The epistemology of lower-back pain (pt. 2) - by Sean Trott
Bad backs, healthy minds, and the art of not paying attention.| seantrott.substack.com
Bad backs, healthy minds, and the art of not paying attention.| seantrott.substack.com

Max Weber's "Science as a Vocation".| The Counterfactual
What does it mean to say two circuits in two different models "do the same thing"?| seantrott.substack.com
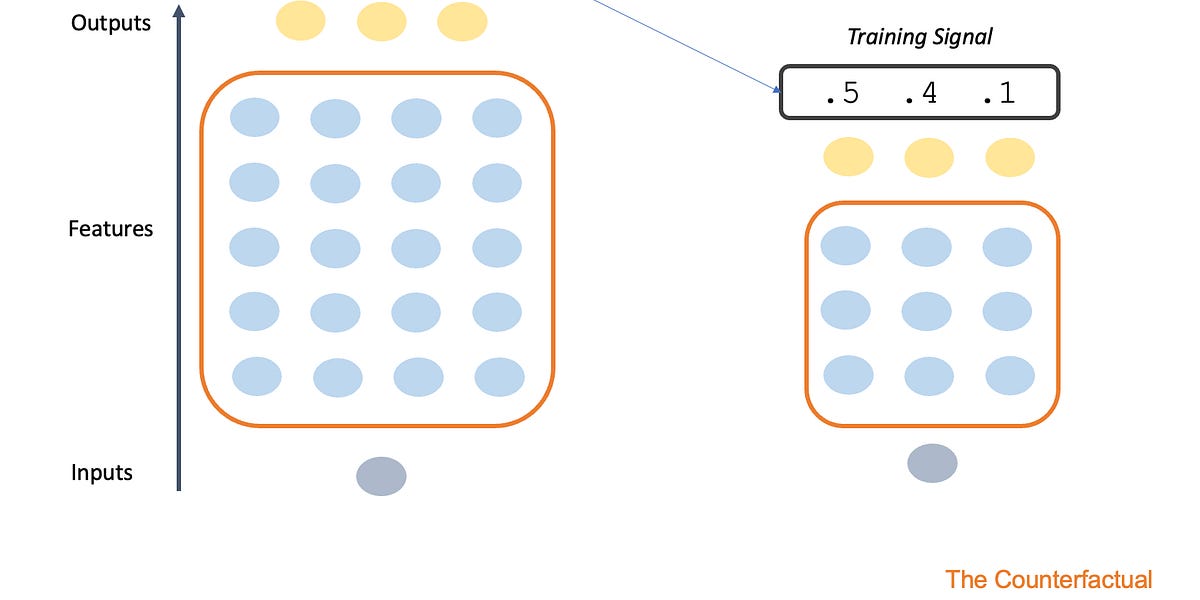
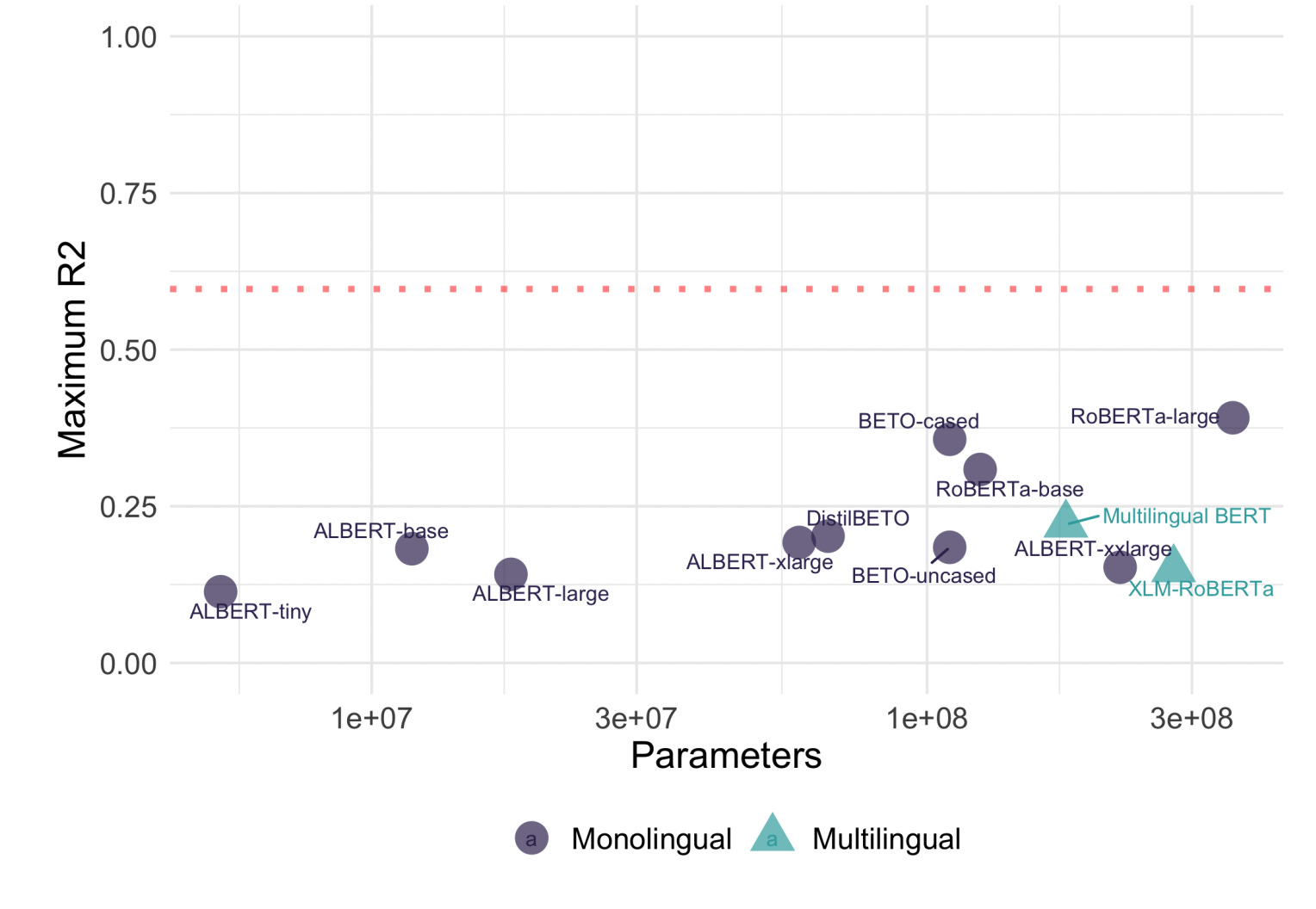
On efforts to do more with less.| seantrott.substack.com
A review of emerging empirical data.| seantrott.substack.com
