it in the last few days, confirming that DeepSeek R1 is on-par with GPT-o for several tasks. Yet, ...| blog.mathieuacher.com

This is a 3 part series of Deep Q-Learning, which is written such that undergrads with highschool maths should be able to understand and hit the ground running on their deep learning projects. This…| Bruceoutdoors Blog of Blots

This is a 3 part series of Deep Q-Learning, which is written such that undergrads with highschool maths should be able to understand and hit the ground running on their deep learning projects. This…| Bruceoutdoors Blog of Blots
As the 2010’s draw to a close, it’s worth taking a look back at the monumental progress that has been made in Deep Learning in this decade.[1] Driven by the development of ever-more powerful comput| Leo Gao
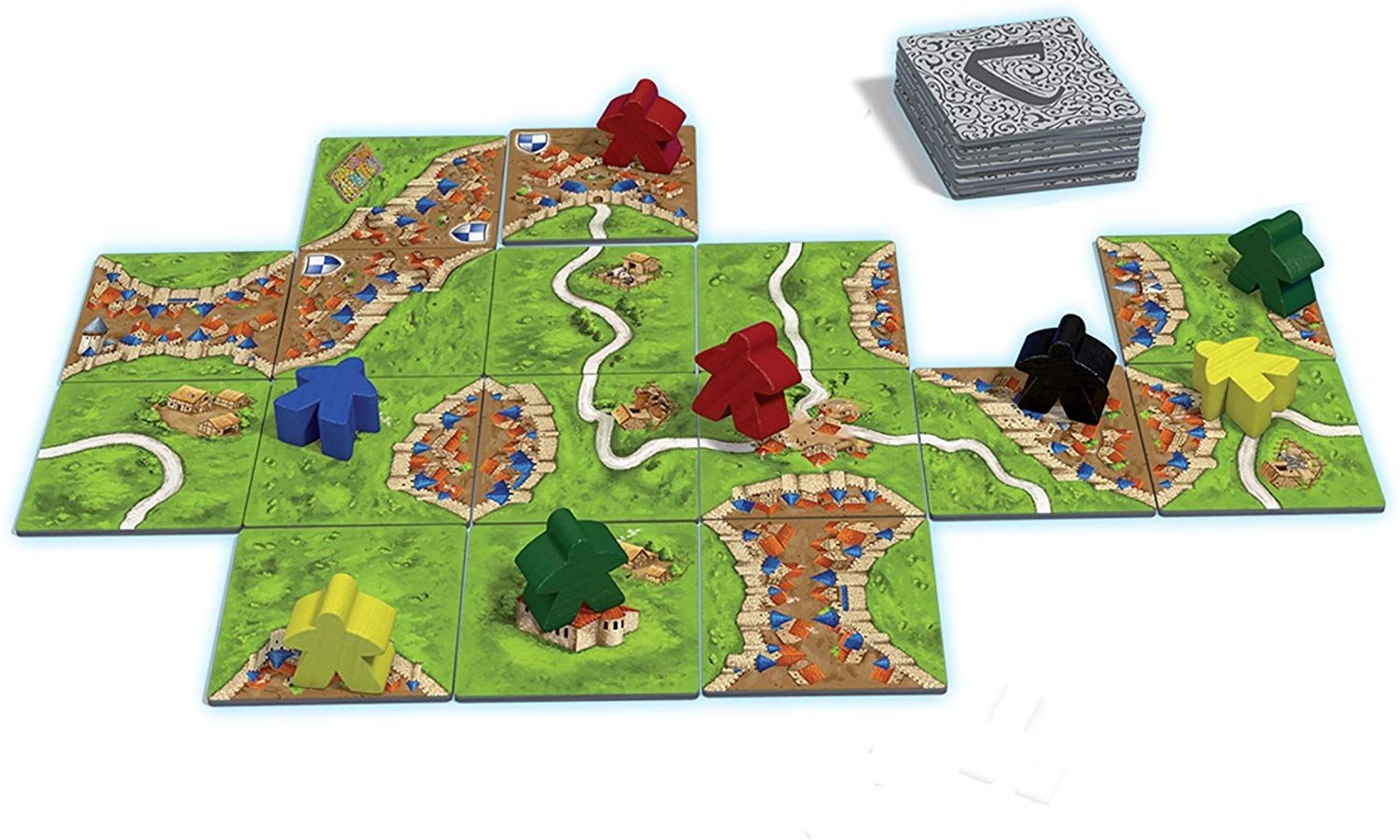
I describe my process of programming the board game Carcassonne in Python, and my preparations for using this game as a reinforcement learning environment.| Wingedsheep: Artificial Intelligence Blog
