
Vinted moves from Elasticsearch to Vespa | Vespa Blog
With Vespa, Vinted managed to halve the number of servers, slash query latency by 2.5x, indexing latency by 3x, and increase ranking depth by more than 3x.| Vespa Blog
With Vespa, Vinted managed to halve the number of servers, slash query latency by 2.5x, indexing latency by 3x, and increase ranking depth by more than 3x.| Vespa Blog

According to ESG, 41% of retail respondents in a 2024 survey are either already pursuing or planning to pursue AI-powered product recommendations.| Vespa Blog
We Make AI Work| Vespa Blog
Perplexity demonstrates the quality of their search solution and show what it takes to achieve it| Vespa Blog
E-commerce has entered a new age. Shoppers expect personalized, dynamic, and trustworthy experiences tailored to their unique needs. How do you balance personalisation, business objectives, system costs, and innovation speed—while ensuring everything works reliably at scale?| Vespa Blog
This a companion post to the previous technical blog post, explaining how to tweak Vespa's ANN parameters.| Vespa Blog
Advances in Vespa features and performance include new ANN tuning parameters, improvements to Geo filtering, filtering in grouping, and relevance score carry-over to global ranking.| Vespa Blog
This a companion post to the previous technical blog post, explaining how to tweak Vespa's ANN parameters.| Vespa Blog
This blog post highlights the latest additions to HNSW in Vespa, how to use them, and what's to come in the future.| Vespa Blog
How Onyx.app saved 25% with a safe and straightforward automated configuration change, with zero work to optimize spending and performance| Vespa Blog
This summer, we got to explore Hierarchical Navigable Small World, a foreign concept for us both - we’ll take you on the journey we went through.| Vespa Blog
We are thrilled to announce a new enhancement to Vespa Cloud, native support for private Hugging Face embedders!| Vespa Blog

8byte is building a next-gen diligence engine for private equity, powered by Vespa.ai’s sub-100 ms search. The result: real-time risk scoring, 5× analyst throughput, and 50% lower infrastructure costs.| Vespa Blog
We Make AI Work| Vespa Blog
Why intelligent RAG systems need both Snowflake (for structured scale) and Vespa (for high-performance retrieval across unstructured text.| Vespa Blog

Get started with Vespa and set up your first application. Build your first Vespa instance using Python.| Vespa Blog
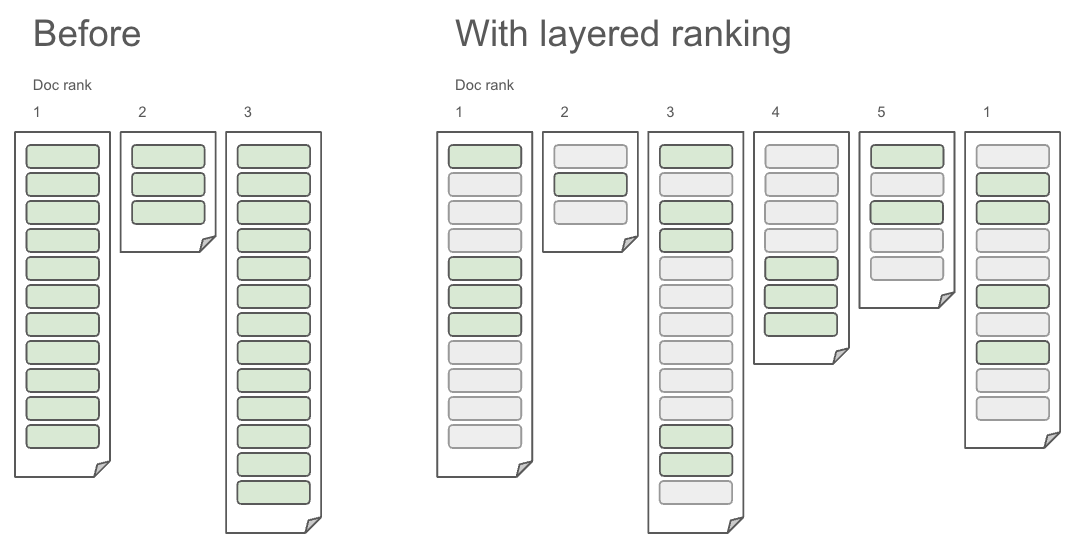
Introducing layered ranking: The missing piece for context engineering at scale.| Vespa Blog
It is now the age of RAG, semantic + hybrid search, domain reasoning, powering copilots and AI agents. Lets see how - lets build your next Scientific Search engine!| Vespa Blog
We Make AI Work| Vespa Blog
Learn how how Vespa’s native tensor capabilities are redefining AI-powered search and retrieval in life sciences, enabling faster, more accurate insights across complex, multimodal scientific data.| Vespa Blog

