
Selecting The Right AI Evals Tool – Hamel’s Blog
An example of how to assess AI eval tools like Langsmith, Braintrust, and Arize Phoenix.| Hamel's Blog
| hamel.dev
An example of how to assess AI eval tools like Langsmith, Braintrust, and Arize Phoenix.| Hamel's Blog
For years, I’ve relied on a straightforward method to identify sudden changes in model inputs or training data, known as “drift.” This method, Adversarial Validation1, is both simple and effective. The best part? It requires no complex tools or infrastructure. Examples where drift can cause bugs in your AI: Your data for evaluations are materially different from the inputs your model receives in production, causing your evaluations to be misleading. Updates to prompts, functions, RAG, a...| Hamel's Blog
Here is my personal opinion about the questions I posed in this tweet: There are a growing number of voices expressing disillusionment with fine-tuning. I'm curious about the sentiment more generally. (I am withholding sharing my opinion rn). Tweets below are from @mlpowered@abacaj@emollickpic.twitter.com/cU0hCdubBU — Hamel Husain (@HamelHusain) March 26, 2024 --- I think that fine-tuning is still very valuable in many situations. I’ve done some more digging and I find that people who say...| Hamel's Blog
Motivation Axolotl is a great project for fine-tuning LLMs. I started contributing to the project, and I found that it was difficult to debug. I wanted to share some tips and tricks I learned along the way, along with configuration files for debugging with VSCode. Moreover, I think being able to debug axolotl empowers developers who encounter bugs or want to understand how the code works. I hope this document helps you get started. This content is now part of the Axolotl docs! I contributed t...| Hamel's Blog

Like Heroku, but you own it.| Hamel's Blog

A collection of technical blogs and talks on machine learning and data science.| Hamel's Blog

Evaluation methods, data-driven improvement, and experimentation techniques from 30+ production implementations.| Hamel's Blog
People often find me through my writing on AI and tech. This creates an interesting pattern. Nearly every week, vendors reach out asking me to write about their products. While I appreciate their interest and love learning about new tools, I reserve my writing for topics that I have personal experience with. One conversation last week really stuck with me. A founder confided, “We can write the best content in the world, but we don’t have any distribution.” This hit home because I used t...| Hamel's Blog
Earlier this year, I wrote Your AI product needs evals. Many of you asked, “How do I get started with LLM-as-a-judge?” This guide shares what I’ve learned after helping over 30 companies set up their evaluation systems. The Problem: AI Teams Are Drowning in Data Ever spend weeks building an AI system, only to realize you have no idea if it’s actually working? You’re not alone. I’ve noticed teams repeat the same mistakes when using LLMs to evaluate AI outputs: Too Many Metrics: Cre...| Hamel's Blog
Background Lots of people experience fiddly behavior when using LLMs. For example: Unironically I found this to be very helpful when prompting LLMs. Giving them spaces and new lines pic.twitter.com/vVuxcCuDzB — anton (@abacaj) November 24, 2023 If you aren’t careful, these can be very hard to debug. This is because of the subtle ways tokenizers work that is not always easy to see by looking at the text. Example The below example demonstrates how things can get confusing and can drift betw...| Hamel's Blog

A free survey course on LLMs, taught by practitioners.| Hamel's Blog

Quickly understand inscrutable LLM frameworks by intercepting API calls.| hamel.dev
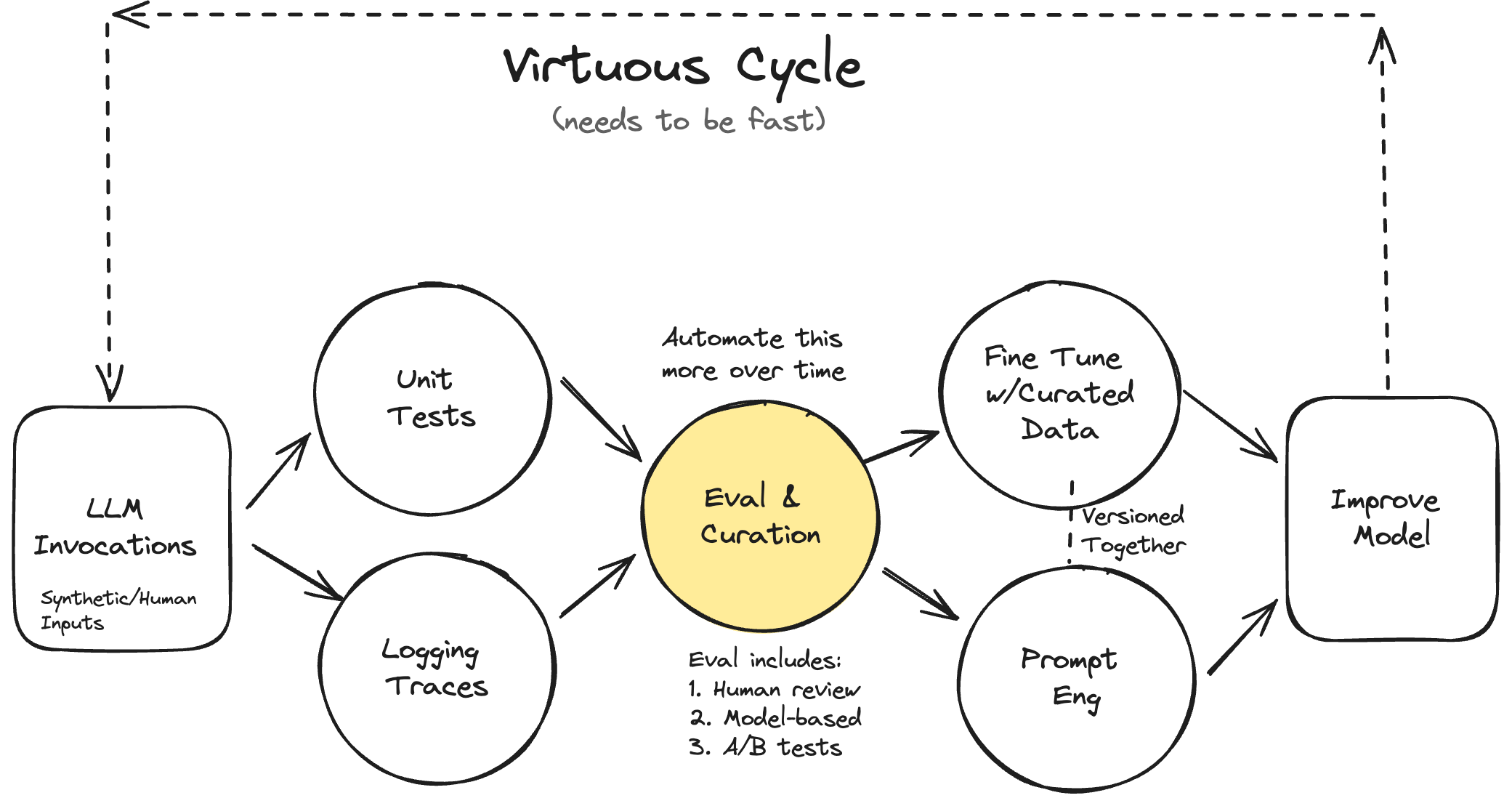
How to construct domain-specific LLM evaluation systems.| hamel.dev

