
From Pokémon Red to Standardized Game-as-an-Eval | Hao AI Lab @ UCSD
From Pokémon Red to Standardized Game-as-an-Eval - Hao AI Lab @ UCSD| hao-ai-lab.github.io
TL;DR: We propose Lookahead Reasoning (LR), a technique that significantly accelerates large reasoning models(LRMs) and complements existing speculative decoding methods. Traditional token-level speculative decoding suffers from limited gains because the probability of correctly guessing a long sequence decreases exponentially with length. In contrast, LR operates at the step level, proposing future reasoning steps instead of individual tokens. This is much more effective since a proposed ste...| Blogs on Hao AI Lab @ UCSD
| Blogs on Hao AI Lab @ UCSD
| Blogs on Hao AI Lab @ UCSD
From Pokémon Red to Standardized Game-as-an-Eval - Hao AI Lab @ UCSD| hao-ai-lab.github.io

TL;DR: We introduce FastWan, a family of video generation models trained via a new recipe we term as “sparse distillation”. Powered by FastVideo, FastWan2.1-1.3B end2end generates a 5-second 480P video in 5 seconds (denoising time 1 second) on a single H200 and 21 seconds (denoising time 2.8 seconds) on a single RTX 4090. FastWan2.2-5B generates a 5-second 720P video in 16 seconds on a single H200. All resources — model weights, training recipe, and dataset — are released under the Ap...| hao-ai-lab.github.io
TL;DR: We are announcing FastVideo V1, a unified framework that accelerates video generation. This new version features a clean, consistent API that works across popular video models, making it easier for developers to author new models and incorporate system - or kernel - level optimizations. For example, FastVideo V1 provides 3x speedup for inference while maintaining quality by seamlessly integrating SageAttention and Teacache. What’s New Modern open-source video generation models such a...| Blogs on Hao AI Lab @ UCSD
