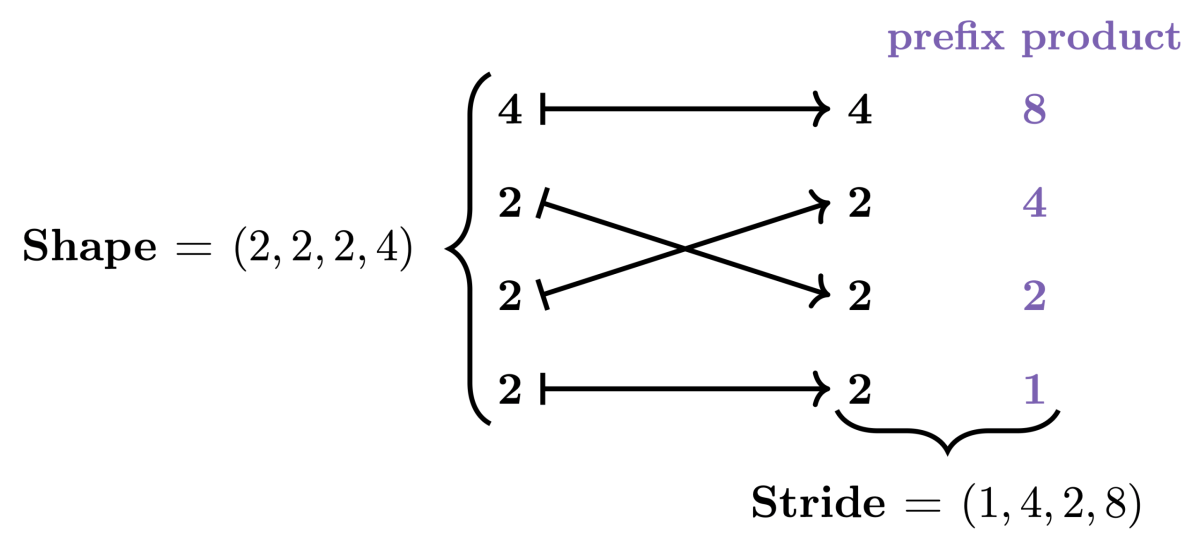
In GPU programming, performance depends critically on how data is stored and accessed in memory. While the data we care about is typically multi-dimensional, the GPU’s memory is fundamentally one-d…| Colfax Research
The goal of this tutorial is to elicit the concepts and techniques involving memory copy when programming on NVIDIA® GPUs using CUTLASS and its core backend library CuTe. Specifically, we will stud…| Colfax Research
In this blog post presented on the NVIDIA technical blog, we give a concise introduction to the CUTLASS 3.x APIs, focusing on the collective, kernel, and device layers and the functionality of the …| Colfax Research
Welcome to part 3 of our series investigating GEMM on the NVIDIA Blackwell architecture. In parts 1 and 2, we looked at the Tensory Memory and 2 SM capabilities of the new Blackwell Tensor Core UMMA instructions and how to work with them in CUTLASS. In this part, we introduce low-precision computation and then discuss […]| Colfax Research
Welcome to part two of our series investigating GEMM on the NVIDIA Blackwell architecture. In part 1, we introduced some key new features available on NVIDIA Blackwell GPUs, including Tensor Memory, and went over how to write a simple CUTLASS GEMM kernel that uses the new UMMA instructions (tcgen05.mma) to target the Blackwell Tensor Cores. […]| Colfax Research
The NVIDIA Blackwell architecture introduces some new features that significantly change the shape of a GEMM kernel. In this series of posts, we explore the new features available on Blackwell and examine how to write CUTLASS GEMM kernels that utilize these new features by drawing on the CuTe tutorial examples. The goal of this series […]| Colfax Research
DeepSeek has shocked the world with the release of their reasoning model DeepSeek-R1. Similar to OpenAI’s o1 and Google Gemini’s Flash Thinking, the R1 model aims to improve the quality of its replies by generating a “chain of thought” before responding to a prompt. The excitement around R1 stems from it achieving parity with o1 […]| Colfax Research
Welcome to Part 3 of our tutorial series on GEMM (GEneral Matrix Multiplication). In Parts 1 and 2, we discussed GEMM at length from the perspective of a single threadblock, introducing the WGMMA matmul primitive, pipelining, and warp specialization. In this part, we will examine GEMM from the perspective of the entire grid. At this […]| Colfax Research
In this blog post presented on the Character.AI research blog, we explain two techniques that are important for using FlashAttention-3 for inference: in-kernel pre-processing of tensors via warp specialization and query head packing for MQA/GQA.| Colfax Research
In this GPU Mode lecture, Jay Shah presents his joint work on FlashAttention-3 and how to implement the main compute loop in the algorithm using CUTLASS. The code discussed in this lecture can be found at this commit in the FlashAttention-3 codebase. Note: Slides adapted from a talk given by Tri Dao.| Colfax Research