AWS is the world’s largest cloud provider. It’s hard to comprehend how many billions of times per second their instances compute string hashes and SHA-256 file checksums! After releasing StringZilla v4, I spun up instances of the last 3 Graviton generations, exploring optimization opportunities across NEON, SVE, and SVE2 extensions. Graviton 2Graviton 3Graviton 4 Context Availability year202020222024 Process node7 nm, TSMC5 nm, TSMC3nm, TSMC ArchitectureNeoverse N1Neoverse V1Neoverse V2 M...| Ash's Blog
I’ve always been fascinated by AI and mega-projects — and as I work on AI infrastructure, you might assume I’m equally fascinated by the current LLM race. In reality, I’m far more skeptical than most. While LLMs are undeniably useful, I’m not convinced “intelligence” is even the right scale to measure them against. The analogy I keep returning to comes not from computer science, but from astronomy: the story of epicycles.| Ash's Blog
To my great surprise, one of the biggest current users of my StringZilla library in the Python ecosystem is one of the world’s most widely used Image Augmentation libraries - Albumentations with over 100 million downloads on PyPI, growing by 5 million every month. Last year, Albumentations swapped parts of OpenCV - the world’s most widely used image processing library with 32 million monthly downloads in Python - for my strings library 🤯| Ash's Blog
I’ve just shipped StringZilla v4, the first CUDA-capable release of my SIMD-first string processing library. Which in English means that it is now fast not only on CPUs, but also on GPUs! I’ve wanted to add ROCm-acceleration for AMD GPUs 🤦♂️ I’ve wanted to include a parallel multi-pattern search algorithm 🤦♂️ I’ve wanted to publish it back in December 2024, not September 2025 🤦♂️ So not everything went to plan, but “StringZilla 4 CUDA” is finally here...| Ash's Blog
In 2018 – three years after leaving physics to focus on high-performance AI infrastructure (project Unum) – I gave the interview below during a LessWrong meetup on the ITMO University campus in St. Petersburg, Russia, arguably the strongest Computer Science department in the world. The recording was later posted on VKontakte. To preserve the conversation and reflect on it in the future, I’ve run it through automatic translation and posted it here, with some notes in the end on how the...| Ash's Blog
TL;DR: Most C++ and Rust thread‑pool libraries leave significant performance on the table - often running 10× slower than OpenMP on classic fork‑join workloads and micro-benchmarks. So I’ve drafted a minimal ~300‑line library called Fork Union that lands within 20% of OpenMP. It does not use advanced NUMA tricks; it uses only the C++ and Rust standard libraries and has no other dependencies. OpenMP has been the industry workhorse for coarse‑grain parallelism in C and C++ for de...| Ash's Blog
You’ve probably seen a CUDA tutorial like this one — a classic “Hello World” blending CPU and GPU code in a single “heterogeneous” CUDA C++ source file, with the kernel launched using NVCC’s now-iconic triple-bracket <<<>>> syntax: 1 2 3 4 5 6 7 8 9 10 11 #include #include __global__ void kernel() { printf("Hello World from block %d, thread %d\n", blockIdx.x, threadIdx.x); } int main() { kernel<<<1, 1>>>(); // Returns `void`?! 🤬 return cudaDeviceSynchronize() == cudaSuccess...| Ash's Blog