Example of an end-to-end implementation of an agentic retail chatbot assistant that provides an advanced conversational search experience through an agentic workflow encapsulating tool usage.| Vespa Blog

Vespa functionality from a Solr user’s perspective. Where it overlaps and where it differs. Why would you migrate and what challenges to expect.| Vespa Blog

AI search requires more than a vector database. A search platform bridges the gaps.| Vespa Blog
Perplexity chose to build on Vespa.ai to provide the world’s most used RAG application.| Vespa Blog

Live Webinar: Unlock the Future of eCommerce – May 8, 2 PM CET.| Vespa Blog

Fastest way to get your data into Vespa. Logstash generates the schema. Then deploys the application package to Vespa. Next Logstash run does the actual writes.| Vespa Blog

Document enrichment with LLMs can be used to transform raw text into structured form and expand it with additional contextual information. This helps to improve search relevance and create a more effective search experience.| Vespa Blog
Advances in Vespa features and performance include Lexical Search Query Performance, Pyvespa Relevance Evaluator, Global-phase rank-score-drop-limit, and Compact tensor representation.| Vespa Blog

Introducing Vespa Voice: a podcast on AI infrastructure, hybrid search, and RAG.| Vespa Blog

Improvements made to triple the query performance of lexical search in Vespa.| Vespa Blog
Announcing Matryoshka (dimension flexibility) and binary quantization in Vespa and how these features slashes costs.| Vespa Blog

Learn how the ModernBERT backbone model paves the way for more efficient and effective retrieval pipelines, and how to use ModernBERT in Vespa.| Vespa Blog

A guide on implementing advanced video retrieval at scale using Vespa and TwelveLabs’ multi-modal embedding models.| Vespa Blog

The evolution of language models combined with state-of-the-art information retrieval is reshaping the insurance landscape.| Vespa Blog
Advances in Vespa features and performance include Pyvespa Querybuilder, Vespa input/output plugins for Logstash, ModernBERT models, and Vespa CLI multi-get.| Vespa Blog

Where should you begin if you plan to implement search functionality but have not yet collected data from user interactions to train ranking models?| Vespa Blog

Connecting the ColPali model with Vespa for complex document format retrieval.| Vespa Blog

Tutorials on feeding data to Vespa from CSV files, PostgreSQL, Kafka, Elasticsearch and another Vespa.| Vespa Blog

Have you ever wondered how the world’s largest internet and social media companies can deliver algorithmic content to so many users so fast?| Vespa Blog

How MRL and BQL Make AI-Powered Representations Efficient| Vespa Blog

ColPali simplifies and enhances information retrieval from complex, visually rich documents, transforming retrieval-augmented generation| Vespa Blog

This blog post describes Vespa’s industry leading support for combining approximate nearest neighbor search, or vector search, with query constraints to solve real-world search and recommendation problems at scale.| Vespa Blog

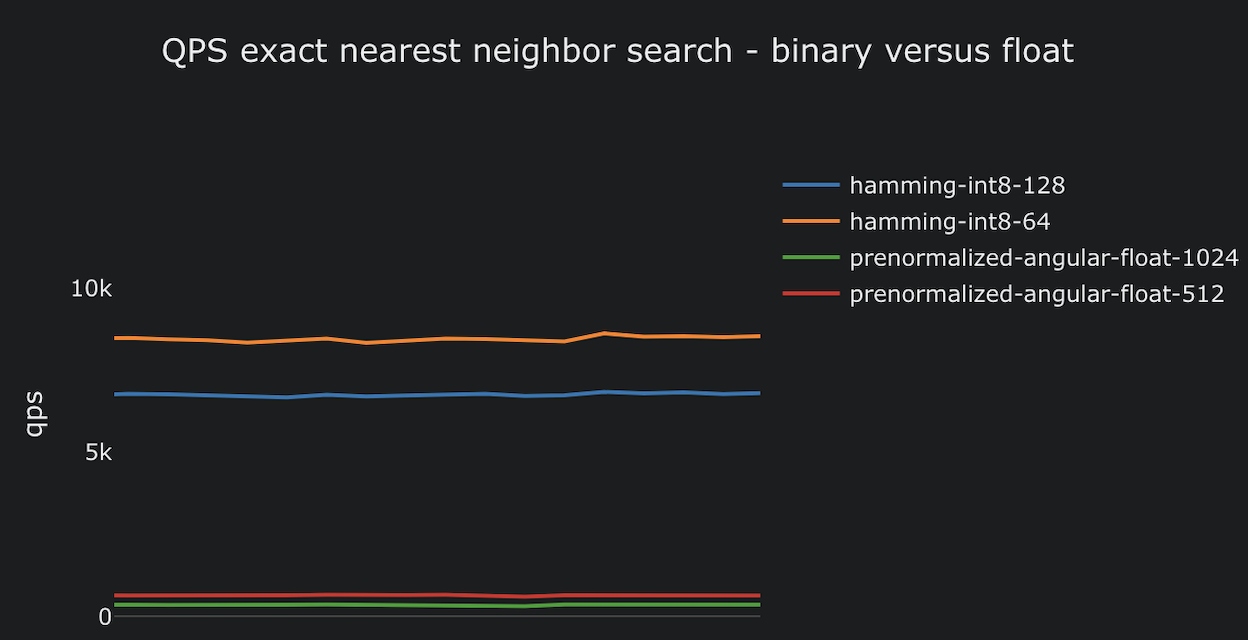
Part one in a blog post series on billion-scale vector search. This post covers using nearest neighbor search with compact binary representations and bitwise hamming distance.| Vespa Blog
Advances in Vespa features and performance include Elasticsearch vs Vespa Performance Comparison, Vision RAG and Binarizing Vectors| Vespa Blog

