
Wes McKinney - The Road to Composable Data Systems: Thoughts on the Last 15 Years and the Future
Getting Started: 2008 to 2015| wesmckinney.com
Getting Started: 2008 to 2015| wesmckinney.com
The problem with the data science language wars| wesmckinney.com
Some reflections from turning 30.| wesmckinney.com
Thoughts on joining Cloudera| wesmckinney.com
Joining Forces for an Arrow-Native Future| wesmckinney.com
Ursa Labs March 2019 Report| wesmckinney.com
Ursa Labs February 2019 Report| wesmckinney.com
Ursa Labs January 2019 Report| wesmckinney.com
Leaving NYC for Nashville| wesmckinney.com
Apache Arrow: An Open Standard for Columnar Data on the GPU| wesmckinney.com
Announcing Ursa Labs: an innovation lab for open source data science| wesmckinney.com
Storage and runtime formats, in context| wesmckinney.com
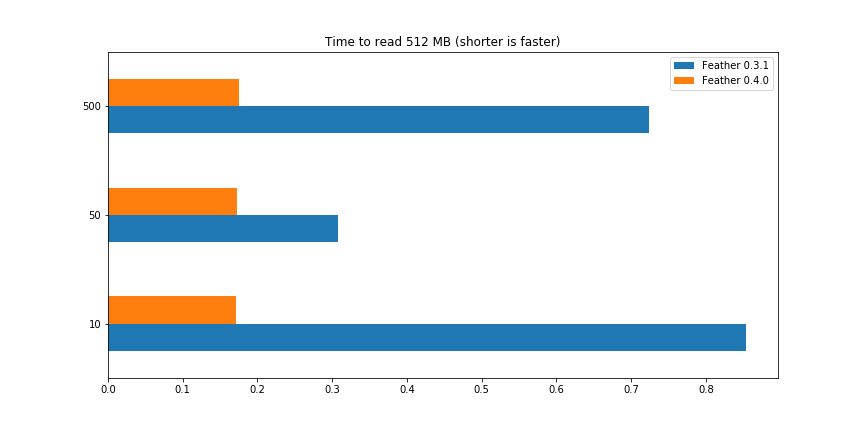
Feather format update: Whence and Whither?| wesmckinney.com
2017 Outlook: pandas, Arrow, Feather, Parquet, Spark, Ibis| wesmckinney.com
From Arrow to pandas at 10 Gigabytes Per Second| wesmckinney.com
I discuss my impressions of the newest version of the classic Kinesis Advantage contoured mechnical keyboard| wesmckinney.com
A skewed view of reality| wesmckinney.com
Feather: it’s about metadata| wesmckinney.com
Streaming Columnar Data with Apache Arrow| wesmckinney.com
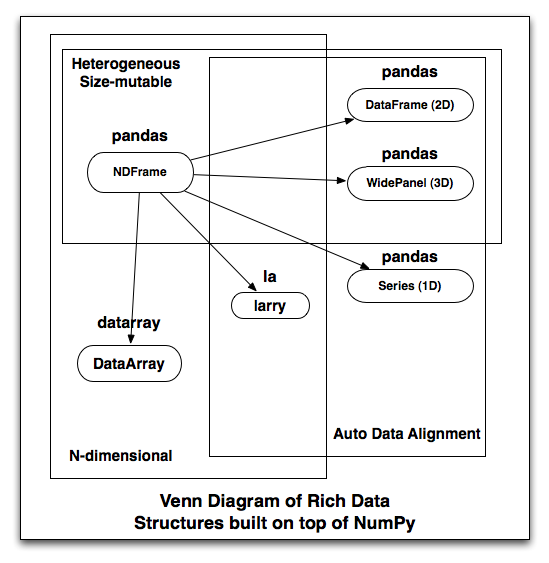
Data structures with metadata, the backstory| wesmckinney.com
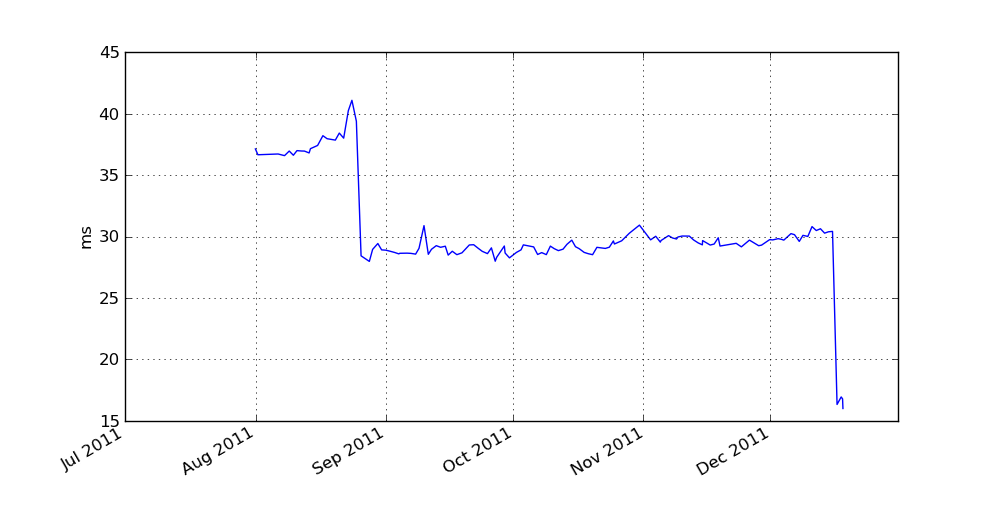
Introducing vbench, new code performance analysis and monitoring tool| wesmckinney.com
Accelerating data access for pandas users on Hadoop clusters| wesmckinney.com
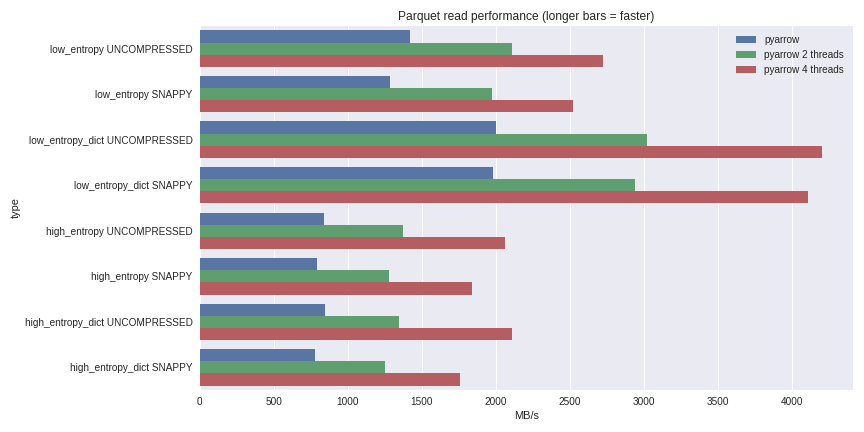
Extreme IO performance with parallel Apache Parquet in Python| wesmckinney.com
DataPad, Badger, and my time at Cloudera| wesmckinney.com