The race for AI dominance isn’t just about who has the most computing - it’s increasingly about who can use it most efficiently. With the recent emergence of DeepSeek and other competitors in the AI space, even well-funded companies are discovering that raw computational power isn’t enough. The ability to squeeze maximum performance out of hardware through low-level optimization is becoming a crucial differentiator. One powerful tool in this optimization arsenal is the ability to work d...| Ash's Blog
For High-Performance Computing engineers, here’s the gist: On Intel CPUs, the vaddps instruction (vectorized float addition) executes on ports 0 and 5. The vfmadd132ps instruction (vectorized fused float multiply-add, or FMA) also executes on ports 0 and 5. On AMD CPUs, however, the vaddps instruction takes ports 2 and 3, and the vfmadd132ps instruction takes ports 0 and 1. Since FMA is equivalent to simple addition when one of the arguments is 1, we can drastically increase the throughput ...| Ash's Blog
I’d argue that almost every open-source developer gets an extra spark of joy when someone reads the documentation and uses their tool in a way that goes beyond the classic 101 examples. It’s a rare treat even for popular projects like JSON parsers, but if you are building high-throughput software, such as analyzing millions of network packets per second, you’ll have to dig deeper. The first thing I generally check in such libraries is the memory usage pattern and whether I can override ...| Posts on Ash's Blog
It’s 2025. Sixteen years ago, someone asked on StackOverflow how to split a string in C++. With 3000 upvotes, you might think this question has been definitively answered. However, the provided solutions can be greatly improved in terms of both flexibility and performance, yielding up to a 10x speedup. In this post, we’ll explore three better ways to split strings in C++, including a solution I briefly mentioned in 2024 as part of a longer review of the Painful Pitfalls of C++ STL Strings.| Ash's Blog
When I was 20, I committed the next 40 years of my life to AI, approaching it from the infrastructure perspective. In 2015, before ChatGPT and the AI surge, such a long-term commitment seemed naive to many — almost like proposing marriage on a second date — the move I am most proud of. Yesterday, Unum celebrated its 9th anniversary, and my open-source contributions have surpassed 9,000 stars on GitHub. To mark the occasion, as I’ve done before, I’m releasing something new, free, and p...| Ash's Blog
This blogpost is a mirror of the original post on Modular.com. Modern CPUs have an incredible superpower: super-scalar operations, made available through single instruction, multiple data (SIMD) parallel processing. Instead of doing one operation at a time, a single core can do up to 4, 8, 16, or even 32 operations in parallel. In a way, a modern CPU is like a mini GPU, able to perform a lot of simultaneous calculations. Yet, because it’s so tricky to write parallel operations, almost all t...| Ash's Blog
Set intersections are one of the standard operations in databases and search engines. They are used in: TF-IDF ranking in search engines, Table Joins in OLAP databases, Graph Algorithms. Chances are, you rely on them every day, but you may not realize that they are some of the most complex operations to accelerate with SIMD instructions. SIMD instructions make up the majority of modern Assembly instruction sets on x86 and Arm.| Ash's Blog
Python has a straightforward syntax for positional and keyword arguments. Positional arguments are arguments passed to a function in a specific order, while keyword arguments are passed to a function by name. Surprising to most Python developers, the choice of positional vs keyword arguments can have huge implications on readability and performance. 1 2 3 4 5 def cdist( A, B, /, # Positional-only arguments metric='cosine', *, # Positional or keyword arguments threads=1, dtype=None, out_dtype=...| Ash's Blog
