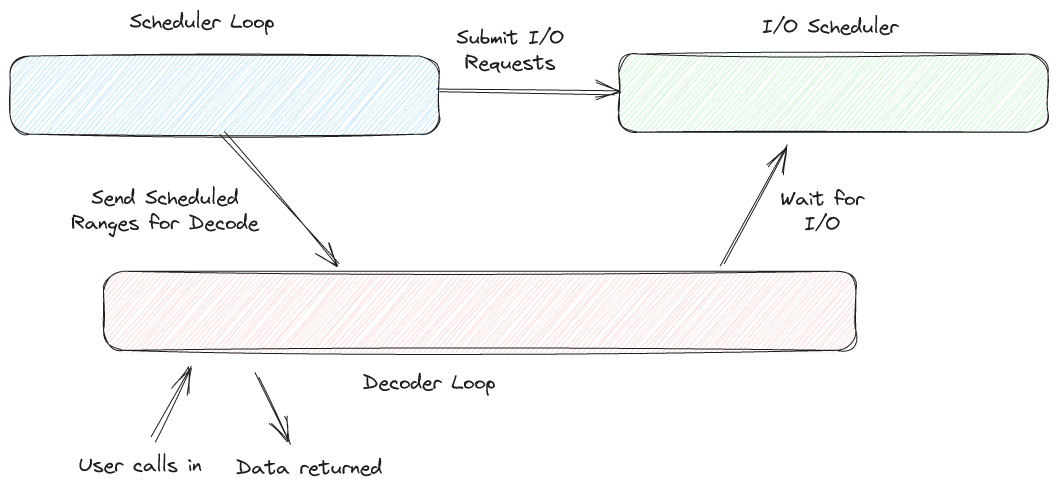
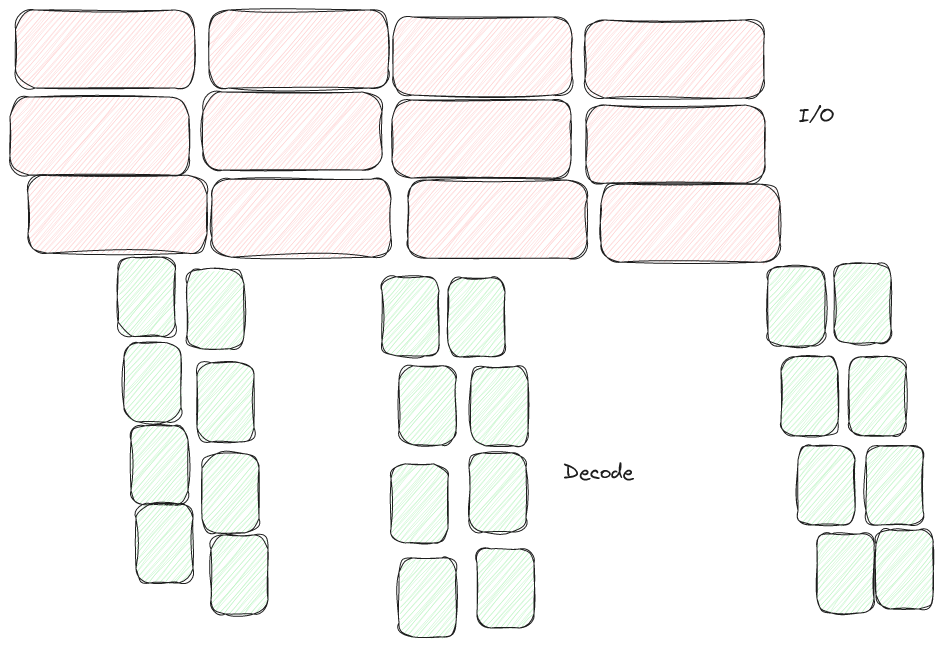
The API used to read files has evolved over time, from simple "full table" reads to batch reads and eventually to iterative "record batch readers". These more sophisticated APIs add additional power and flexibility. Lance takes this a step further to return a "stream of read tasks". This originates from| LanceDB Blog
📄🌐The Lance Research Paper That's right, we finally published the Lance Research Paper on arXiv. Check out Lance: Efficient Random Access in Columnar Storage through Adaptive Structural Encodings. Read on arXiv 🔍Columnar File Readers in Depth: Compression and Transparency A new drop in the Columnar| LanceDB Blog
This is a follow up to the following report that deals with improving retrievers by training and fine-tuning reranker models A Practical Guide to Training Custom Rerankers A report on reranking, training, & fine-tuning rerankers for retrieval This report offers practical insights for improving a retriever by reranking results. We&| LanceDB Blog
As Continue offers user-controlled IDE extensions, most of the codebase is written in Typescript, and the data is stored locally in the ~/.continue folder. The tooling choices are made such that there are no separate processes required to handle database operations. Continue's codebase retrieval features are powered by| LanceDB Blog
A report on reranking, training, & fine-tuning rerankers for retrieval --- This report offers practical insights for improving a retriever by reranking results. We'll tackle the important questions, like: When should you implement a reranker? Should you opt for a pre-trained solution, fine-tune an existing model, or build one| LanceDB Blog
As the scale of data continues to grow, open-source table formats have become essential for efficient data lake management. Apache Iceberg has emerged as a leader in this space, while new formats like Lance are introducing optimizations for specific workloads. In this post, we’ll explore how Iceberg and| LanceDB Blog
☁️ LanceDB Cloud Public Beta The wait is over! LanceDB Cloud is now in Public Beta! No more wait list; just sign-up, get an API key, and start building AI with LanceDB Cloud - Serverless Retrieval for Multimodal AI! Try LanceDB Cloud (Public Beta) Now --- Good Reads 👀Lance| LanceDB Blog
AnythingLLM chose LanceDB as their vector database backbone to create a frictionless experience for developers and end-users alike. By leveraging LanceDB's serverless, setup-free architecture, the AnythingLLM team slashed engineering time previously spent on troubleshooting infrastructure issues and redirected it toward building innovative features. The result? An application that| LanceDB Blog
Almost a year ago I announced we were going to be embarking on a journey to build a new 2.0 version of our file format. Several months later, we released a beta, and last fall it became our default file format. Overall, I've been super pleased with| LanceDB Blog
💡 This is a case study contributed by the Second Dinner team and the LanceDB team. Second Dinner teamed up with LanceDB Cloud’s serverless architecture to turbocharge their game development workflow. Overnight, system designers went from waiting months to spinning up prototypes in hours, slashing endless cross-team coordination.| LanceDB Blog
