Achieve secure AI and simplify compliance. Predibase's managed VPC provides a private cloud to fine-tune and serve LLMs and VLMs on sensitive data without it ever leaving your environment. Direct ingress means no data ever touches the public internet.| predibase.com
Reinforcement Learning (RL) enables AI to master skills via trial and error, rewarding good actions without pre-fed data. We'll explore its core process, benefits, approaches, and how to select the right one for your project.| Predibase.com RSS Feed
LLM distillation shrinks big AI models into fast, efficient ones that work great on phones or small devices. It saves money, energy, and keeps top performance for apps like chatbots. Learn more about its power and use cases.| Predibase.com RSS Feed
This guide dives into Hyperparameter Optimization (HPO), a powerful technique for boosting machine learning models. We’ll break down its process, benefits, and methods in a clear, straightforward way.| Predibase.com RSS Feed
Can AI learn to match human values? Reinforcement Learning from Human Feedback shapes AI with human input, making chatbots and content more trustworthy and effective for complex needs.| Predibase.com RSS Feed
Curious about models that learn without seeing examples? This quick guide dives into such methods, their mechanics, key aspects, benefits, different types, and how to pick the right one.| Predibase.com RSS Feed
LLM active learning helps models learn efficiently by choosing the best data. Here’s a simple breakdown of what it does, how it works, its advantages, types, and how to select a strategy.| Predibase.com RSS Feed
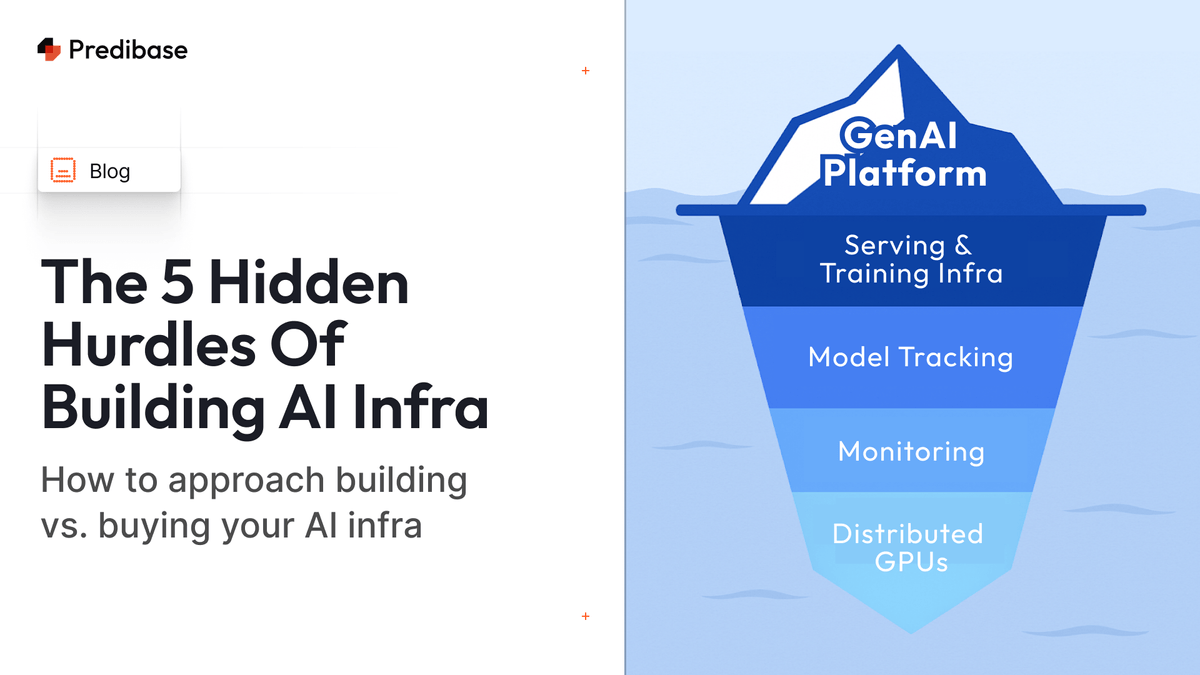
Build vs. buy your GenAI stack? Uncover 5 hidden pitfalls of serving LLMs and how the right approach can cut costs 10x, boost throughput 80%, and free teams to innovate.| predibase.com
We’re thrilled to announce that Predibase will be joining Rubrik, a leader in cybersecurity. Together, we’ll be building towards a shared vision at the intersection of AI, security, and data – the most important frontier in enterprise software.| Predibase.com RSS Feed
Discover how Predibase delivers up to 4x faster LLM inference vs vLLM & Fireworks using speculative decoding, chunked prefill, and managed AI infrastructure.| Predibase.com RSS Feed
Train expert coding agents with Reinforcement Fine-Tuning. See how Runloop + Predibase 2x’d performance for complex Stripe API tasks—using just 10 prompts.| Predibase.com RSS Feed
Learn how to accelerate and optimize deployments for open-source models with our blueprint for fast, reliable, and cost-efficient LLM serving. Deep dive on GPU autoscaling, multi-lora serving, speculative decoding, and more.| Predibase.com RSS Feed