Criticizing software is easy, yet the C++ and C standard libraries have withstood the test of time admirably. Nevertheless, they are not perfect. Especially the , , and headers. The first two alone bring in over 20,000 lines of code, slowing the compilation of every translation unit by over 100 milliseconds. Most of that code seems dated, much slower than LibC, and equally error-prone, with interfaces that are very hard to distinguish.| ashvardanian.com
To introduce myself, I am an iOS and macOS developer, and I use Apple products daily. I like what they usually do, but there is always a catch. It’s no surprise that industry giants should keep raising the bar in technology to save their market shares. And as it always happens, the time comes when giants fall. Luckily, it hasn’t happened yet. However, this 2016 WWDC was still a massive disappointment for me.| ashvardanian.com
Downloaded over 5 Billion times, NumPy is the most popular library for numerical computing in Python. It wraps low-level HPC libraries like BLAS and LAPACK, providing a high-level interface for matrix operations. BLAS is mainly implemented in C, Fortran, or Assembly and is available for most modern chips, not just CPUs. BLAS is fast, but bindings aren’t generally free. So, how much of the BLAS performance is NumPy leaving on the table?| ashvardanian.com
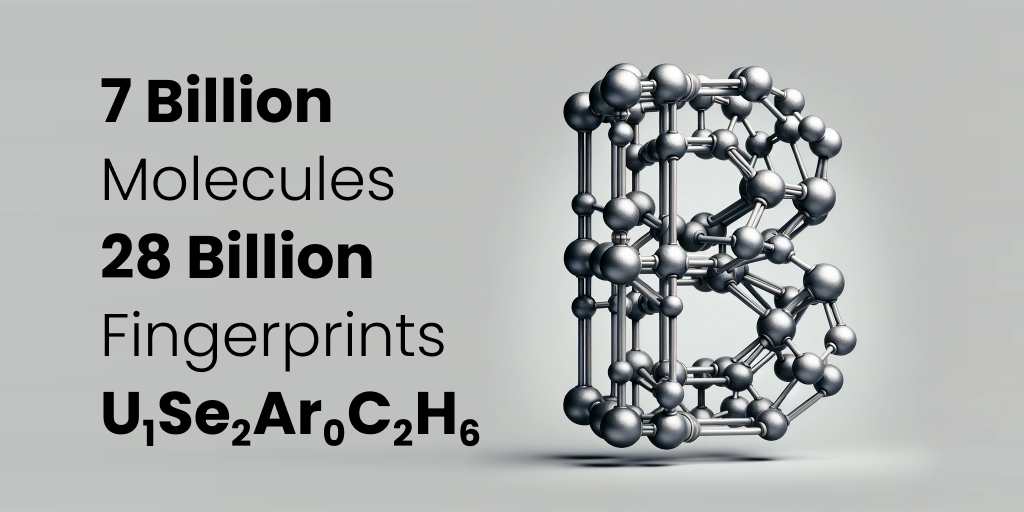
TLDR: I’ve finally finished a project that involved gathering 7 billion small molecules, each represented in SMILES notation and having fewer than 50 “heavy” non-hydrogen atoms. Those molecules were “fingerprinted”, producing 28 billion structural embeddings, using MACCS, PubChem, ECFP4, and FCFP4 techniques. These embeddings were indexed using Unum’s open-source tool USearch, to accelerate molecule search. This extensive dataset is now made available globally for free, thanks to ...| ashvardanian.com
Experienced devs may want to skip the intro or jump immediately to the conclusions. The backbone of many foundational software systems — from compilers and interpreters to math libraries, operating systems, and database management systems — is often implemented in C and C++. These systems frequently offer Software Development Kits (SDKs) for high-level languages like Python, JavaScript, GoLang, C#, Java, and Rust, enabling broader accessibility. But there is a catch.| ashvardanian.com
In this fourth article of the “Less Slow” series, I’m accelerating Unum’s open-source Vector Search primitives used by some great database and cloud providers to replace Meta’s FAISS and scale-up search in their products. This time, our focus is on the most frequent operation for these tasks - computing the the Cosine Similarity/Distance between two vectors. It’s so common, even doubling it’s performance can have a noticeable impact on applications economics.| ashvardanian.com
When our Python code is too slow, like most others we switch to C and often get 100x speed boosts, just like when we replaced SciPy distance computations with SimSIMD. But imagine going 100x faster than C code! It sounds crazy, especially for number-crunching tasks that are “data-parallel” and easy for compilers to optimize. In such spots the compiler will typically “unroll” the loop, vectorize the code, and use SIMD instructions to process multiple data elements in parallel.| ashvardanian.com
