
Stumbling into AI: Part 5—Agents
Turns out this isn’t so straightforward a question to answer.| Stumbling into AI: Part 5—Agents
A presentation about effective blog writing for developers, covering why to blog, what to write about, and how to structure your content. This presentation covers: Why developers should blog What topics to write about How to structure and write effective content Tools and platforms for technical writing Using AI in the writing process Tip Click in the presentation iframe and then press f to view it full screen. 🎧 Recording No video, but you can listen to the recording here (or download it ...| rmoff's random ramblings
Turns out this isn’t so straightforward a question to answer.| Stumbling into AI: Part 5—Agents

Sneaking it in just before the end of the month!| Interesting links - September 2025
Having looked at MCP, Models, and RAG, I realised that I’ve been mentally skirting around something that I don’t really understand, so I’m going to expose myself to some ridicule here and try to understand better: what’s the difference between AI and ML? Aren’t they just the same? What’s the difference between AI and ML? OK we’re doing this are we?I thought AI was just ✨magic✨?And ML was the thing that got data scientists mad stacks ten years ago before everyone realised you...| rmoff's random ramblings
A short series of notes for myself as I learn more about the AI ecosystem as of September 2025.The driver for all this is understanding more about Apache Flink’s Flink Agents project, and Confluent’s Streaming Agents. Having poked around MCP and Models, next up is RAG. RAG has been one of the buzzwords of the last couple of years, with any vendor worth its salt finding a way to crowbar it into their product. I’d been sufficiently put off it by the hype to steer away from actually unders...| rmoff's random ramblings
A short series of notes for myself as I learn more about the AI ecosystem as of September 2025.The driver for all this is understanding more about Apache Flink’s Flink Agents project, and Confluent’s Streaming Agents. Having poked around MCP and got a broad idea of what it is, I want to next look at Models. What used to be as simple as "I used AI" actually boils down into several discrete areas, particularly when one starts looking at using LLMs beyond writing a rap about Apache Kafka in ...| rmoff's random ramblings

A short series of notes for myself as I learn more about the AI ecosystem as of September 2025.| Stumbling into AI: Part 1—MCP
Not got time for all this? I’ve marked 🔥 for my top reads of the month :) Tip You can find previous editions of Interesting Linkshere. Data Engineering 🔥 Ben Rogojan (a.k.a. SeattleDataGuy) has a great list of 5 Things in Data Engineering That Still Hold True After 10 Years (guess what: data modelling matters, if you start with crap data you’ll end with crap data, and so on…). Veronika Durgin shares some good tips for building resilient data pipelines. Some good pointers for why y...| rmoff's random ramblings

How many topics do you have? 🔗 | Kafka to Iceberg - Exploring the Options
Aug 21, 2025| rmoff.net
This is a quick blog post to remind me how to connect Apache Flink to a Kafka topic on Confluent Cloud. You may wonder why you’d want to do this, given that Confluent Cloud for Apache Flink is a much easier way to run Flink SQL. But, for whatever reason, you’re here and you want to understand the necessary incantations to get this connectivity to work. There are two versions of this connectivity - with, and without, using the Schema Registry for Avro. MVP: Just connect to a Kafka topic; n...| rmoff's random ramblings

Not got time for all this? I’ve marked 🔥 for my top reads of the month :)| Interesting links - July 2025

ℹ️ For more in-depth notes on this subject, check out Alex Merced’s article.| Keeping your Data Lakehouse in Order: Table Maintenance in Apache Iceberg

Kafka Connect is a framework for data integration, and is part of Apache Kafka.| Writing to Apache Iceberg on S3 using Kafka Connect with Glue catalog

Not got time for all this? I’ve marked 🔥 for my top reads of the month :)| Interesting links - June 2025

I’m using Flink 1.20, since as of the time of writing (2025-06-24) the Iceberg connector doesn’t yet support Flink 2.0 (it’s due with Iceberg 1.10.0).| Writing to Apache Iceberg on S3 using Flink SQL with Glue catalog

After a week’s holiday ("vacation", for y’all in the US) without a glance at anything work-related, what joy to return and find that the DuckDB folk have been busy, not only with the recent 1.3.0 DuckDB release, but also a brand new project called DuckLake.| Digging into Ducklake

Not got time for all this? I’ve marked 🔥 for my top reads of the month :)| Interesting links - May 2025