Learn how to run Alibaba’s latest Qwen 3 family of models in your private cloud (VPC) or via Predibase’s managed SaaS in just a matter of minutes. Full breakdown of Qwen 3's features, GPU requirements, performance benchmarks, and serving options.| Predibase.com RSS Feed
Explore findings from a survey of over 500 AI professionals on DeepSeek-R1's adoption, challenges, and specialized applications.| Predibase.com RSS Feed
Learn how to deploy Llama 4 models—Scout and Maverick—in your virtual private cloud (VPC) or via Predibase’s managed SaaS. Full breakdown of GPU requirements, context length, performance benchmarks, and VPC deployments.| Predibase.com RSS Feed
Learn how to build, evaluate, and optimize reward functions for reinforcement fine-tuning (RFT) in LLMs—no data labels needed, just logic and feedback.| Predibase.com RSS Feed
Discover how Predibase's end-to-end reinforcement fine-tuning platform enables developers to build specialized AI models that outperform larger foundation models—even with limited labeled data.| Predibase.com RSS Feed
Marsh McLennan revolutionized enterprise knowledge with LenAI, an agentic AI assistant fine‐tuned by Predibase. LenAI achieved 10–12% higher accuracy, saving 1M+ team hours in its first year and empowering 90K+ employees with rapid insights.| Predibase.com RSS Feed
Discover how we doubled throughput on reasoning models like DeepSeek-R1-Distill-Qwen-32B with Turbo Speculation without sacrificing reasoning quality. Learn how self-distillation and speculative decoding enhance AI efficiency and performance.| Predibase.com RSS Feed
In this post, we’ll discuss how we taught an AI model to convert PyTorch code into efficient Triton kernels using a reinforcement learning algorithm inspired by PPO called Group Relative Preference Optimization (GRPO).| Predibase.com RSS Feed
Explore how reinforcement fine-tuning outperforms supervised fine-tuning in data-scarce scenarios. Learn about the advantages of reinforcement learning techniques in optimizing machine learning models with limited data| Predibase.com RSS Feed
Learn how to deploy DeepSeek-R1-Distill-Qwen-32B efficiently in your cloud or via Predibase SaaS. Compare performance, hardware needs, and deployment options for cost-effective, secure AI scaling.| Predibase.com RSS Feed
By employing reinforcement learning (RL), DeepSeek-R1 not only matches but in some aspects surpasses established giants like OpenAI’s o1. This demonstrates that the future of AI hinges on smarter learning techniques rather than merely expanding datasets.| Predibase.com RSS Feed
While instruction-tuned models such as Llama-3.2-11B-Vision-Instruct boast impressive results out-of-the-box, our prior work with LLMs highlights the potential of fine-tuning to further improve model quality.| Predibase.com RSS Feed
As we close out another transformative year at Predibase, we’re excited to share a summary of the most significant advancements and new capabilities we've introduced in the latter half of this year.| Predibase.com RSS Feed