Learn how to securely store and manage sensitive secrets in your Vespa Cloud applications using Vespa’s built-in secret store.| Vespa Blog
Exploring how Vespa.ai exemplifies Norway’s commitment to sustainability through efficient technology.| Vespa Blog

A beginner’s guide to Vespa, exploring its role in information retrieval and its advantages for enterprise AI applications.| Vespa Blog

Discover how Vespa outperforms Elasticsearch in query efficiency, scalability, and operational costs, making it a robust choice for modern eCommerce search solutions.| Vespa Blog
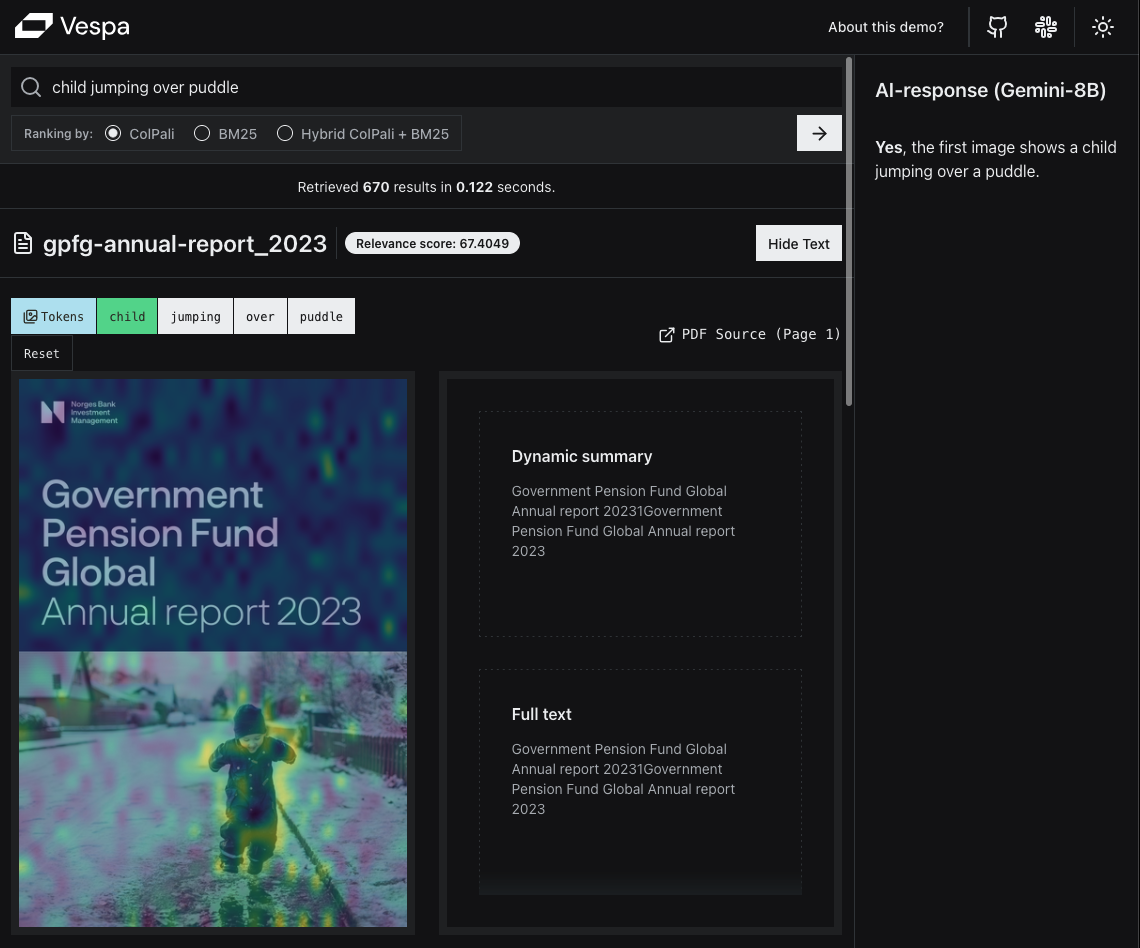
This is a technical blog post on developing an end-to-end Visual RAG application powered by Vespa. It has link to a live demo application, and will walk you through why and how we built it, as well as give you the code to build your own Visual RAG application with your own data.| Vespa Blog
This AI-driven ecommerce evolution is driven by consumer’s increasing demand for personalized experiences, real-time interactions, and seamless omnichannel integration.| Vespa Blog
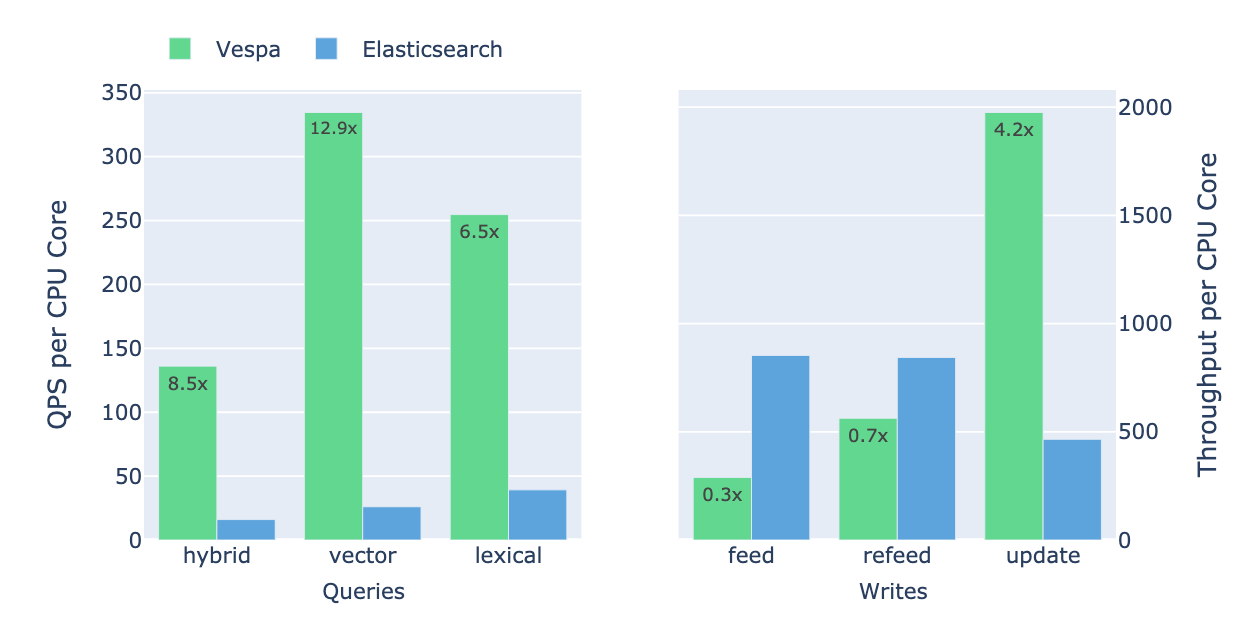
Detailed report of a comprehensive performance comparison between Vespa and Elasticsearch for an e-commerce search application.| Vespa Blog