The limits of our language-based benchmarks are the limits of our language.| seantrott.substack.com
A tie between an explainer on model efficiency and an empirical survey of the interpretability literature.| The Counterfactual
Poll for July/August, 2025| The Counterfactual
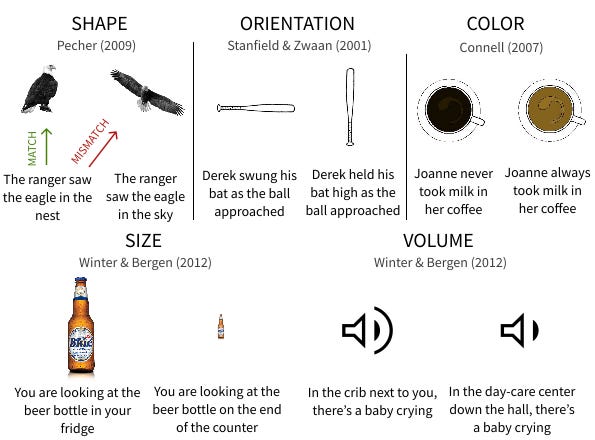
The view from Cognitive Science.| seantrott.substack.com
It all comes back to what we mean by what we say.| seantrott.substack.com

Synthetic data has its place, but stimuli are at the heart of how we probe and assess LLMs (and humans)—and that calls for special care.| The Counterfactual