Convirza achieved a 10x reduction in operational costs compared to OpenAI, an 8% improvement in F1 scores, and increased throughput by 80%, allowing them to efficiently serve over 60 performance indicators across thousands of customer interactions daily.| Predibase.com RSS Feed
Predibase's Inference Engine Harnesses LoRAX, Turbo LoRA, and Autoscaling GPUs to 3-4x Throughput and Cut Costs by Over 50% While Ensuring Reliability for High Volume Enterprise Workloads.| Predibase.com RSS Feed
We’re excited to share a host of product updates that make fine-tuning and serving SLMs in production on Predibase easier, more reliable, and more cost effective than ever.| Predibase.com RSS Feed
Predibase's Deployment Health Analytics are designed to give you real-time insights into the health of your deployments and track crucial metrics that help you balance performance and cost.| Predibase.com RSS Feed
Solar-Proofread achieved 79% accuracy for a major international media company with a daily circulation of over 1.8 million, surpassing both base and fine-tuned GPT-4o mini| Predibase.com RSS Feed
Turbo LoRA is a new parameter-efficient fine-tuning method we’ve developed at Predibase that increases text generation throughput by 2-3x while simultaneously achieving task-specific response quality in line with LoRA.| Predibase.com RSS Feed
In this technical deep dive, we explore 9 strategies for increasing fine-tuning speed including Batch Size Tuning, Sample Packing and more.| Predibase.com RSS Feed
The future of GenAI and LLMs is small, task-specific LoRA adapters. We explore Apple's new reference architecture and how to get started building your own small-language models.| Predibase.com RSS Feed
We’re very excited to have recently launched a new short course on DeepLearning.AI developed by our CTO Travis Addair called “Efficiently Serving LLMs”.| Predibase.com RSS Feed
We’ve recently made some major improvements that make fine-tuning jobs 2-5x faster! You can also view and manage your deployments from one place in the UI, and we’ve made training checkpoints more useful in case fine-tuning jobs fail or get stopped.| Predibase.com RSS Feed
We’re excited to release a major update to the Predibase platform that enables teams to view and manage LLM deployments in the UI.| Predibase.com RSS Feed
On February 20th we launched LoRA Land to demonstrate how fine-tuned open-source LLMs can rival or outperform GPT-4 on task-specific use cases for a fraction of the cost! Catch up on recent webinars, blog posts, and exciting stories from the community.| Predibase.com RSS Feed
Learn two methods for extracting JSON using LLMs: structured generation and fine-tuning. You’ll see how to specify an Outlines-compatible schema in your request to generate structured outputs and create a LoRA adapter for extracting the desired values.| Predibase.com RSS Feed