You’ve probably heard about AI a lot this year. Lately, there’s been talk about something called Retrieval Augmented Generation (RAG). Unlike a regular chat with ChatGPT, RAG lets ChatGPT search through a database for helpful information. This makes the conversation better and the answers more on point. Usually, a Vector Search engine is used as the database. It’s good at finding similar data points in a big pile of data. These data points are often at least 256-dimensional, meaning the...| ashvardanian.com
Python’s not the fastest language out there. Developers often use tools like Boost.Python and SWIG to wrap faster native C/C++ code for Python. PyBind11 is the most popular tool for the job not the quickest. NanoBind offers improvements, but when speed really matters, we turn to pure CPython C API bindings. With StringZilla, I started with PyBind11 but switched to CPython to reduce latency. The switch did demand more coding effort, moving from modern C++17 to more basic C99, but the result ...| ashvardanian.com
Over the years, Intel’s 512-bit Advanced Vector eXtensions (AVX-512) stirred extensive discussions. While introduced in 2014, it wasn’t until recently that CPUs began providing comprehensive support. Similarly, Arm Scalable Vector Extensions (SVE), primarily designed for Arm servers, have also started making waves only lately. The computing landscape now looks quite different with powerhouses like Intel’s Sapphire Rapids CPUs, AWS Graviton 3, and Ampere Altra entering the fray. Their ar...| ashvardanian.com
How can the 2012 Nobel Prize in Economics, Vector Search, and the world of dating come together? What are the implications for the future of databases? And why do Multi-Modal AI model evaluation datasets often fall short? Synopsis: Stable Marriages are generally computed from preference lists. Those consume too much memory. Instead, one can dynamically recalculate candidate lists using a scalable Vector Search engine. However, achieving this depends on having high-quality representations in a...| ashvardanian.com
A few years back, I found a simple trick in tandem with SIMD intrinsics to truly unleash the power of contemporary CPUs. I put the strstr of LibC and the std::search of the C++ Standard Templates Library to the test and hit a throughput of around 1.5 GB/s for substring search on a solitary core. Not too shabby, right? But imagine, that the memory bandwidth could theoretically reach a striking 10-15 GB/s per core.| ashvardanian.com
Vector Search is hot! Everyone is pouring resources into a seemingly new and AI-related topic. But are there any non-AI-related use cases? Are there features you want from your vector search engine, but are too afraid to ask? Last week was 🔥 for vector search. Weaviate raised $50M, and Pinecone raised $100M... That's a lot and makes you believe that vector search is hard. But it's not. I have spent the last few days implementing a single-file vector search engine.| ashvardanian.com
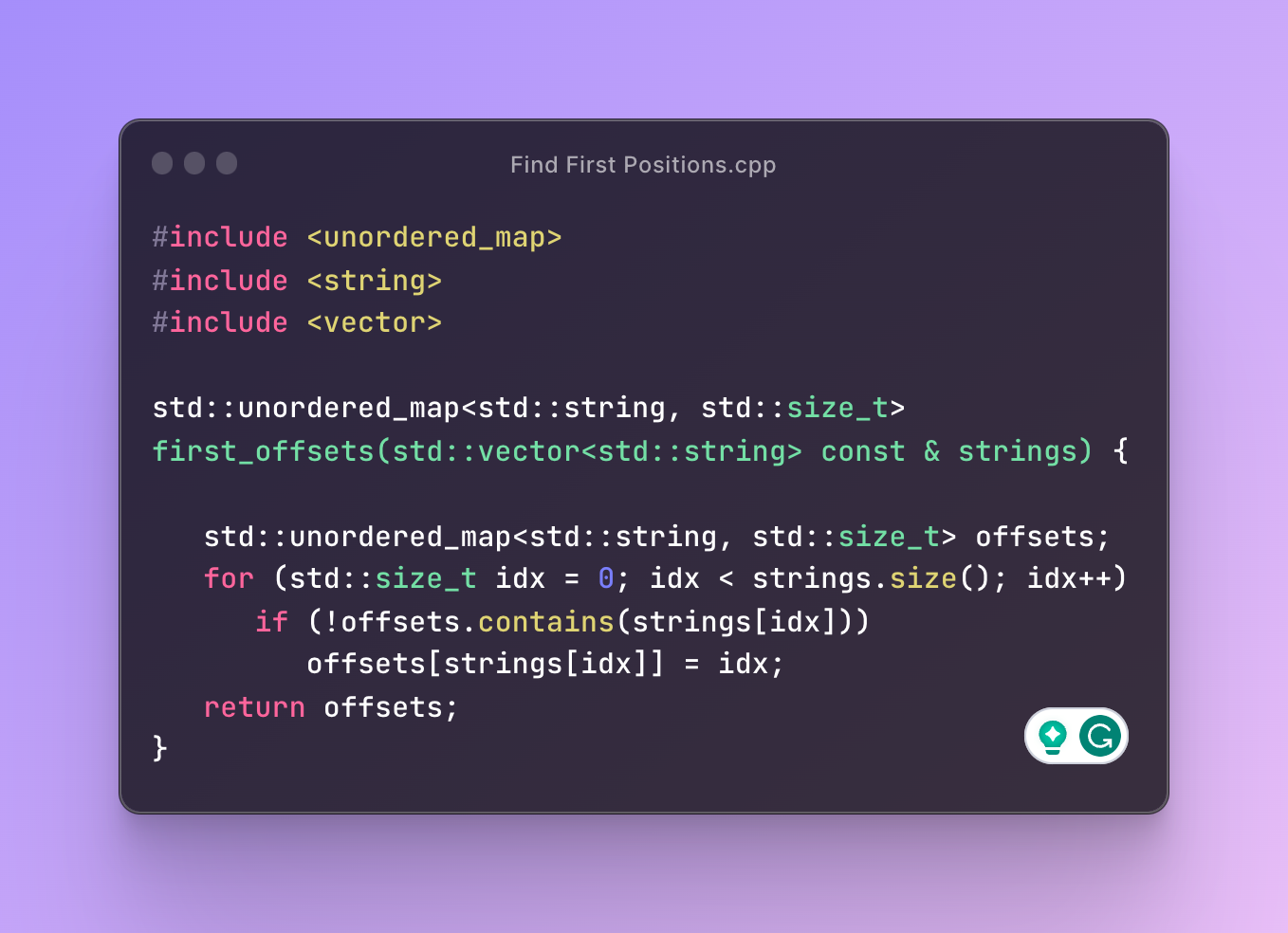
Some of the most common questions in programming interviews are about strings - reversing them, splitting, joining, counting, etc. These days, having to interview more and more developers across the whole spectrum, we see how vastly the solutions, even to the most straightforward problems, differ depending on experience. Let’s imagine a test with the following constraints: You must find the first occurrence of every unique string in a non-empty array. You are only allowed to use the standar...| ashvardanian.com