An update on when and how I use LLM-equipped software tools, and when (and why) I don't.| seantrott.substack.com
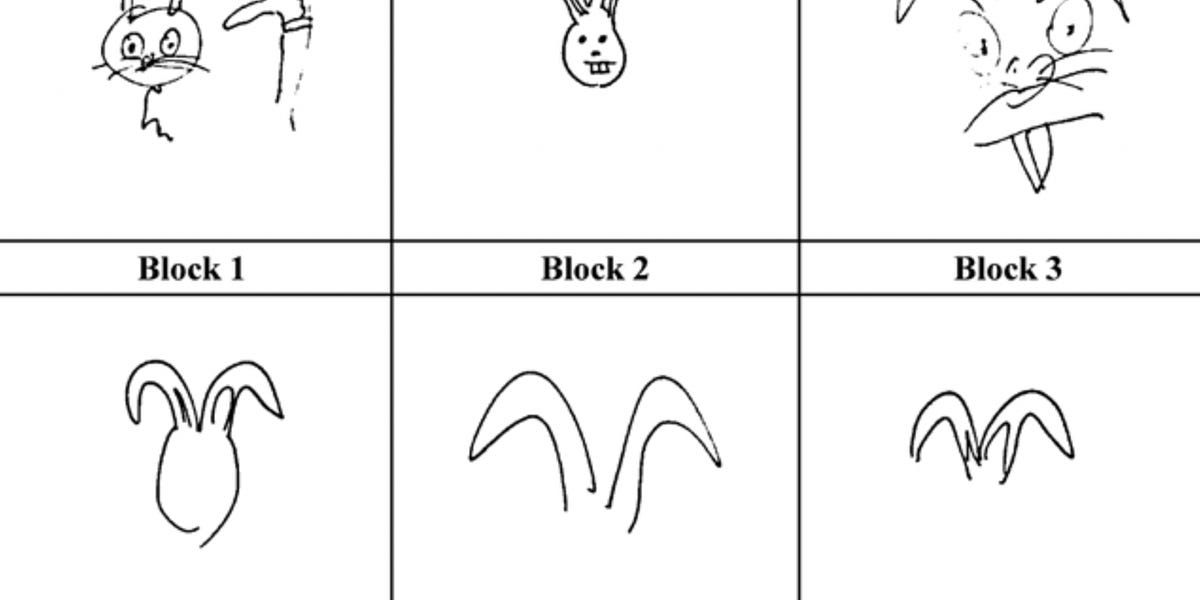
If non-arbitrariness helps with word leaning, why are languages still mostly arbitrary?| seantrott.substack.com

Not all form-meaning mappings are arbitrary.| seantrott.substack.com
On the unauthorized experiment conducted on a subreddit community.| seantrott.substack.com
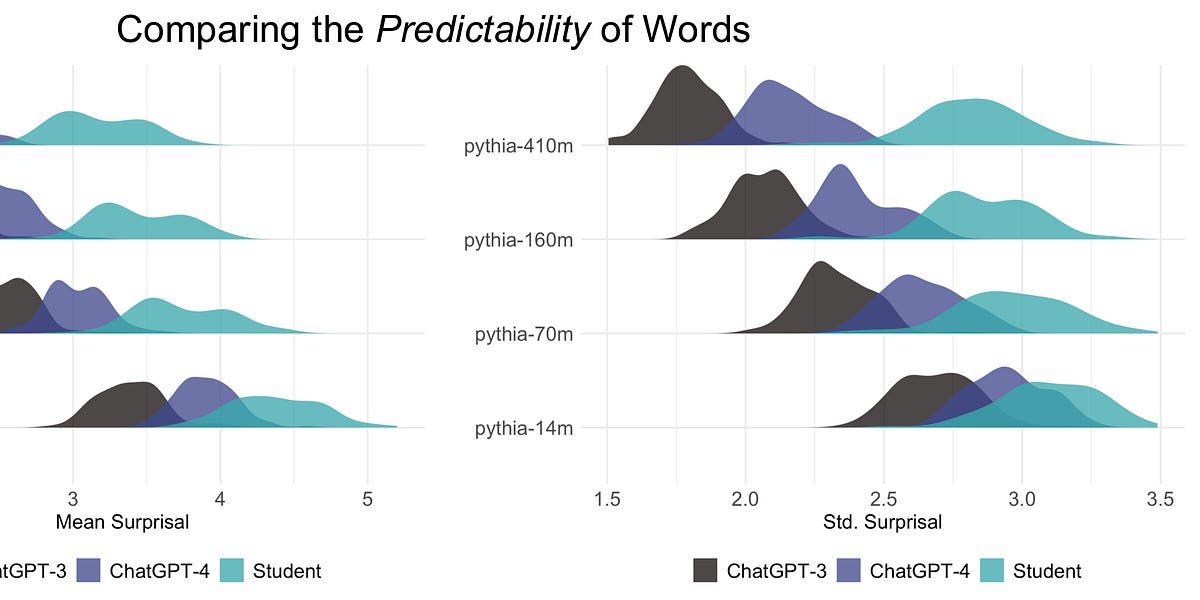
What metrics from open-source LLMs can tell us about the differences between human essays and those written by ChatGPT-3 and ChatGPT-4.| seantrott.substack.com