In this tutorial, you'll learn how to easily and efficiently fine-tune Gemma-7B on commodity hardware using open-source Ludwig, the open-source framework for fine-tuning LLMs through a declarative, YAML-based interface.| Predibase.com RSS Feed
Check out the most recent improvements to Predibase! Whether you’re looking to migrate from OpenAI, want to start fine-tuning models like Mixtral-8x7b for free, or are curious about some of our recent performance improvements, read on!| Predibase.com RSS Feed
Fine-tune CodeLlama-70B Instruct models in minutes using Predibase. Learn how to use our low-code platform to train and deploy high-performing CodeLlama variants with minimal setup and maximum efficiency.| Predibase.com RSS Feed
Check out the winning projects and notebooks from our virtual LLM fine-tuning hackathon. Projects include an LLM that generates data quality checks, a Q&A system for tax questions, a customer service intent classifier, and more.| Predibase.com RSS Feed
From the coming wave of small language models to the future of fine-tuning and LLM architectures, these predictions represent the collective thoughts of our team of AI experts with experience building ML and LLM applications at Uber, AWS, Google, and more.| Predibase.com RSS Feed
2024 is off to an exciting start! In this issue we share a new customer story from Paradigm, tutorials for fine-tuning Mistral and Mixtral 8x7b, and our predictions for 2024!| Predibase.com RSS Feed
Learn how one of the world's largest liquidity networks for crypto built a deep learning powered recommendation system in only a few days with Predibase and Snowflake.| Predibase.com RSS Feed
This issue includes our most popular talks and blogs from the year including 12 Best Practices for Distilling Smaller LLMs with GPT and Why the Future of AI is Specialized. Check it out to get caught up on all things LLMs and AI.| Predibase.com RSS Feed
This blog post draws from our experience distilling language models at Google and Predibase, combined with a review of recent LLM research. We present 12 best practices for the efficient refinement of LLMs.| Predibase.com RSS Feed
Learn how to easily and efficiently fine-tune Zephyr-7B-Beta for a customer support use case using open-source Ludwig and Predibase. This step-by-step tutorial includes sample call center transcript data, code and notebooks so you can follow along.| Predibase.com RSS Feed
Learn how to fine-tune Mixtral and Mistral 7B models using open-source Ludwig on Predibase. Step-by-step guide with GitHub repo, code, and performance tips.| Predibase.com RSS Feed
In this blogpost I will make the case for why smaller, faster, fine-tuned LLMs are poised to take over large, general AI models.| Predibase.com RSS Feed