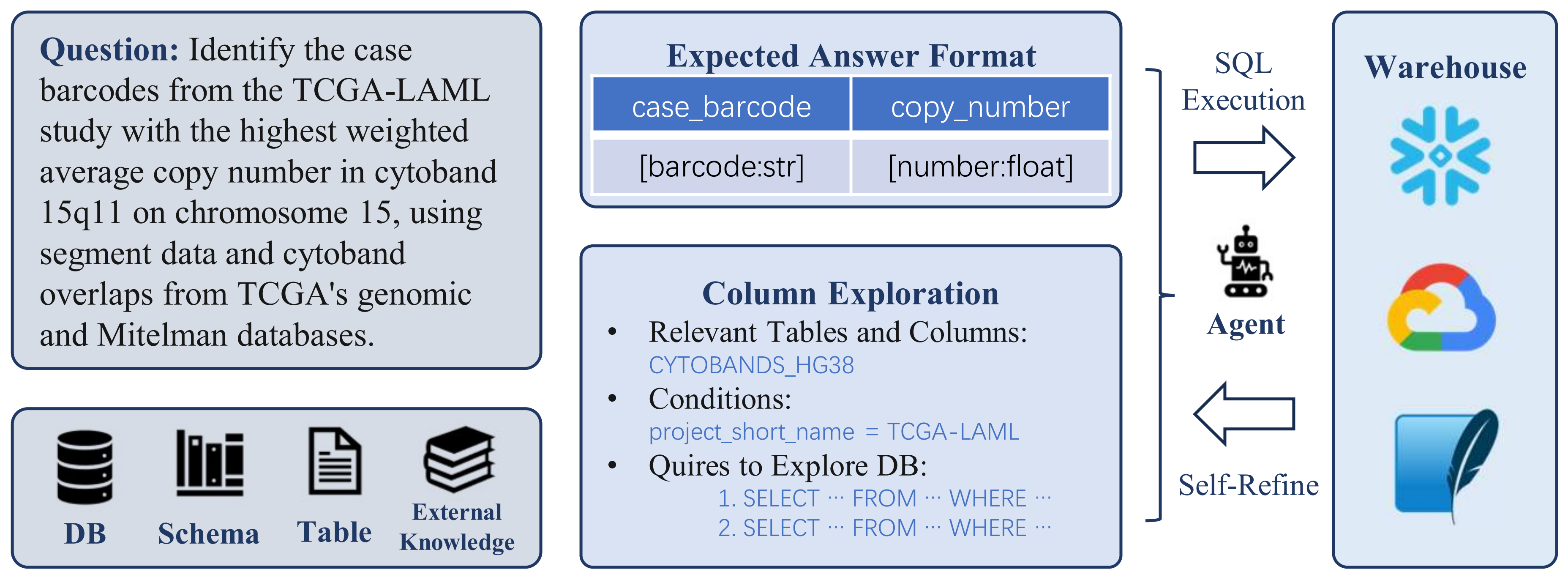
TL;DR: We present ReFoRCE, a Text-to-SQL agent that leads the Spider 2.0 leaderboard—the most challenging Text-to-SQL benchmark where even advanced models like GPT-4o score around 10%. ReFoRCE tackles real-world deployment issues such as massive schemas, SQL dialect diversity, and complex queries. It uses table compression to handle long contexts, format restriction for accurate SQL generation, and iterative column exploration for better schema understanding. A self-refinement pipeline with...| hao-ai-lab.github.io
TL;DR: We observe reasoning models often exhibit poor token efficiency: they waste many tokens second-guessing themselves. We develop Dynasor-CoT, a certainty-based approach for dynamically allocating inference compute for reasoning models. The intuition is that by probing reasoning models at intermediate steps, we can identify and early terminate problems where they maintain consistently high certainty in their answers. The method is plug-and-play, requiring no model modifications or trainin...