
PyTorch
PyTorch Foundation is the deep learning community home for the open source PyTorch framework and ecosystem.| PyTorch
We now live in a world where ML workflows (pre-training, post training, etc) are heterogeneous, must contend with hardware failures, are increasingly asynchronous and highly dynamic. Traditionally, PyTorch has relied on an HPC-style multi-controller model, where multiple copies of the same script are launched across different machines, each running its own instance of the application (often referred to as SPMD). ML workflows are becoming more complex: pre-training might combine advanced par...| pytorch.org
Today, we are pleased to announce a new advanced CUDA feature, CUDA Graphs, has been brought to PyTorch. Modern DL frameworks have complicated software stacks that incur significant overheads associated with the submission of each operation to the GPU. When DL workloads are strong-scaled to many GPUs for performance, the time taken by each GPU operation diminishes to just a few microseconds and, in these cases, the high work submission latencies of frameworks often lead to low utilization of ...| pytorch.org
Key takeaways:| pytorch.org
We are excited to announce the release of PyTorch® 2.9 (release notes)! This release features: Updates to the stable libtorch ABI for third-party C++/CUDA extensions Symmetric memory that enables easy...| PyTorch
PyTorch Conference: October 22–23, 2025, San Francisco, CA Open Source AI Week’s flagship event, PyTorch Conference 2025, brings together AI pioneers, researchers, developers, and startup founders for keynotes, technical talks, tutorials,...| PyTorch
We’re excited to welcome the first cohort of PyTorch Ambassadors ever! The new PyTorch Ambassador Program highlights and supports passionate community leaders who educate, advocate for, build with PyTorch Foundation...| PyTorch
TLDR: Efficient full-parameter fine-tuning of GPT-OSS-20B & Qwen3-14B models on a single NVIDIA GH200 and Llama3-70B on four NVIDIA GH200 Superchips, while delivering up to 600 TFLOPS training throughput. Table...| PyTorch
As generative AI evolves beyond static prompts, this summit brings together top researchers, builders, and strategists to explore the future of goal-directed agents built on open source and open standards....| PyTorch
The PyTorch Foundation, a community-driven hub supporting the open source PyTorch framework and a broader portfolio of innovative open source AI projects, is announcing today that Snowflake, the AI Data...| PyTorch
TL;DR Combining 2:4 sparsity with quantization offers a powerful approach to compress large language models (LLMs) for efficient deployment, balancing accuracy and hardware-accelerated performance, but enhanced tool support in GPU...| PyTorch
The Measuring Intelligence Summit on October 21 in San Francisco, co-located with PyTorch Conference 2025, brings together experts in AI evaluation to discuss the critical question: how do we effectively measure intelligence in both foundation models and agentic systems? | pytorch.org
PyTorch now offers native quantized variants of Phi4-mini-instruct, Qwen3, SmolLM3-3B and gemma-3-270m-it through a collaboration between the TorchAO team, ExecuTorch team, and Unsloth! These models leverage int4 and float8 quantization...| PyTorch
On October 21st, the AI Infra Summit comes to San Francisco and PyTorch Conference 2025, bringing together experts building the infrastructure behind the latest explosion in AI innovation. This half-day...| PyTorch