How can a science of LLMs keep up with technological development?| seantrott.substack.com

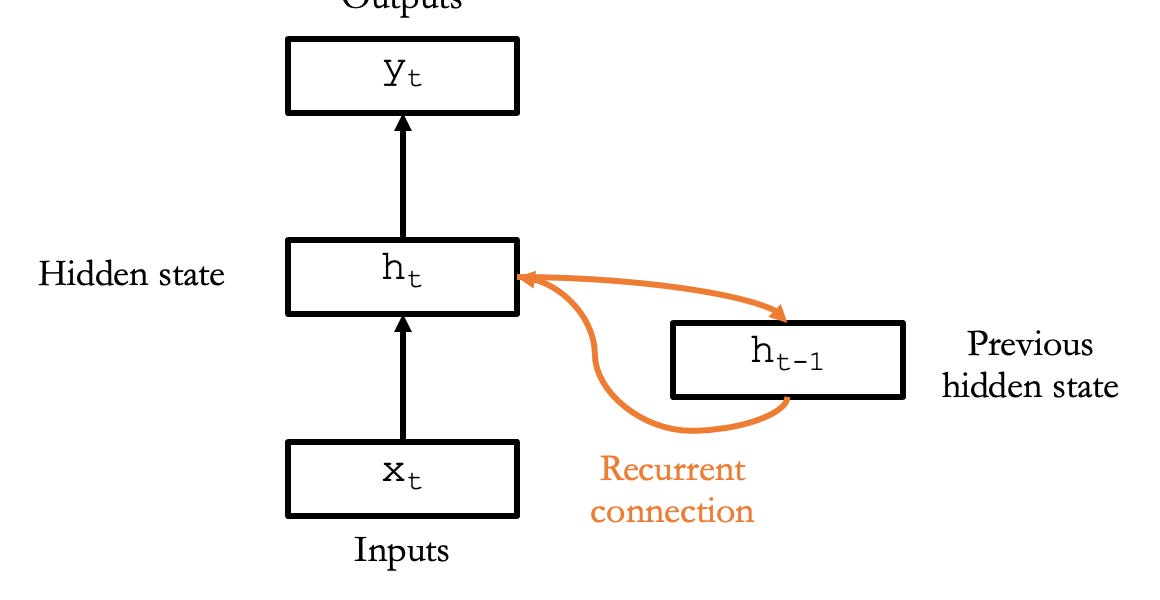
Want to really understand how large language models work? Here’s a gentle primer.| seantrott.substack.com
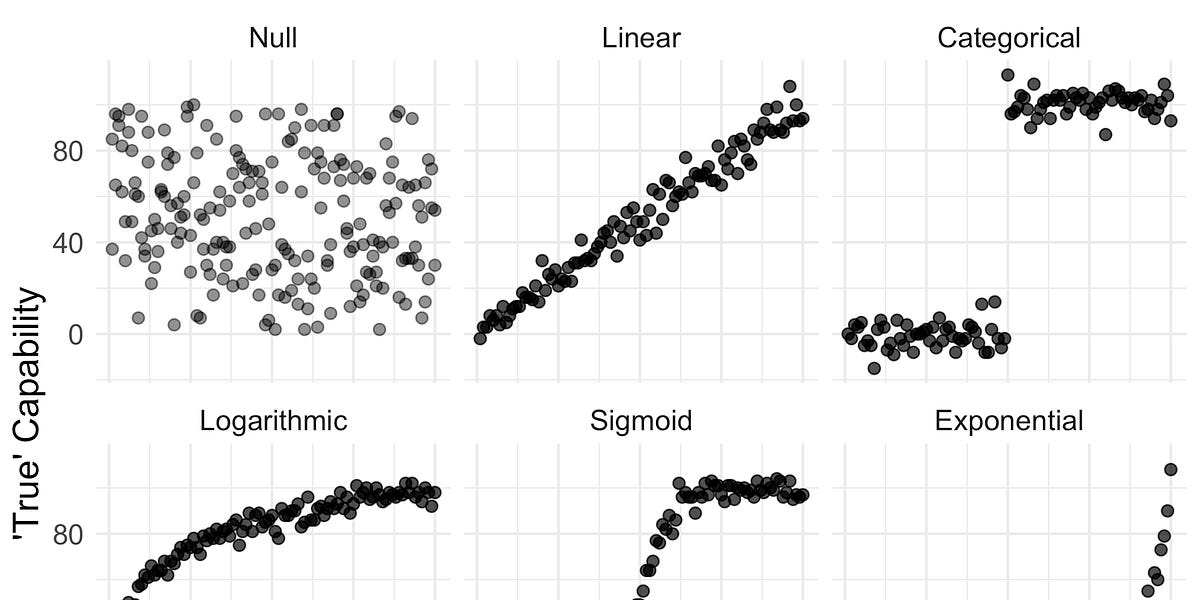
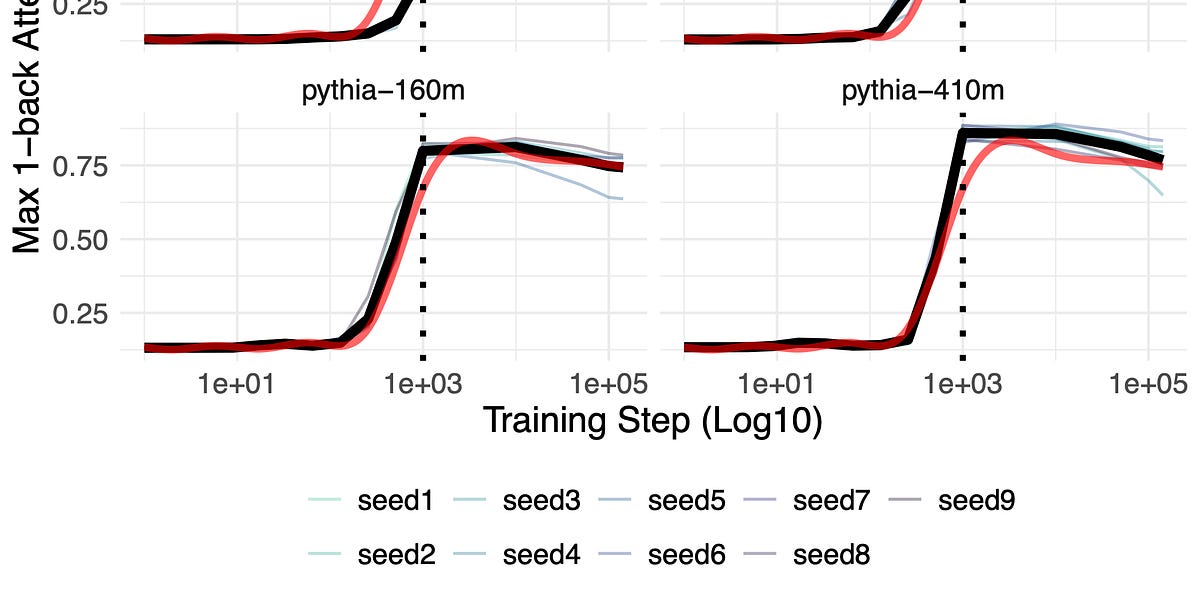
Proxies for a capability may not map linearly onto the capability itself.| seantrott.substack.com
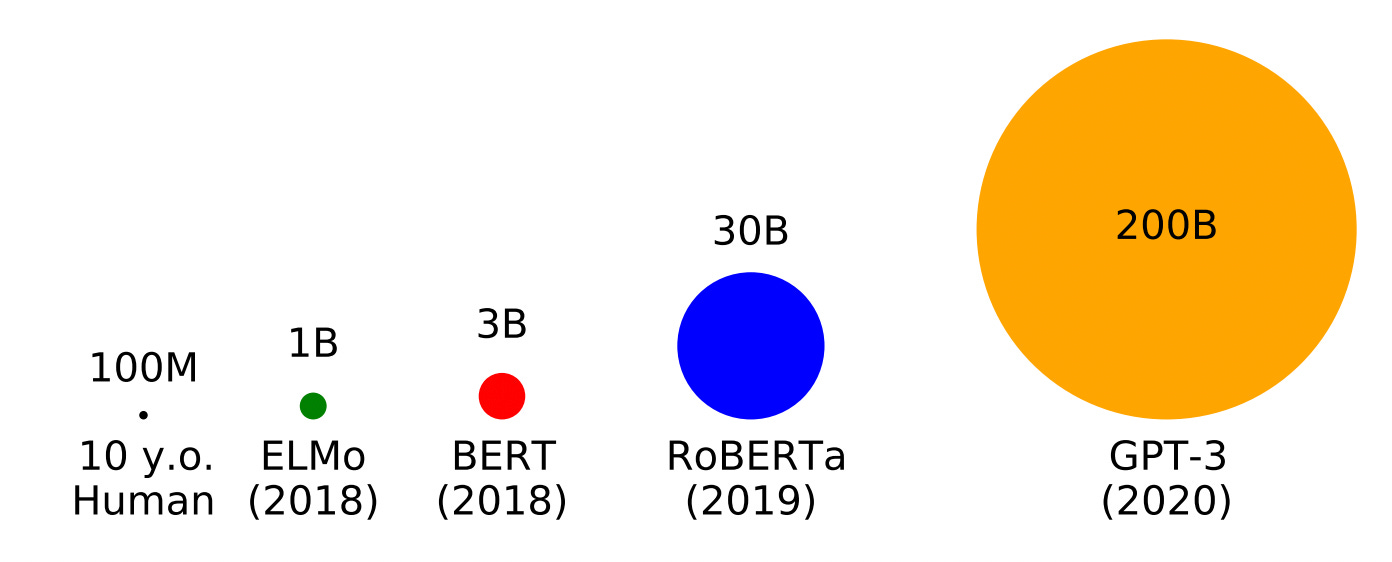