| Blogs on Hao AI Lab @ UCSD

GameArena: Evaluating LLM Reasoning through Live Computer Games - Hao AI Lab @ UCSD| hao-ai-lab.github.io
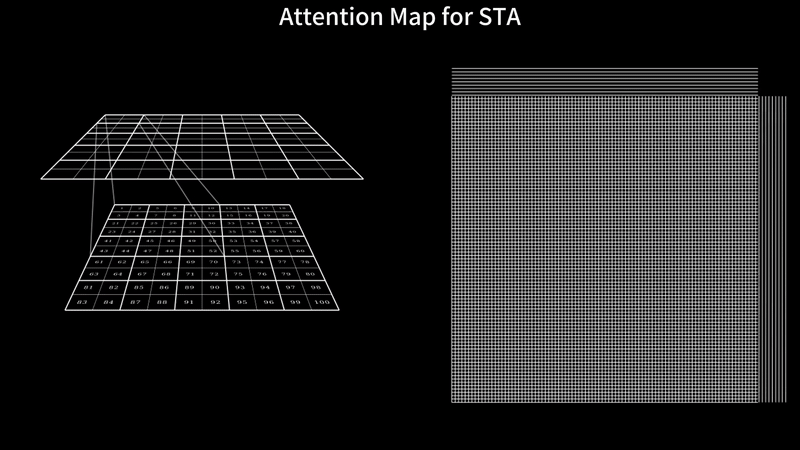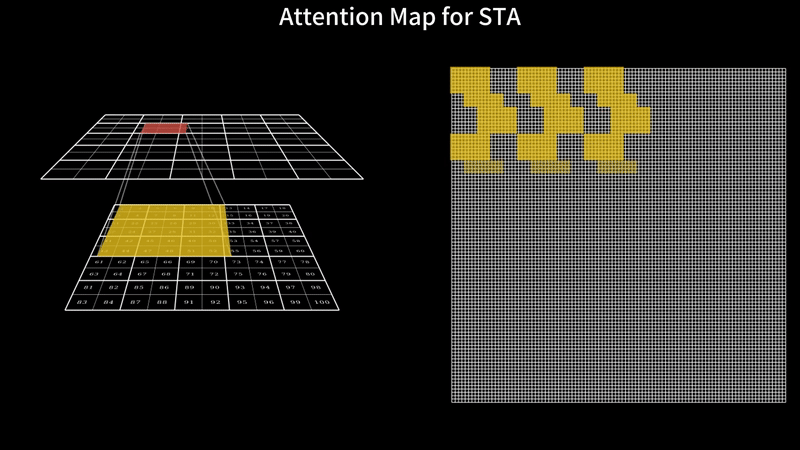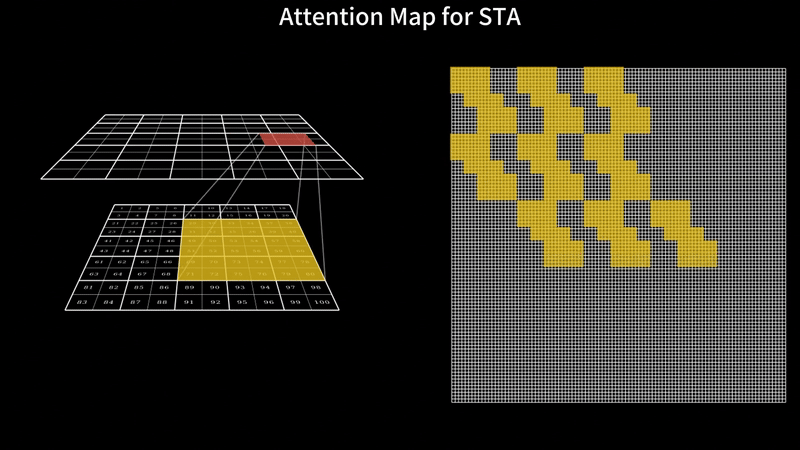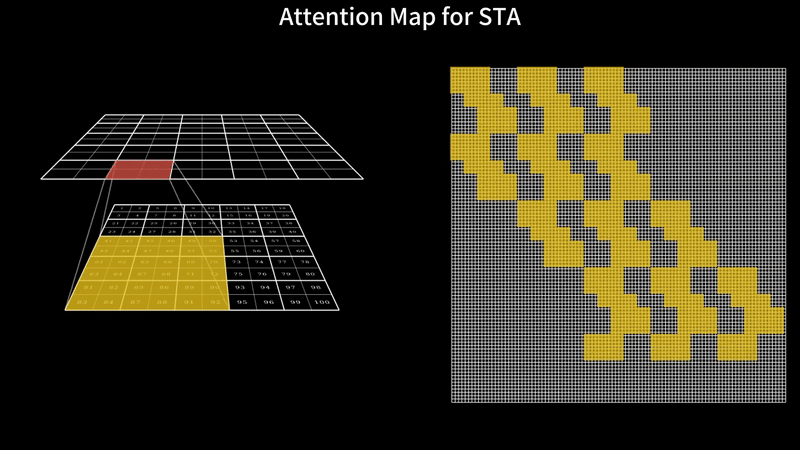
TL;DR: Video generation with DiTs is painfully slow – HunyuanVideo takes 16 minutes to generate just a 5-second video on an H100 with FlashAttention3. Our sliding tile attention (STA) slashes this to 5 minutes with zero quality loss, no extra training required. Specifically, STA accelerates attention alone by 2.8–17x over FlashAttention-2 and 1.6–10x over FlashAttention-3. With STA and other optimizations, our solution boosts end-to-end generation speed by 2.98× compared to the FA3 ful...| hao-ai-lab.github.io