The purpose of using vectors is to improve quality, but that takes much more than a similarity lookup. Search engines are built for that, databases are not.| Vespa Blog

How to create your own reusable retrieval evaluation dataset for your data and use it to assess your retrieval system’s effectiveness| Vespa Blog

Three comprehensive guides to using the Cohere Embed v3 binary embeddings with Vespa.| Vespa Blog

Announcing multi-vector indexing support in Vespa, which allows you to index multiple vectors per document and retrieve documents by the closest vector in each document.| Vespa Blog
In this post, I will detail the journey at Stanby of how we have addressed the challenges faced by our existing search system through migrating to Vespa.| Vespa Blog

Announcing long-context ColBERT, giving it larger context for scoring and simplifying long-document RAG applications.| Vespa Blog

Using the “shortening” properties of OpenAI v3 embedding models to greatly reduce latency/cost while retaining near-exact quality| Vespa Blog

The new IN operator is a shorthand for multiple OR conditions, enabling writing more concise queries with better performance| Vespa Blog

This is the first blog post in a series on hybrid search. This first post focuses on efficient hybrid retrieval and representational approaches in IR| Vespa Blog

Part two in a blog post series on billion-scale vector search with Vespa. This post explores the many trade-offs related to nearest neighbor search.| Vespa Blog
A new search experience for Vespa-related content - powered by Vespa, LangChain, and OpenAI’s chatGPT model - our motivation for building it, features, limitations, and how we made it.| Vespa Blog