A bit of history. Not so long ago, we tried to use GPU acceleration from Python. We benchmarked NumPy vs CuPy in the most common number-crunching tasks. We took the highest-end desktop CPU and the highest-end desktop GPU and put them to the test. The GPU, expectedly, won, but not just in Matrix Multiplications. Sorting arrays, finding medians, and even simple accumulation was vastly faster. So we implemented multiple algorithms for parallel reductions in C++ and CUDA, just to compare efficiency.| ashvardanian.com
GPU acceleration can be trivial for Python users. Follow CUDA installation steps carefully, replace import numpy as np with import cupy as np, and you will often get the 100x performance boosts without breaking a sweat. Every time you write magical one-liners, remember a systems engineer is making your dreams come true. A couple of years ago, when I was giving a talk on the breadth of GPGPU technologies, I published a repo.| ashvardanian.com
This will be a story about many things: about computers, about their (memory) speed limits, about very specific workloads that can push computers to those limits and the subtle differences in Hash-Tables (HT) designs. But before we get in, here is a glimpse of what we are about to see. A friendly warning, the following article contains many technical terms and is intended for somewhat technical and hopefully curious readers.| ashvardanian.com
A single software company can spend over 💲10 Billion/year, on data centres, but not every year is the same. When all stars align, we see bursts of new technologies reaching the market simultaneously, thus restarting the purchasing super-cycle. 2022 will be just that, so let’s jump a couple of quarters ahead and see what’s on the shopping list of your favorite hyperscaler! Friendly warning: this article is full of technical terms and jargon, so it may be hard to read if you don’t writ...| ashvardanian.com
David Patterson had recently mentioned that (rephrasing): The programmers may benefit from using complex instruction sets directly, but it is increasingly challenging for compilers to automatically generate them in the right spots. In the last 3-4 years I gave a bunch of talks on the intricacies of SIMD programming, highlighting the divergence in hardware and software design in the past ten years. Chips are becoming bigger and more complicated to add more functionality, but the general-purpos...| ashvardanian.com
Borders are closed, people are sitting at home, but I bet most of you dream about traveling again. I want to invite you all to my country of origin - Armenia. It has something to offer to every group of people - tourists, entrepreneurs and investors!| ashvardanian.com
The bad news is coming from every direction. Still, I believe there are enough reasons to stay positive and excited about the future! Absurdly, this positive outlook was caused by 2 seemingly negative factors: Since the age of 15, I was convinced that the human race would likely face extinction in the 21st century. I was pretty confident that the threat would come in the form of virus, most likely from China.| ashvardanian.com
There are only two kinds of languages: the ones people complain about and the ones nobody uses. – Bjarne Stroustrup, creator of C++. Very few consider C++ attractive, and only some people think it’s easy. Choosing it for a project generally means you care about the performance of your code. And rightly so! Today, machines can process hundreds of Gigabytes per second, and we, as developers, should all learn to saturate those capabilities.| ashvardanian.com