TL;DR: Traditional Large Language Model (LLM) serving systems rely on first-come-first-serve (FCFS) scheduling. When longer requests block shorter ones in the queue, this creates a cascade of delays that severely impacts overall system latency. LLM inference jobs are particularly challenging to schedule due to their highly unpredictable workload and variable output lengths. We developed a novel learning to rank approach that predicts the relative ranking of output lengths, enabling a more eff...| hao-ai-lab.github.io
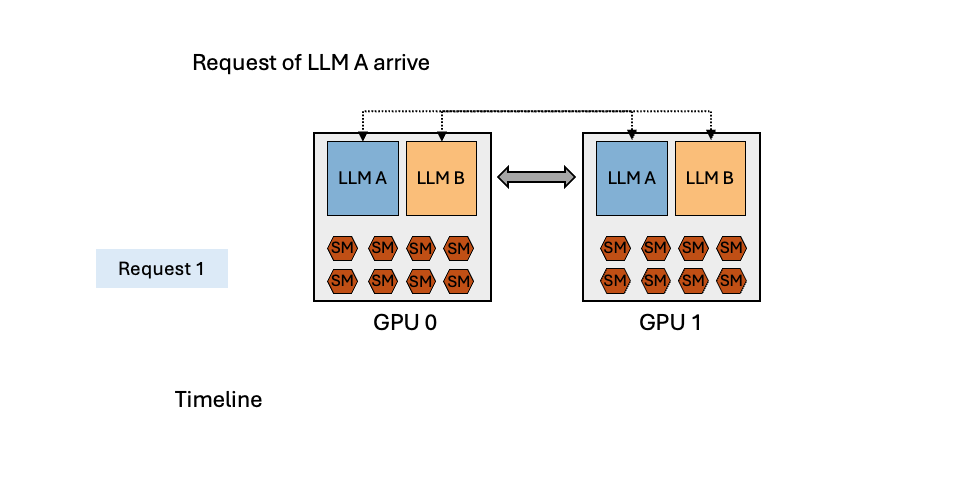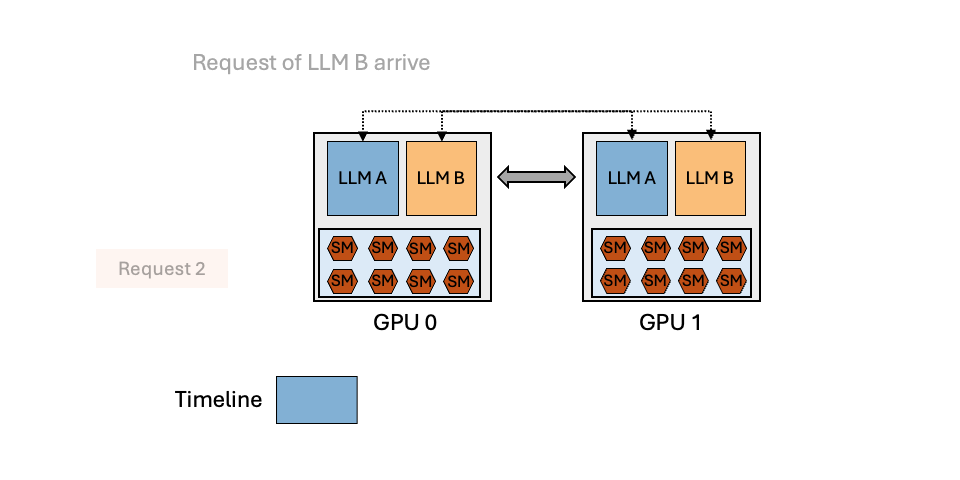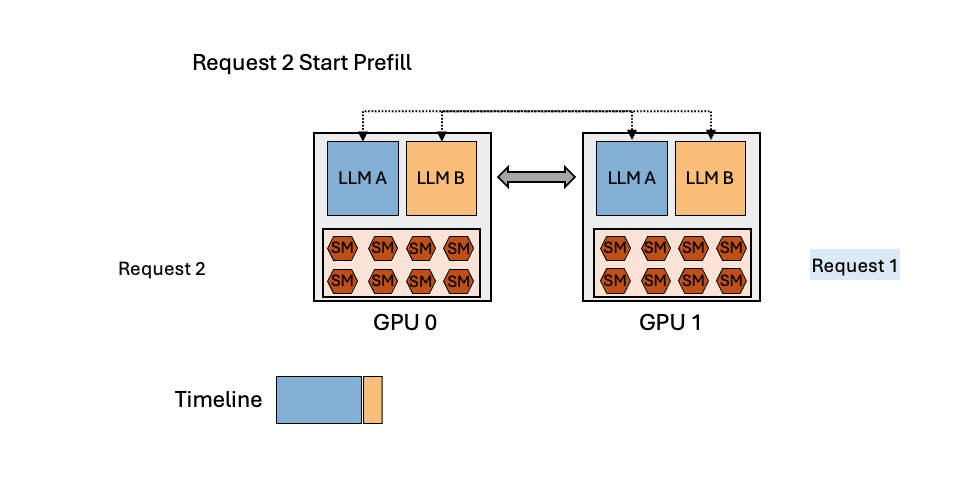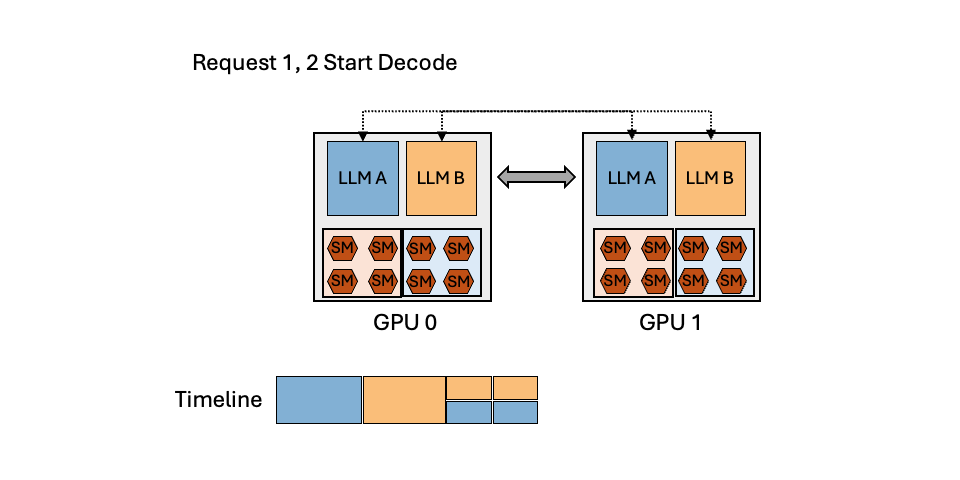
TL;DR: Efficiently serving multiple LLMs have emerged as a crucial and time-sensitive demand within the community, especially for LLM endpoint providers. In this blog, we show that the dynamic popularity of LLMs and the unbalanced resource utilization of LLM inference