PyTorch 2.8 has just been released with a set of exciting new features, including a limited stable libtorch ABI for third-party C++/CUDA extensions, high-performance quantized LLM inference on Intel CPUs with native PyTorch, experimental Wheel Variant Support, inductor CUTLASS backend support, etc. Among all these features, one of the great things is that PyTorch can now provide competitive Large Language Model (LLM) low-precision performance on Intel Xeon platform as compared with other popu...| pytorch.org
PyTorch Foundation is the deep learning community home for the open source PyTorch framework and ecosystem.| PyTorch
Intel announces a major enhancement for distributed training in PyTorch 2.8: the native integration of the XCCL backend for Intel® GPUs (Intel® XPU devices). This provides support for Intel® oneAPI Collective Communications Library (oneCCL) directly into PyTorch, giving developers a seamless, out-of-the-box experience to scale AI workloads on Intel hardware. | pytorch.org
Key takeaways:| pytorch.org
As training jobs become larger, the likelihood of failures such as preemptions, crashes, or infrastructure instability rises. This can lead to significant inefficiencies in training and delays in time-to-market. At these large scales, efficient distributed checkpointing is crucial to mitigate the negative impact of failures and to optimize overall training efficiency (training goodput).| pytorch.org
tldr: 1.22x – 1.28x training acceleration with MXFP8, equivalent convergence compared to BF16.| pytorch.org
Key Takeaways:| pytorch.org
We’re thrilled to announce that the Kubeflow Trainer project has been integrated into the PyTorch ecosystem! This integration ensures that Kubeflow Trainer aligns with PyTorch’s standards and practices, giving developers a reliable, scalable, and community-backed solution to run PyTorch on Kubernetes.| pytorch.org
Access and install previous PyTorch versions, including binaries and instructions for all platforms.| PyTorch
Attention, as a core layer of the ubiquitous Transformer architecture, is a bottleneck for large language models and long-context applications. FlashAttention (and FlashAttention-2) pioneered an approach to speed up attention on GPUs by minimizing memory reads/writes, and is now used by most libraries to accelerate Transformer training and inference. This has contributed to a massive increase in LLM context length in the last two years, from 2-4K (GPT-3, OPT) to 128K (GPT-4), or even 1M (Ll...| pytorch.org

We are excited to announce the release of PyTorch® 2.7 (release notes)! This release features:| pytorch.org
PyTorch* 2.6 has just been released with a set of exciting new features including torch.compile compatibility with Python 3.13, new security and performance enhancements, and a change in the default parameter for torch.load. PyTorch also announced the deprecation of its official Anaconda channel.| pytorch.org
We are excited to announce the release of PyTorch® 2.6 (release notes)! This release features multiple improvements for PT2: torch.compile can now be used with Python 3.13; new performance-related knob torch.compiler.set_stance; several AOTInductor enhancements. Besides the PT2 improvements, another highlight is FP16 support on X86 CPUs.| pytorch.org
Transitioning from torch.distributed.launch to torchrun¶| pytorch.org
Wrapper for C++ torch::jit::Module with methods, attributes, and parameters.| pytorch.org