In this blog post, we’ll showcase optimizations in open-source Ludwig to make fine-tuning Llama-2-70B possible, as well as demonstrate the benefits of fine-tuning over OpenAI’s GPT-3.5 and GPT-4 for structured JSON generation.| Predibase.com RSS Feed
In this tutorial, we will show you how–with less than an hour of setup and configuration time–to fine-tune and serve a large language model like CodeLlama-7b to perform in-line Python docstring generation using only 5,800 data rows for fine-tuning.| Predibase.com RSS Feed
Koble set out to develop a powerful AI solution to automate the evaluation of early stage startup investments and provide them with access to capital in minutes, not months. Learn how they used Predibase to build and deploy custom AI models and LLMs.| Predibase.com RSS Feed
In celebration of our 10,000th star on Github, we're giving away a premium Ludwig swag pack to 5 avid Ludwig developers. Share your Ludwig projects to enter in the competition.| Predibase.com RSS Feed
Read this tutorial to learn how to fine-tune and optimize your own LLM for code generation in a few simple steps with open-source Ludwig.| Predibase.com RSS Feed
We are thrilled to announce our new Python SDK for efficient LLM fine-tuning and serving as well as early access to the Predibase AI Cloud with access to A100 GPUs. This new offering enables developers to train smaller, task-specific LLMs using any GPU.| Predibase.com RSS Feed
Learn how to fine-tune the Mistral 7B model using Ludwig on a single GPU. This guide provides step-by-step instructions for efficient fine-tuning, leveraging Hugging Face tools for optimal performance| Predibase.com RSS Feed
Large language models (LLMs) have exploded in popularity recently, showcasing impressive natural language generation capabilities. However, there is still a lot of mystery surrounding how these complex AI systems work and how to use them most effectively.| Predibase.com RSS Feed
In this blog we explore the results of our recent survey covering topics such as what it takes to be successful with LLMs, the challenges organizations face putting LLMs into production, and recommendations moving forward.| Predibase.com RSS Feed
Learn how to use Predibase to leverage the natural language abilities of LLMs on a task traditionally regarded as the domain of gradient-boosting models — predictions on tabular data.| Predibase.com RSS Feed
Where does tabular data fit in the new world of LLMs? In this detailed and metric driven analysis, we explore the pros and cons of using LLMs for tabular data and how to achieve the best results for zero-shot tasks.| Predibase.com RSS Feed
Ludwig v0.8 is the first open-source low-code framework optimized for efficiently building custom LLMs on your private data. We introduced a number of new features a like fine-tuning, integration with Deepspeed, Parameter efficient fine-tuning and more.| Predibase.com RSS Feed