Language models are hungry for data—can we initialize their weights in ways that help reduce how much data they need?| The Counterfactual

A review of Richard Wrangham's "Catching Fire: How Cooking Made Us Human".| seantrott.substack.com
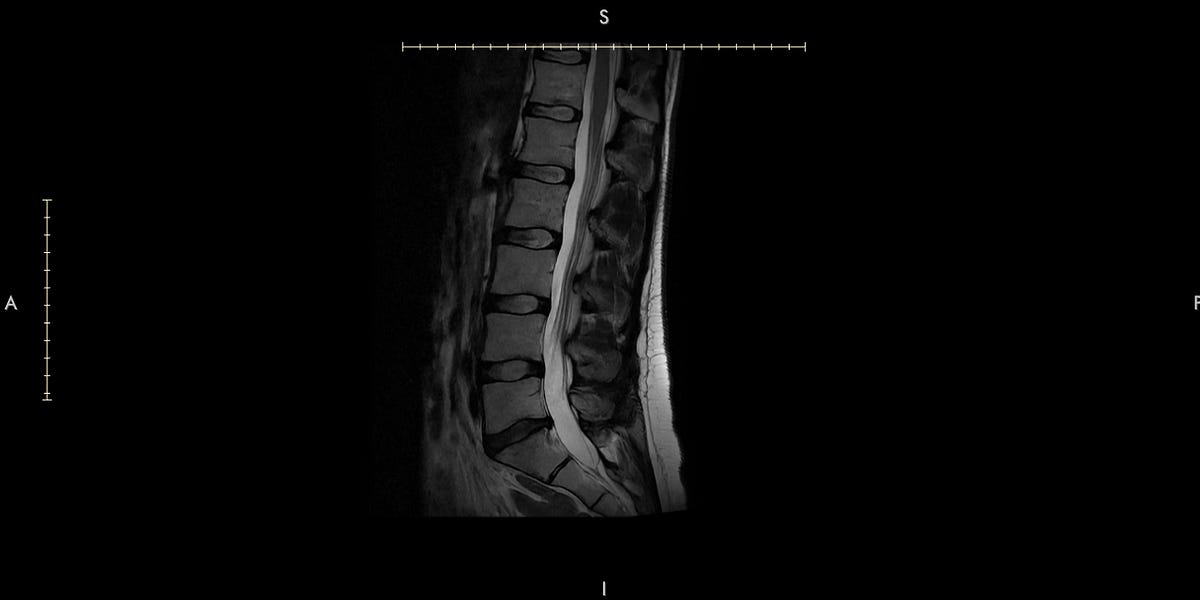
Or: trying to learn to stop worrying and love spine neutrality| seantrott.substack.com

Wrapping up another year.| seantrott.substack.com

Exploring the new multimodal model from AI2.| seantrott.substack.com

How do VLMs combine their modalities?| seantrott.substack.com
Three hard questions for a new paradigm.| seantrott.substack.com
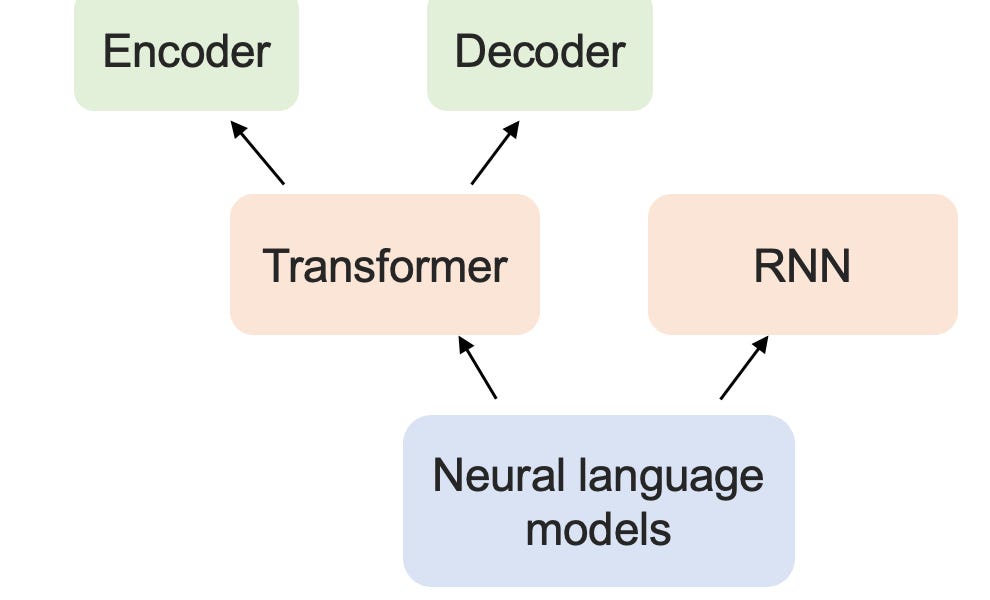