💡 This is a community post by Mahesh Deshwal Group Relative Policy Optimization is the series of RL techniques for LLMs to guide them to specific goals. The process of creating a smart model these days is something like this: Pre Training a model on a HUGE corpus to get| LanceDB Blog
🔥 New Blog: Designing a Table Format for ML Workloads Zero-copy schema evolution, indices for everything, and parallelized operations - all designed for modern ML. We explain the why & how behind the Lance table format in our latest engineering blog. LanceDB Enterprise Product News 🔥 Multivector Search is now live: Documents can| LanceDB Blog
All the LanceDB news fit to print. Subscribe for new features, technical deep dives into multimodal data storage, and the newest examples built with LanceDB| LanceDB Blog
We've been working on readers / writers for our recently announced Lance v2 file format and are posting in-depth articles about writing a high performance file reader. In the first article I talked about how we obtain parallelism without row groups. Today, I want to explain how, and why, we separate| LanceDB Blog
Why a new format? Lance was invented because readers and writers for existing column formats did not handle AI/ML workloads efficiently. Lance v1 solved some of these problems but still struggles in a number of cases. At the same time, others (btrblocks, procella, vortex) have found similar issues with| LanceDB Blog
🎤 Catch Us on Stage This June! We’re thrilled to be speaking at several top-tier events this month — alongside our customers — sharing real-world insights from scaling enterprise AI systems in production. If you’re attending the AI Engineering World Fair (June 3–5), Data| LanceDB Blog
Repetition and definition levels are a method of converting structural arrays into a set of buffers. The approach was made popular in Parquet and is one of the key ways Parquet, ORC, and Arrow differ. In this blog I will explain how they work by contrasting them with validity & offsets| LanceDB Blog
Record shredding is a classic method used to transpose rows of potentially nested data into a flattened tree of buffers that can be written to the file. A similar technique, cascaded encoding, has recently emerged, that converts those arrays into a flattened tree of compressed buffers. In this article we| LanceDB Blog
Recently, I shared our plans for a new file format, Lance v2. As I'm creating a file reader for this new format I plan to create a series of posts talking about the design, challenges and limitations in many existing file readers, and how we plan to overcome these. Much| LanceDB Blog
Streaming data applications can be tricky. When you can read data faster than you can process the data then bad things tend to happen. The most common scenario is you run out of memory and your process crashes. When the process doesn't crash, it often breaks performance (e.g. swapping| LanceDB Blog