Learn how to prevent overfitting in machine learning. Explore practical steps to detect and fix overfit models and improve ML model generalization.| Predibase.com RSS Feed
In this tutorial, you will learn how to overcome the challenges of fine-tuning LLaMa-2 (and any LLM) with simple configurations and scalable managed LLM infrastructure.| Predibase.com RSS Feed
Chatbots have become synonymous with large language models and while they provide a lot of utility, they only represent a fraction of the value that LLMs can deliver. Read on to explore five high-value use cases for LLMs along with demo video tutorials.| Predibase.com RSS Feed
In this tutorial, you’ll learn how to build an end-to-end ML pipeline for Credit Card Fraud Detection experimenting with neural networks and GBM models. You’ll also learn how to address class imbalance using metrics like precision and recall.| Predibase.com RSS Feed
Learn how to train and operationalize a machine learning model that performs named entity recognition on molecular biology text corpuses in less than an hour with declarative ML. Sample code, data and notebook provided.| Predibase.com RSS Feed
Topic classification is an important ML use case for any organization with large volumes of unstructured text. Learn how to build an end-to-end topic classification model with Predibase, the low-code declarative ML platform, and open-source Ludwig.| Predibase.com RSS Feed
Ludwig v0.7 is here, bringing a data-centric and declarative interface to fine-tuning state of the art computer vision (image) and NLP (text) models in just a few lines of YAML.| Predibase.com RSS Feed
In this blog post, we will show how you can easily train, iterate, and deploy a highly-performant ML model on a multi-modal dataset that can be used to predict customer review ratings. Sample notebooks included.| Predibase.com RSS Feed
Thoughts on 2023 from machine learning experts with experience at Uber, Apple, Google, AWS and other leading big data companies.| Predibase.com RSS Feed
Ludwig, the open-source declarative ML framework, now supports gradient boosted tree models (GBM) in addition to neural networks (NN). GBMs perform well and train fast for tabular data. Learn more about how it compares to NN and get started.| Predibase.com RSS Feed
Declarative ML has the potential to reduce the time, effort, and skills required to bring ML into production in a wide range of enterprise environments.| Predibase.com RSS Feed
Authors: Anne Holler, Avanika Narayan, Justin Zhao, Shreya Rajpal, Daniel Treiman, Devvret Rishi, Travis Addair, Piero Molino Ludwig is an open-source declarative deep learning (DL) framework that…| Predibase.com RSS Feed
BERT is a state-of-the-art model introduced in BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Devlin et al. (2019), that uses the Transformer architecture…| Predibase.com RSS Feed