can be leveraged to achieve high GPU utilization and reduce serving cost. We introduce MuxServe, a novel serving system that efficiently serves multiple LLMs with flexible spatial-temporal multiplexing. MuxServe outperforms the ...| hao-ai-lab.github.io
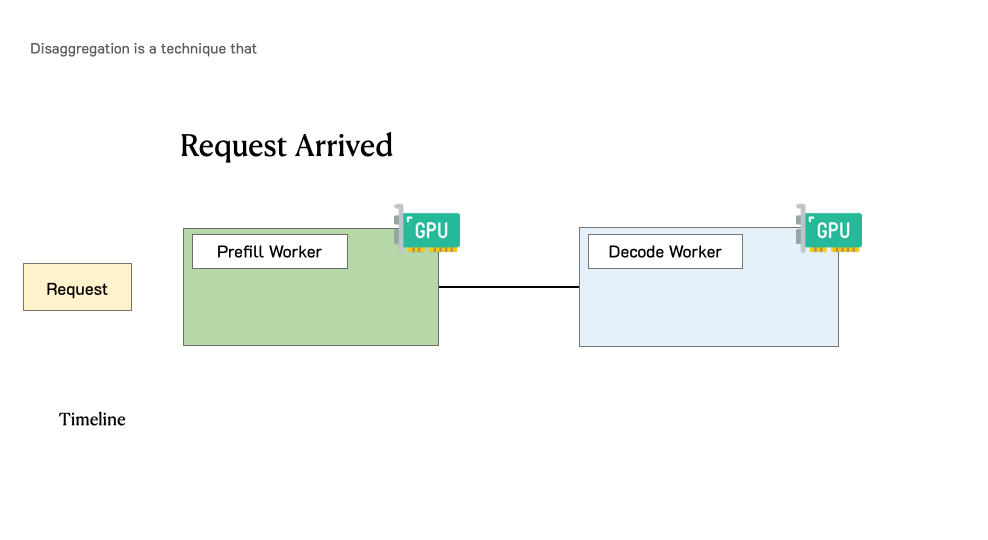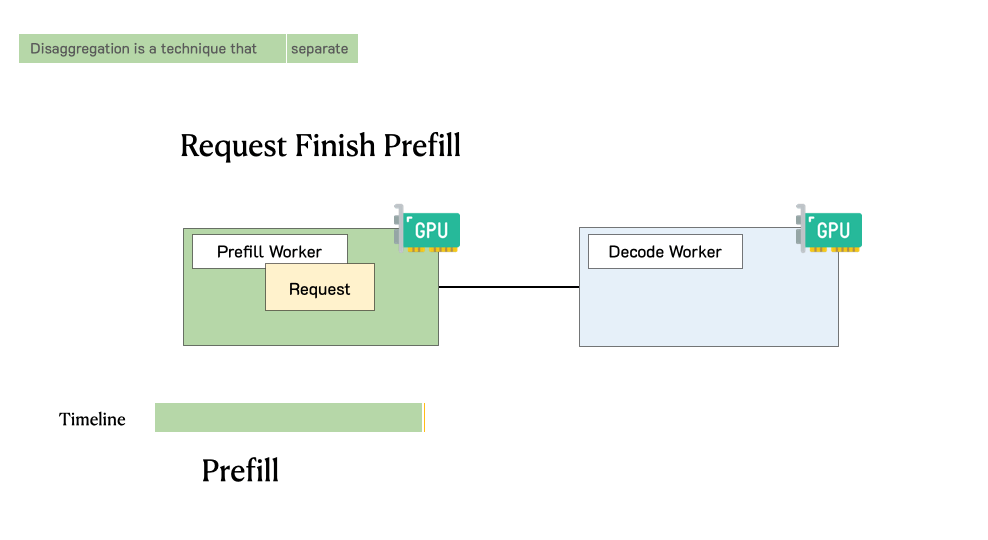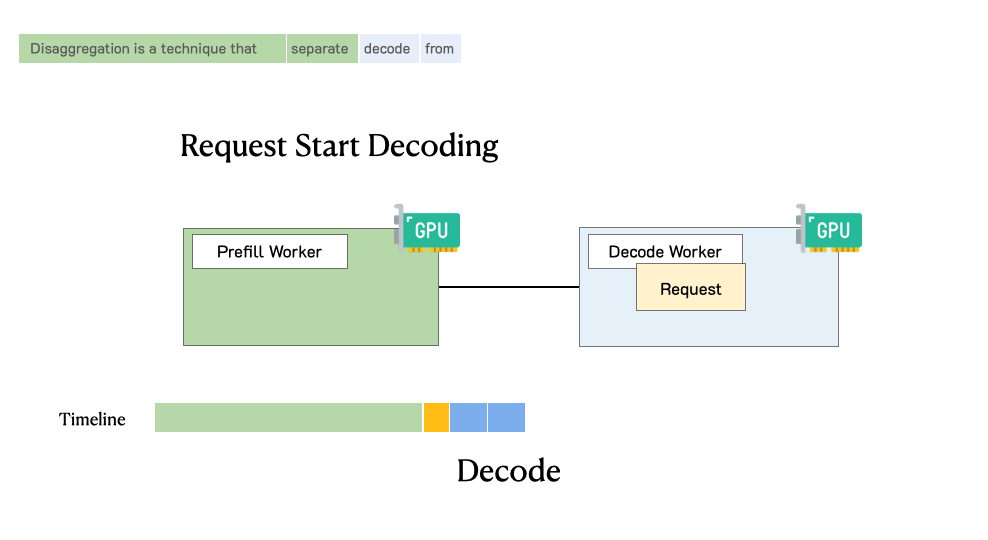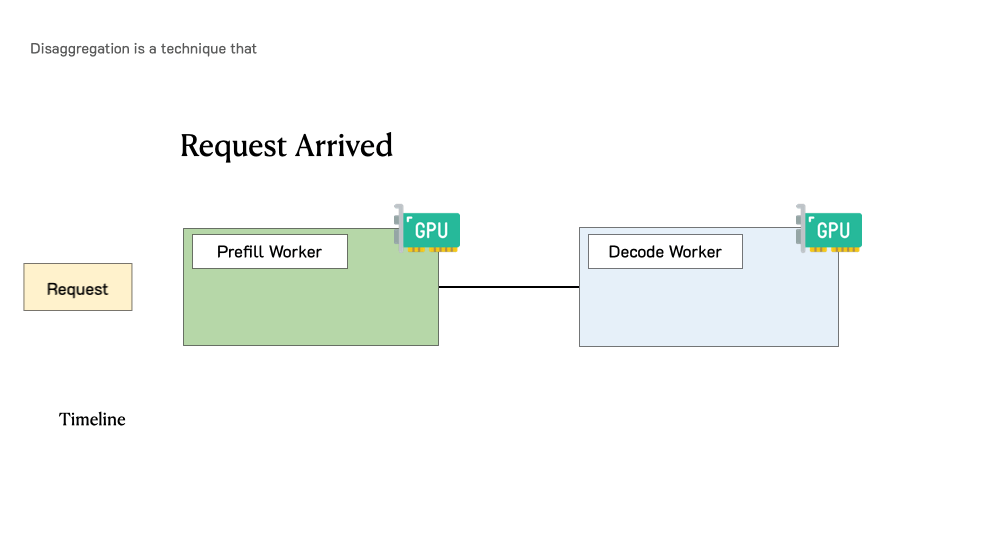
TL;DR: LLM apps today have diverse latency requirements. For example, a chatbot may require a fast initial response (e.g., under 0.2 seconds) but moderate speed in decoding which only needs to match human reading speed, whereas code completion requires a fast end-to-end generation time for real-time code suggestions. In this blog post, we show existing serving systems that optimize throughput are not optimal under latency criteria. We advocate using goodput, the number of completed requests p...| hao-ai-lab.github.io