Do we need a CERN for LLM-ology?| seantrott.substack.com
Cognitive architectures, extended minds, and distributed cognition.| seantrott.substack.com
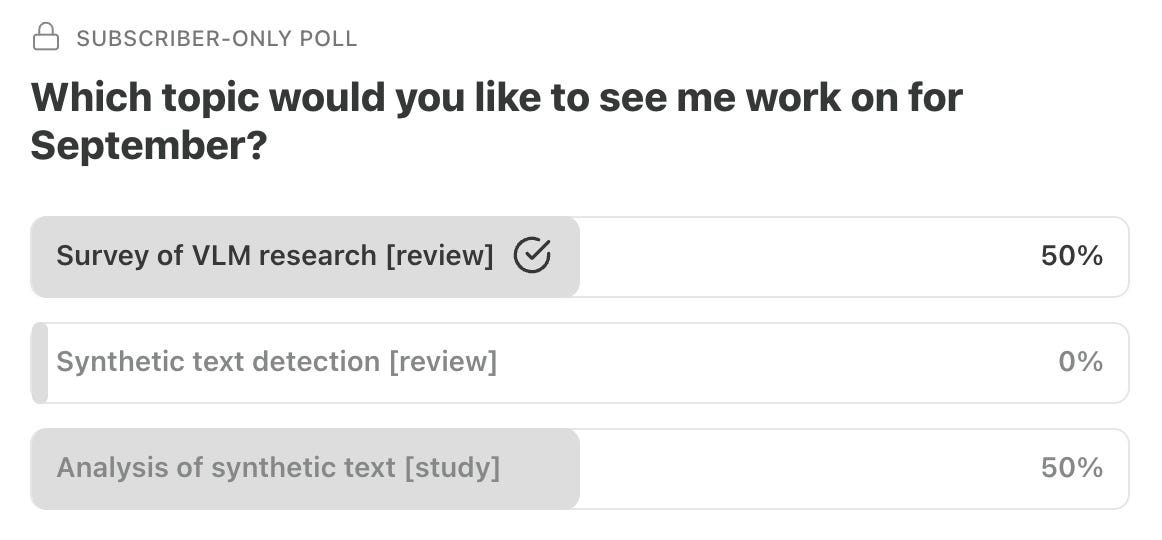
Another tie—plus some updates.| seantrott.substack.com
How to get started studying LLMs.| seantrott.substack.com
Stochastic parrots, blurry JPEGs, aliens, and more.| seantrott.substack.com
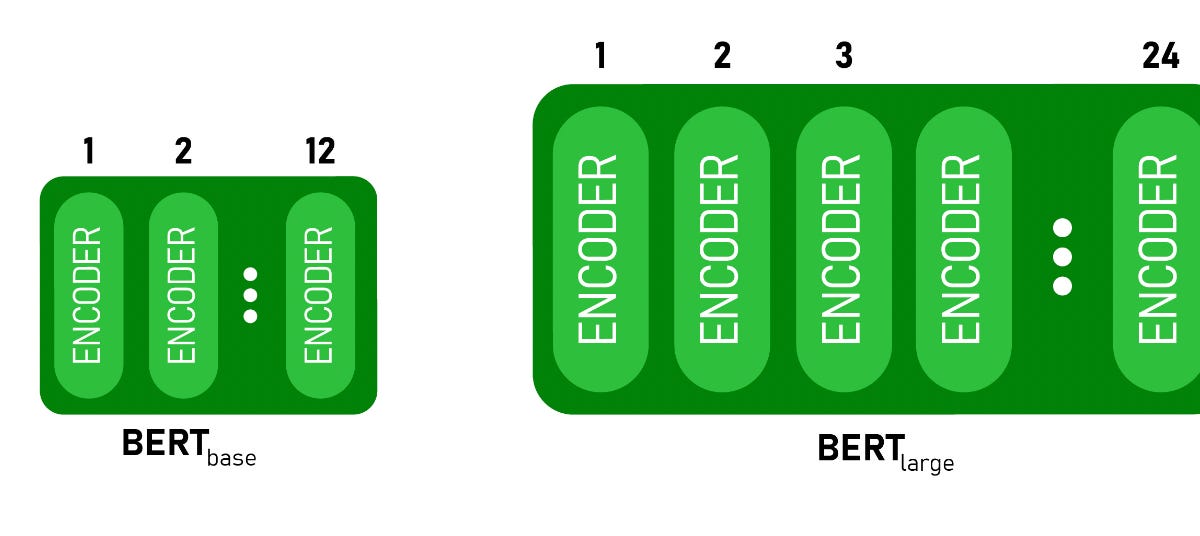
It's useful to try to peek inside the black box, but it should be done rigorously.| seantrott.substack.com
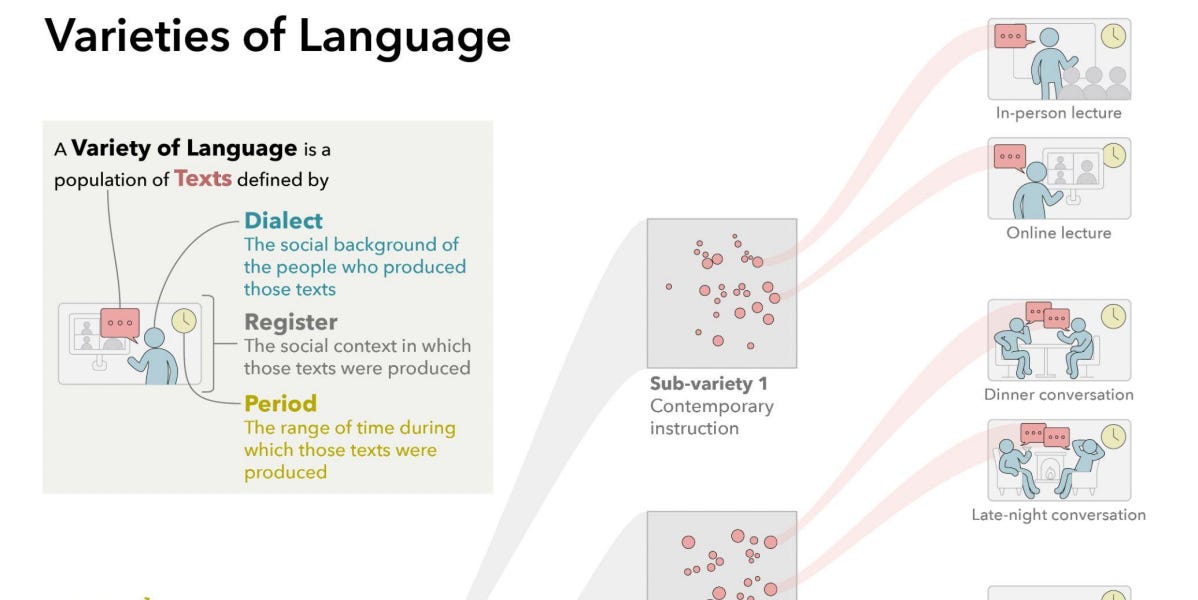