So. Many. Interesting. Links. Not got time for all this? I’ve marked 🔥 for my top reads of the month :)| Interesting links - April 2025
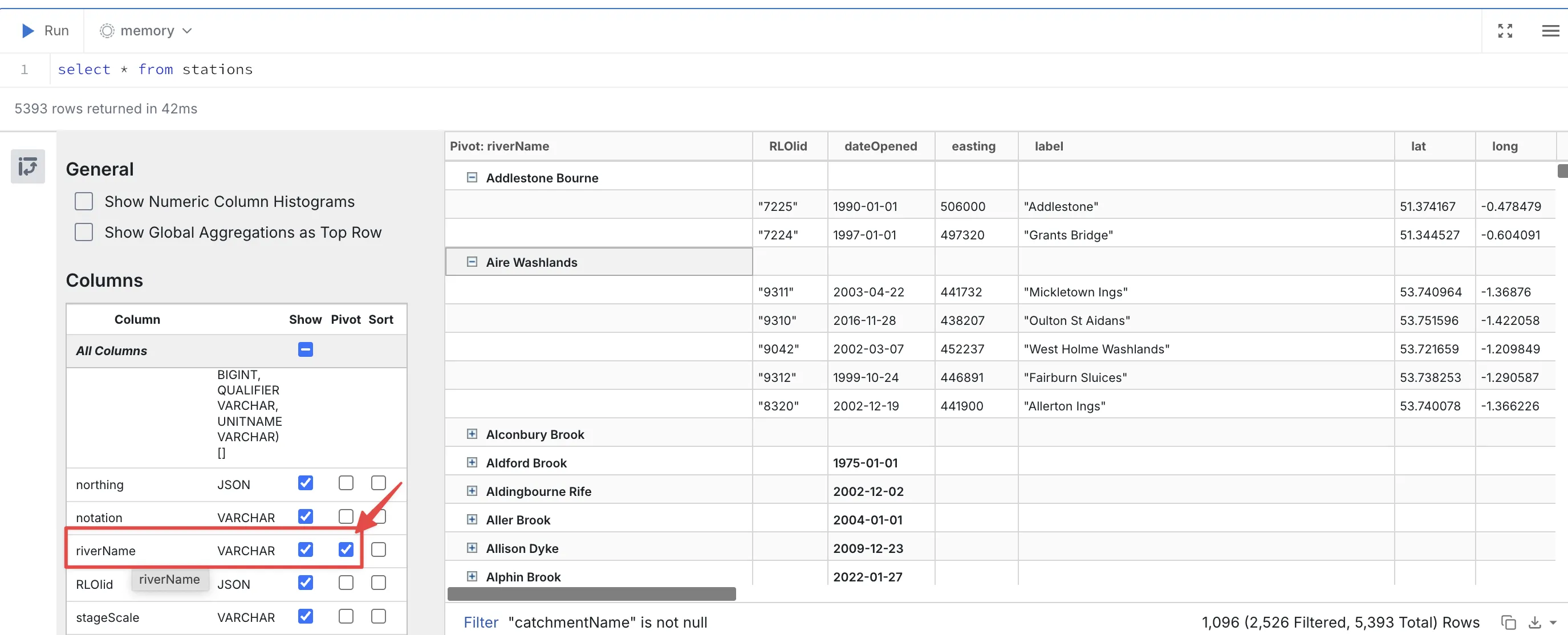
I wrote a couple of weeks ago about using DuckDB and Rill Data to explore a new data source that I’m working with.| Kicking the tyres on the new DuckDB UI

Let’s imagine we’ve got a source of data with a nested array of multiple values.| How to explode nested arrays with Flink SQL

I was exploring some new data, joining across multiple tables, and doing a simple SELECT * as I’d not worked out yet which columns I actually wanted.| DuckDB tricks - renaming fields in a SELECT * across tables

Here’s a bunch of interesting links and articles about data that I’ve come across recently.| Interesting links - February 2025

The idea here is that you use Asciidoc’s inline pass macro to embed HTML comments (<!-- remember these? -→) in the generated HTML, which then passes the commands to Vale like vale off:| Disabling Vale Linting Selectively in Asciidoc

At Current 24 a few of us will be going for an early run (or walk) on Tuesday morning. Everyone is very welcome!| Current 2024 - 5k Fun Run (or Walk)