torch.device¶| pytorch.org
Implements data parallelism at the module level.| pytorch.org
by| PyTorch
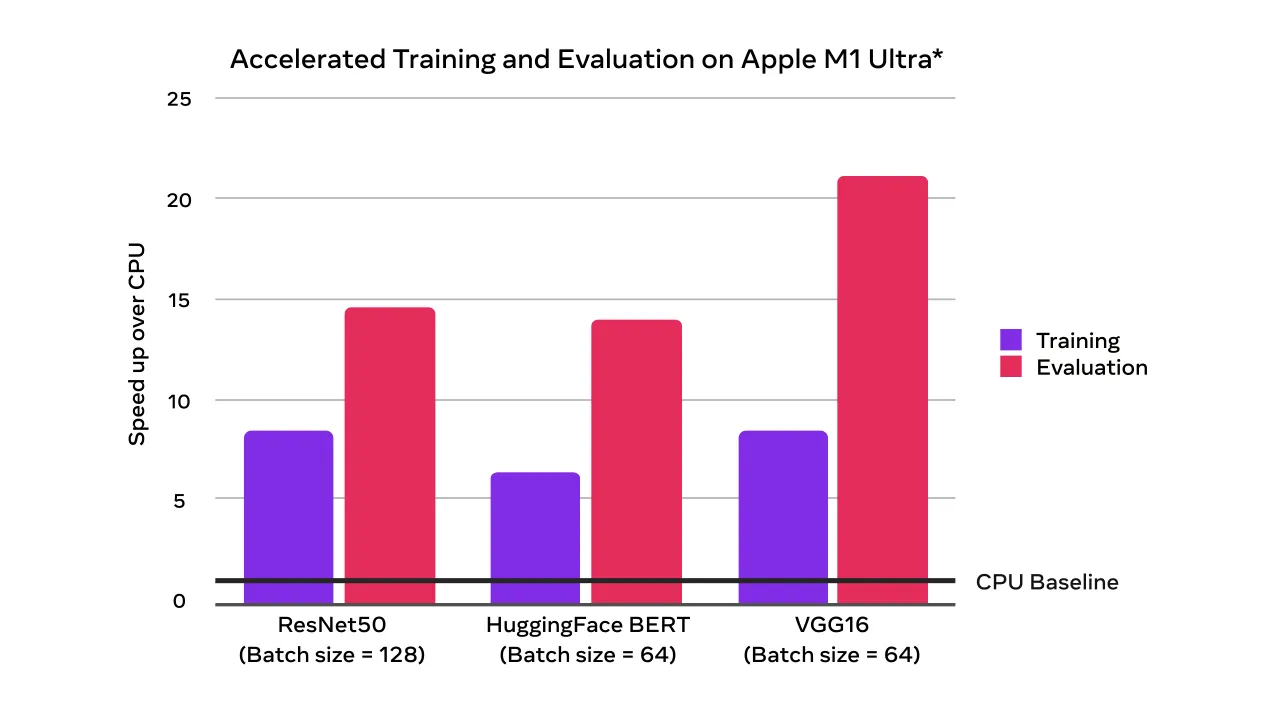
In collaboration with the Metal engineering team at Apple, we are excited to announce support for GPU-accelerated PyTorch training on Mac. Until now, PyTorch training on Mac only leveraged the CPU, but with the upcoming PyTorch v1.12 release, developers and researchers can take advantage of Apple silicon GPUs for significantly faster model training. This unlocks the ability to perform machine learning workflows like prototyping and fine-tuning locally, right on Mac.| pytorch.org
Efficient training of modern neural networks often relies on using lower precision data types. Peak float16 matrix multiplication and convolution performance is 16x faster than peak float32 performance on A100 GPUs. And since the float16 and bfloat16 data types are only half the size of float32 they can double the performance of bandwidth-bound kernels and reduce the memory required to train a network, allowing for larger models, larger batches, or larger inputs. Using a module like torch.am...| pytorch.org
Most deep learning frameworks, including PyTorch, train with 32-bit floating point (FP32) arithmetic by default. However this is not essential to achieve full accuracy for many deep learning models. In 2017, NVIDIA researchers developed a methodology for mixed-precision training, which combined single-precision (FP32) with half-precision (e.g. FP16) format when training a network, and achieved the same accuracy as FP32 training using the same hyperparameters, with additional performance be...| pytorch.org
Join us at PyTorch Conference in San Francisco, October 22-23. CFP open now! Learn more.| PyTorch
torch.Tensor¶| pytorch.org
Per-parameter options¶| pytorch.org
Applies Batch Normalization over a 4D input.| pytorch.org

This post is the second part of a multi-series blog focused on how to accelerate generative AI models with pure, native PyTorch. We are excited to share a breadth of newly released PyTorch performance features alongside practical examples to see how far we can push PyTorch native performance. In part one, we showed how to accelerate Segment Anything over 8x using only pure, native PyTorch. In this blog we’ll focus on LLM optimization.| PyTorch
This criterion computes the cross entropy loss between input logits| pytorch.org
Debugging¶| pytorch.org
Instances of autocast serve as context managers or decorators that| pytorch.org
torchvision¶| pytorch.org
Join us at PyTorch Conference in San Francisco, October 22-23. CFP open now! Learn more.| PyTorch
Base class for all neural network modules.| pytorch.org
The PyTorch Foundation, a neutral home for the deep learning community to collaborate on the open source PyTorch framework and ecosystem, is announcing today that Lightning AI has joined as a premier member.| PyTorch
Table of Contents| pytorch.org
Eager Mode Quantization¶| pytorch.org
Loading Batched and Non-Batched Data¶| pytorch.org
A guide to torch.cuda, a PyTorch module to run CUDA operations| pytorch.org
torch.nn¶| pytorch.org
Allows the model to jointly attend to information from different representation subspaces.| pytorch.org
If you installed PyTorch-nightly on Linux via pip between December 25, 2022 and December 30, 2022, please uninstall it and torchtriton immediately, and use the latest nightly binaries (newer than Dec 30th 2022).| PyTorch