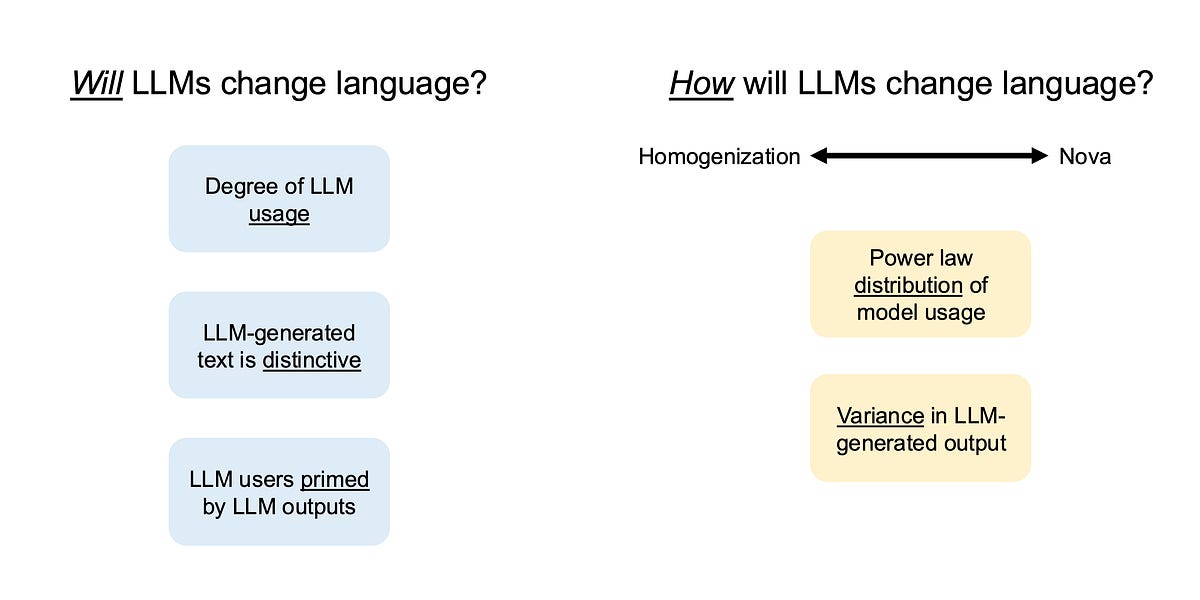
The sociolinguistics of large language models.| seantrott.substack.com
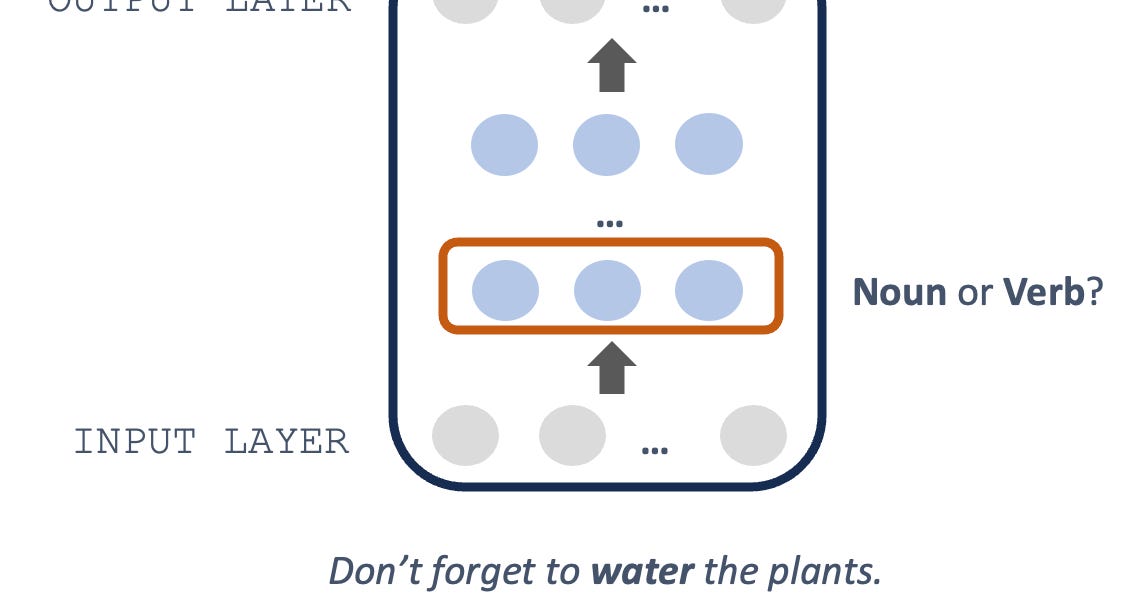
Trying to peek inside the "black box".| seantrott.substack.com

Modern language models predict "tokens", not words—but what exactly are tokens?| seantrott.substack.com
Tokenization's a winner, plus some administrative updates.| seantrott.substack.com
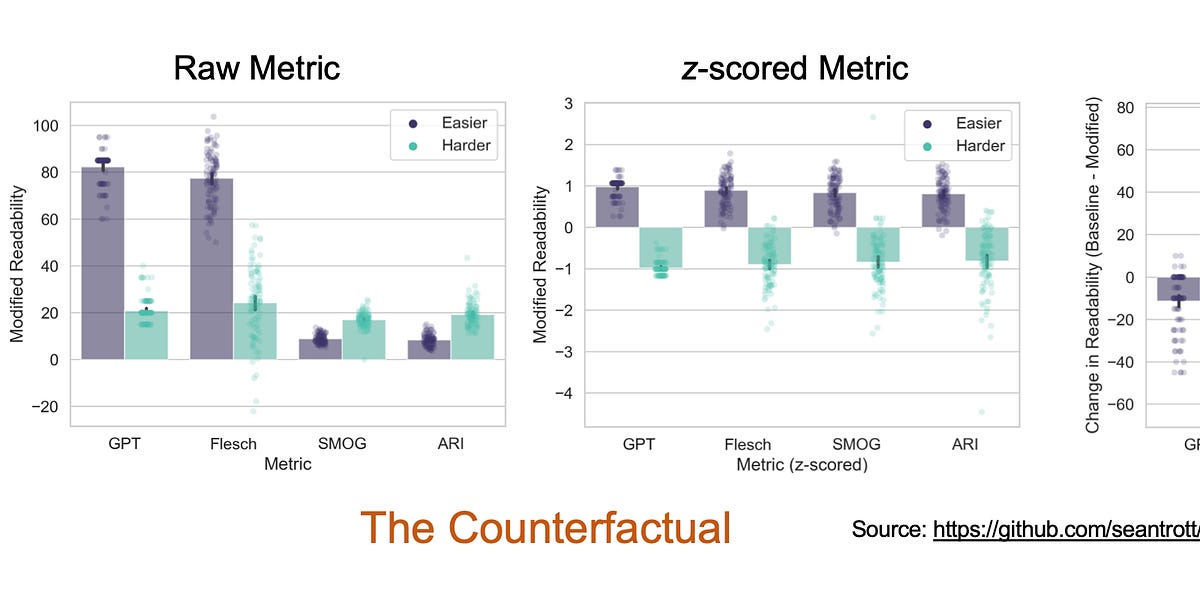
Can GPT-4 Turbo rewrite texts to make them easier or harder to read?| seantrott.substack.com