Ludwig is a user-friendly deep learning toolbox that allows users to train and test deep learning models on a variety of applications, including many natural language processing ones like sentiment…| Predibase.com RSS Feed
Pricing listed below is for the consumption-based SaaS tier of Predibase. This self-serve, pay-as-you-go pricing is currently in early access for select customers and will be going GA later this year. This model applies to single users on our managed SaaS infrastructure.| predibase.com
Predibase offers the largest selection of open-source LLMs for fine-tuning and inference including Llama-3, CodeLlama, Mistral, Mixtral, Zephyr and more. Take advantage of our cost-effective serverless endpoints or deploy dedicated endpoints in your VPC.| predibase.com
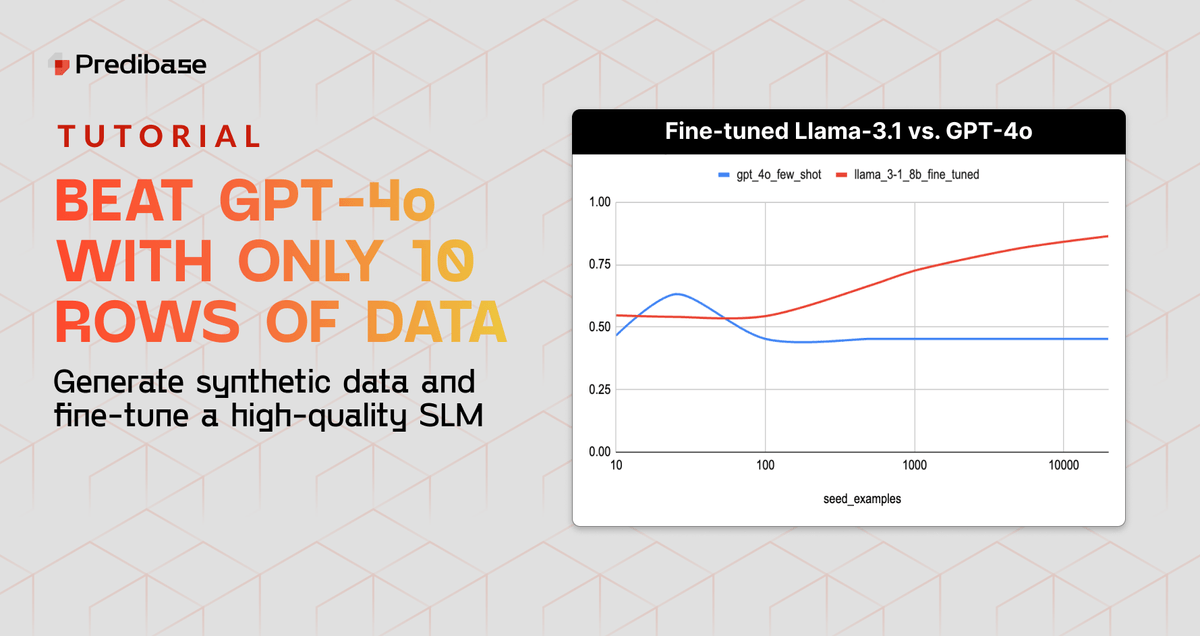
In this tutorial and notebook, you’ll learn how to create an effective synthetic dataset with only 10 examples and fine-tune a SLM that outperforms GPT-4o. We’ll explore different techniques including chain-of-thought reasoning and mixture of agents (MoA).| predibase.com
Learn how Checkr used Predibase to fine-tune a small open-source language model that is more accurate, 5x cheaper, and 30x faster than OpenAI.| predibase.com
Discover how LoRA adapters and LoRA tuning revolutionize fine-tuning of large language models (LLMs) by enabling efficient and cost-effective customization of large language models. Explore the future of LoRA tuning in machine learning.| predibase.com
The index highlights how fine-tuning open-source LLMs significantly boosts their performance in production and ranks top open-source and commercial LLMs by performance across various tasks, based on insights from over 700 fine-tuning experiments.| predibase.com
Step-by-step guide to fine-tuning Llama 3 8B for automated customer support: Learn how to train Llama-3 Instruct on your data, optimize classification prompts, and adapt from pre-training. Includes code examples and best practices| predibase.com
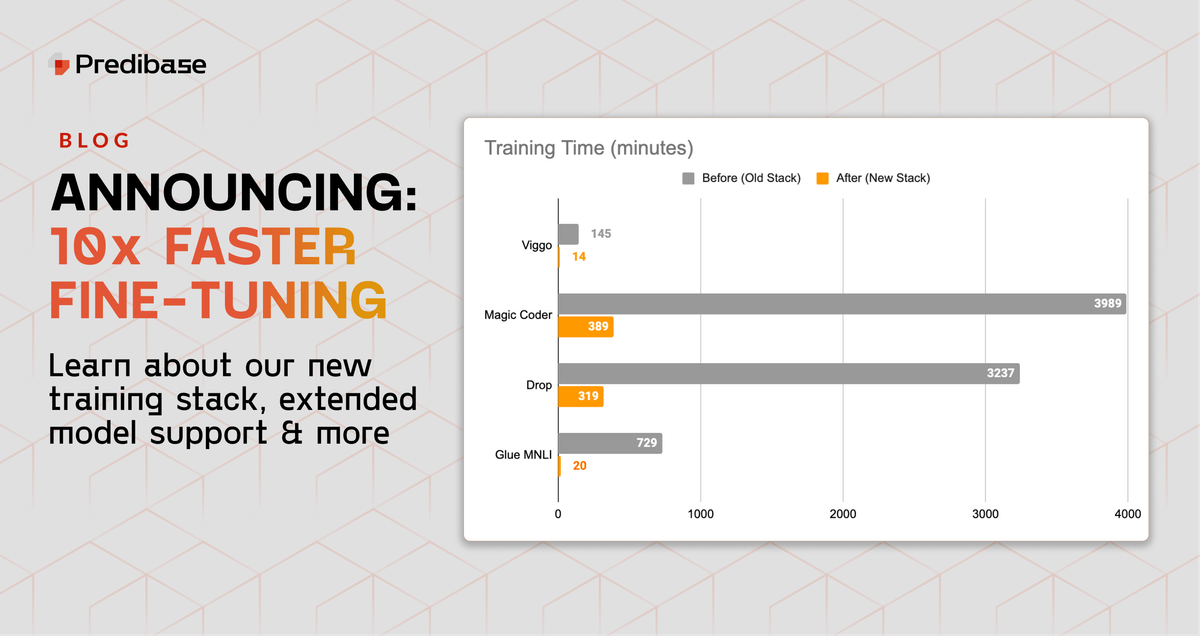
Learn about our new industry leading fine-tuning stack which provides 10x faster training speeds, broader support for models like Llama-3 and other capabilties.| predibase.com
LoRA Land is a collection of 25+ fine-tuned Mistral-7b models that outperform GPT-4 in task-specific applications. This collection of fine-tuned OSS models offers a blueprint for teams seeking to efficiently and cost-effectively deploy AI systems.| predibase.com
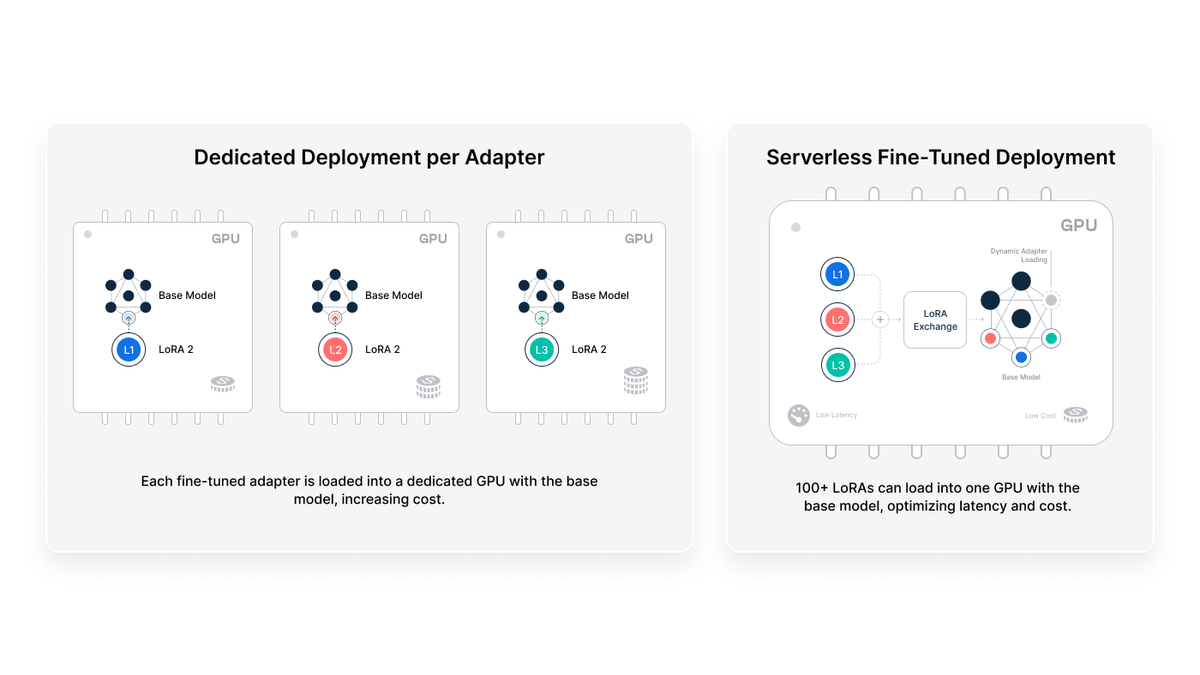
Serverless Fine-tuned Endpoints allow users to query their fine-tuned LLMs without spinning up a dedicated GPU deployment. Only pay for what you use, not for idle GPUs. Try it today with Predibase’s free trial!| predibase.com