Conventional wisdom states that compression and random access do not go well together. However, there are many ways you can compress data, and some of them support random access better than others. Figuring out which compression we can use, and when, and why, has been an interesting challenge. As we've| LanceDB Blog
💡This is a community post by Mahesh Deshwal Comprehensive Evaluation Metrics for RAG Applications Using LanceDB In the world of Retrieval-Augmented Generation (RAG) applications, evaluating the performance and reliability of models is critical. Evaluation metrics play a crucial role in assessing and enhancing the performance of models and their it| LanceDB Blog
To inaugurate the new year, we proudly unveiled the first ⚔️Lancelot Round Table in January, celebrating the founding knights who have been instrumental in shaping the future of AI infrastructure since LanceDB's inception. These Lancelot pioneers are driving innovation by implementing and collaborating with lance and lancedb across their organizations,| LanceDB Blog
Agent? What's that? In the current world where everything is running with and for AI, retrieval-augmented generation (RAG) systems have become essential for handling simple queries and generating contextually relevant responses. However, as ever evolving human we are, the need for complex, autonomous problem-solving has emerged. Here I present, behold| LanceDB Blog
💡This is a community blog by Vipul Maheshwari In 2024, I did spend significant amount of time playing with RAG and Vector Database. Typically, LanceDB was at the core and it was one amazing hell of a ride. As the year is ending, I tried to make a simple restaurant| LanceDB Blog
My name is Jun Wang, I am a master's student at Clark University, this fall semester I was very fortunate to have the opportunity working at LanceDB as a software engineer intern. I worked on Lance, a modern columnar data format for ML and LLMs. Lance is set to be| LanceDB Blog
💡This is a community post by Prashant Kumar Computer vision turns visual data into valuable insights, making it exciting. Now, with Large Language Models (LLMs), combining vision and language opens up even more possibilities. Before we explore how LLMs are powering computer vision, let’s first take a quick look| LanceDB Blog
💡This is a community post by Sankalp Shubham The project will look something like this: Introduction If you have used the Cursor code editor's @codebase feature, you're probably familiar with how helpful it can be for understanding codebases. Whether you need to find relevant files, trace execution flows, or understand| LanceDB Blog
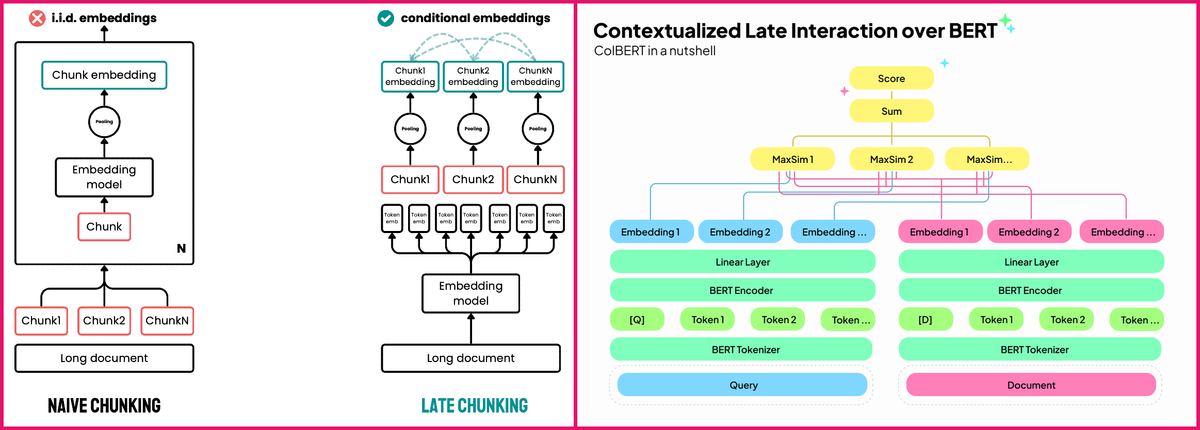
💡This is a community blog by Mahesh Deshwal Improved Contextual Retrieval over large Documents for RAG applications The pronoun is the King (or Queen), and so is the Context. I hope the previous line gave you the gist that, given the right context, you can use your brain or LLM| LanceDB Blog
Community contributions 💡Dspy now works with LanceDB. LanceDB helps DSPy by quickly storing and retrieving information. This lets DSPy find relevant details faster, making prompts more accurate. This integration ensures that prompts meet user needs, leading to a better writing experience.💡Prefect released ControlFlow 0.10, a Python framework for| LanceDB Blog