When we use LLMs as "model organisms", which humans are we modeling? And how can we overcome the problem of unrepresentative data?| seantrott.substack.com
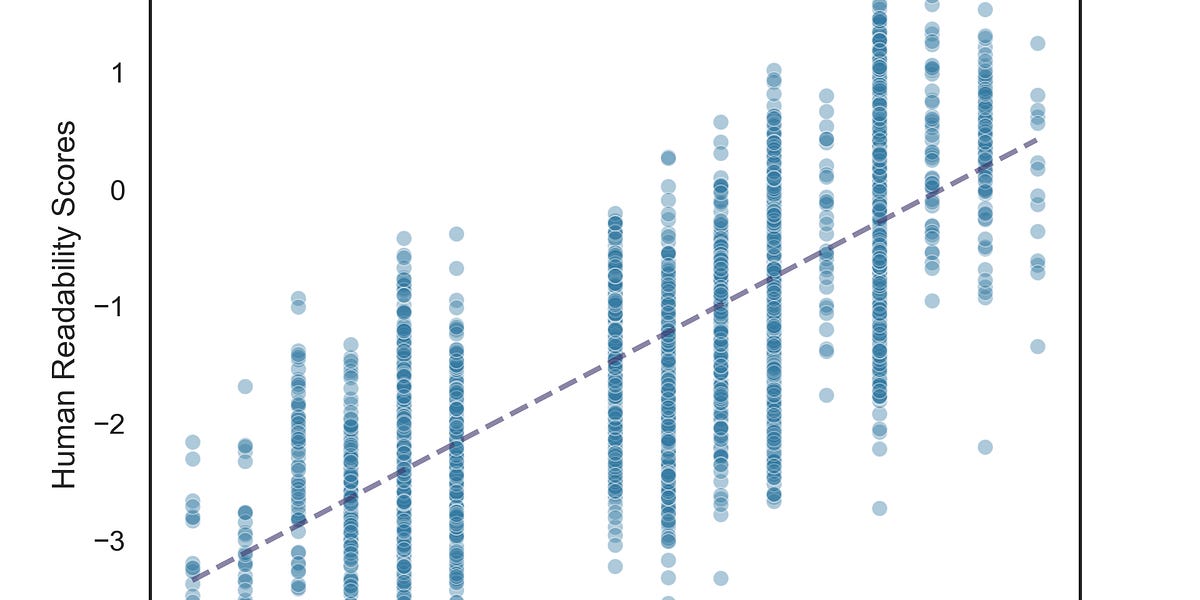
Defining, operationalizing, and measuring readability is a challenge—can LLMs help?| seantrott.substack.com

What I'll be working on this month.| seantrott.substack.com

Trade-offs between the particular and the general.| seantrott.substack.com
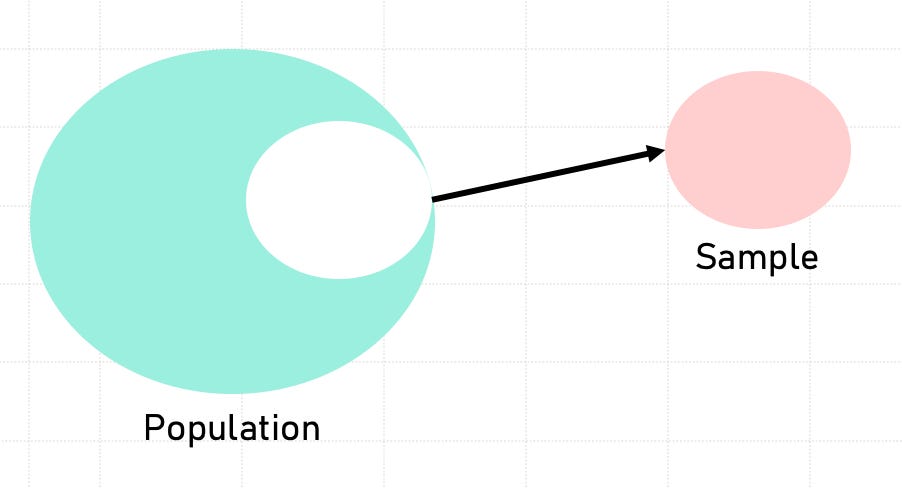
Many researchers rely on survey data. How could LLMs like GPT-4 change that?| seantrott.substack.com
Measuring what you want to measure is hard.| seantrott.substack.com