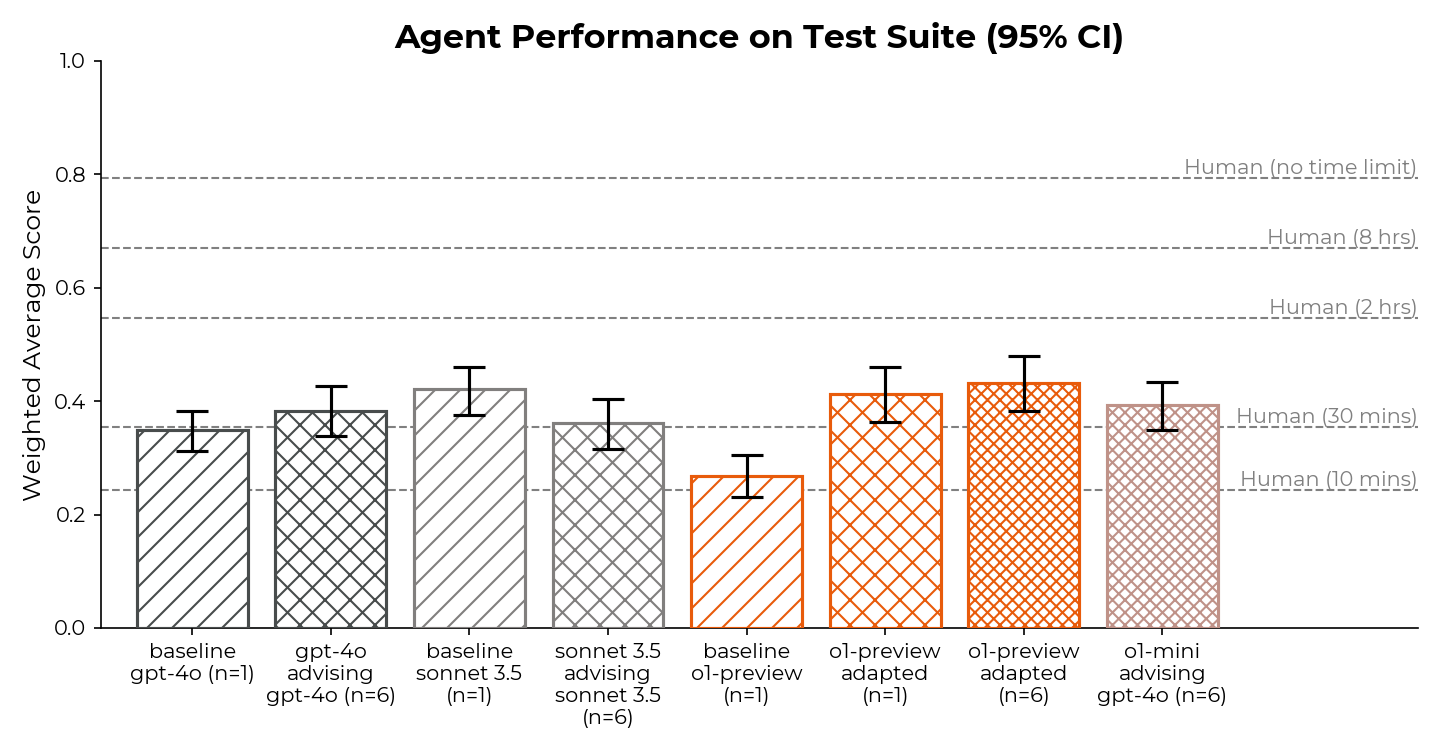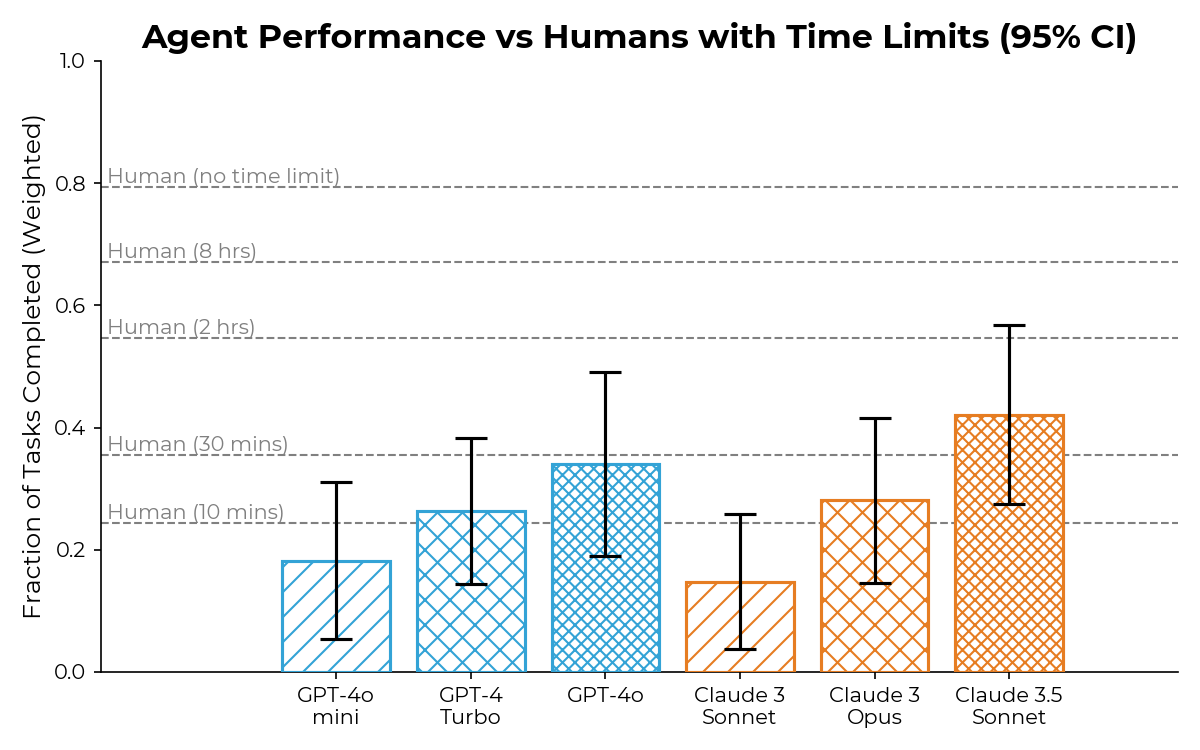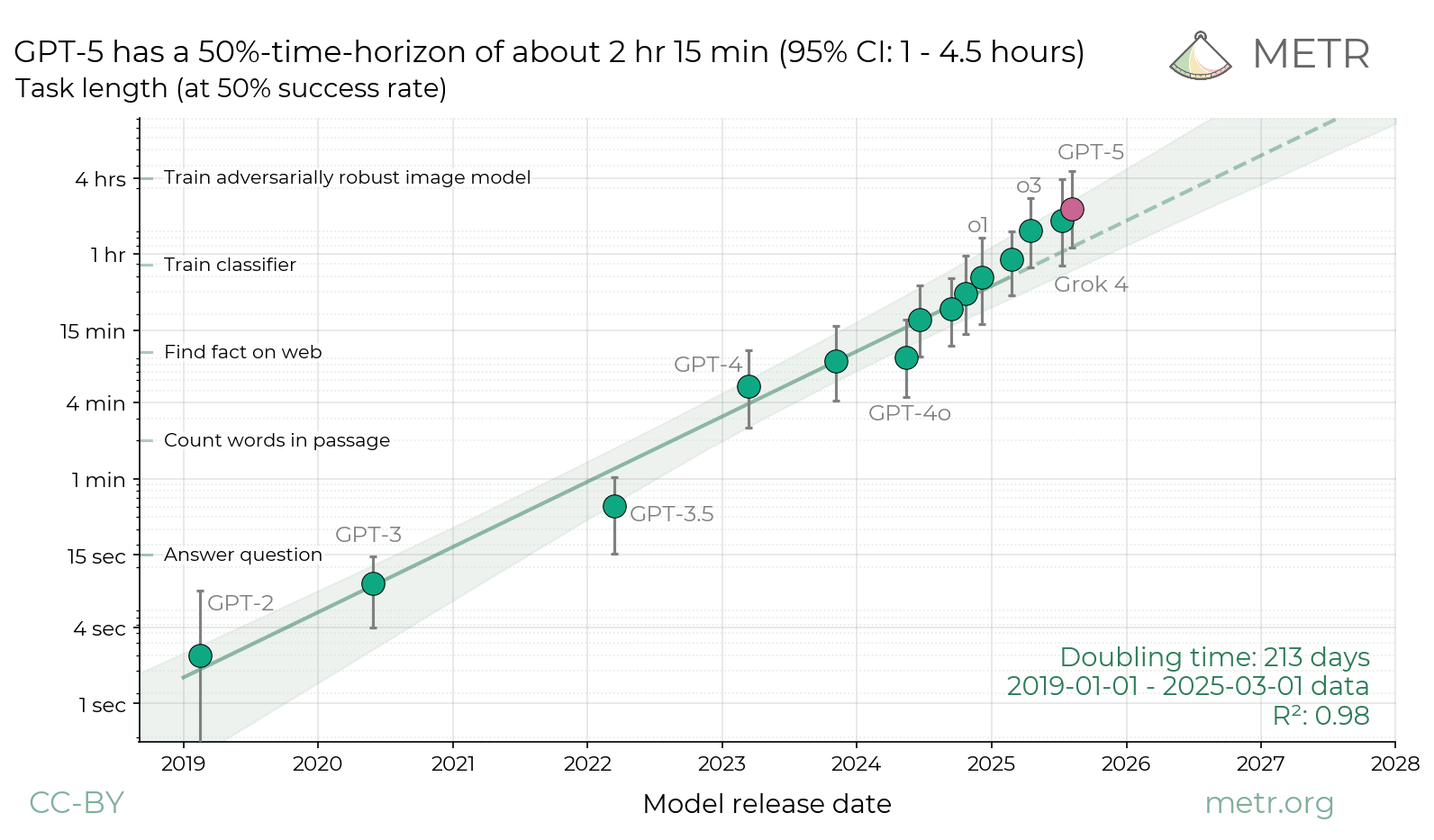
Details about METR’s evaluation of OpenAI GPT-5 | METR’s Autonomy Evaluation Resources
We evaluate whether GPT-5 poses significant catastrophic risks via AI self-improvement, rogue replication, or sabotage of AI labs. We conclude that this seems unlikely. However, capability trends continue rapidly, and models display increasing eval awareness.| METR’s Autonomy Evaluation Resources