
Authorizing users and authenticating with Flow | Estuary Flow Documentation
Read, write, and admin capabilities over Flow catalogs and the collections that comprise them| docs.estuary.dev
Read, write, and admin capabilities over Flow catalogs and the collections that comprise them| docs.estuary.dev
This guide walks you through the process of creating an end-to-end Data Flow.| docs.estuary.dev
Connectors bridge the gap between Flow and| docs.estuary.dev
A capture is how Flow ingests data from an external source.| docs.estuary.dev
The following tutorial sections use an illustrative example| docs.estuary.dev
Flow documents and collections always have an associated schema| docs.estuary.dev
Catalog tasks — captures, derivations, and materializations —| docs.estuary.dev
Learn how to configure Flow to use your cloud storage| docs.estuary.dev
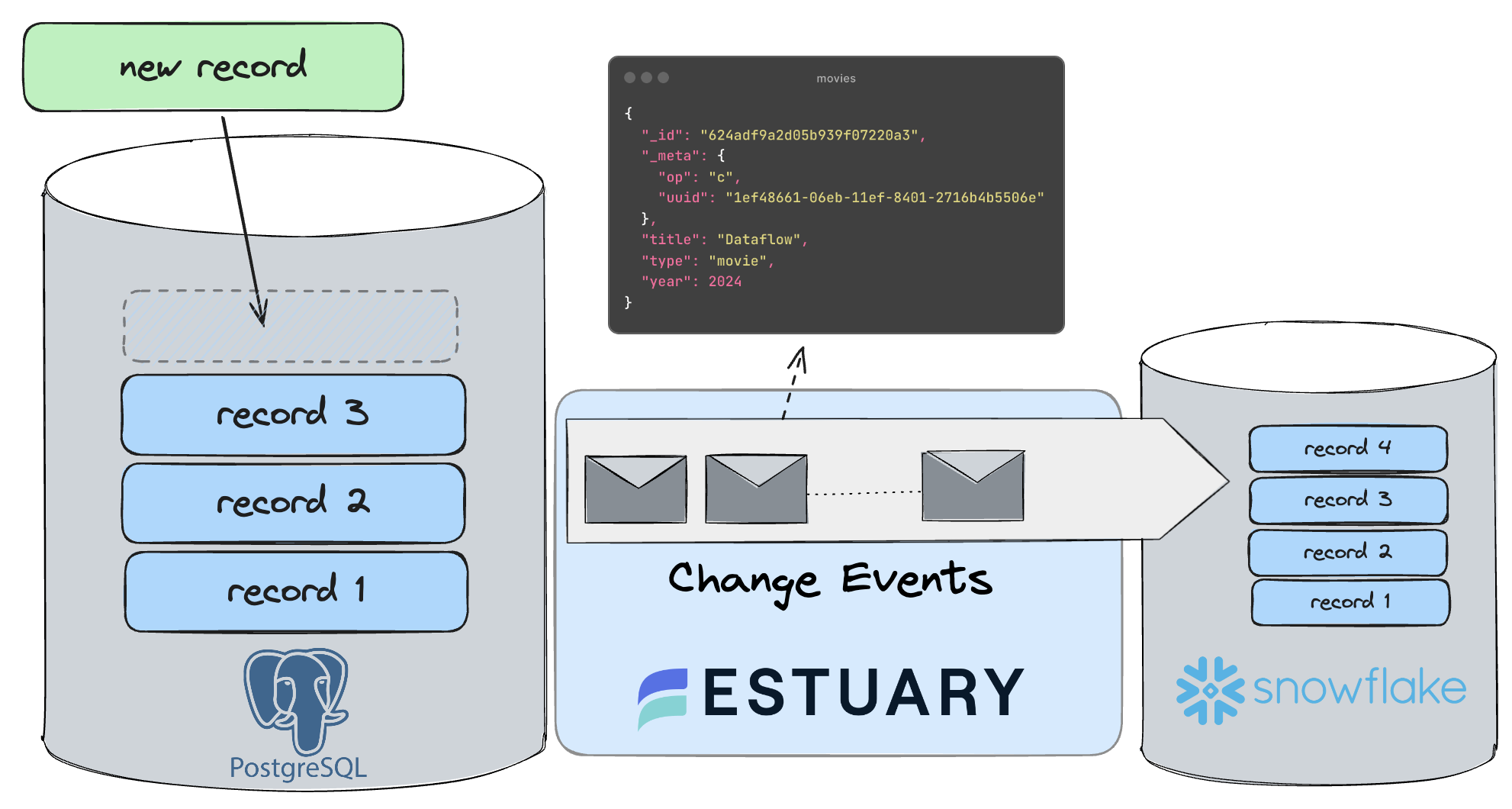
Flow helps you define data pipelines, known as Data Flows, that connect multiple data systems, APIs, and storage, and optionally transform data along the way.| docs.estuary.dev
Flow stores the documents that comprise your collections in a cloud storage bucket.| docs.estuary.dev
A materialization is how Flow pushes data to an external destination.| docs.estuary.dev
The documents of your Data Flows are stored in collections:| docs.estuary.dev
Projections are an advanced concept of Flow.| docs.estuary.dev
At times, the collections generated by a capture may not be suitable for your needs.| docs.estuary.dev
