How to Bypass CreepJS and Spoof Browser Fingerprinting | ScrapingBee
Learn how to bypass CreepJS and spoof browser fingerprinting using Playwright, Selenium, Puppeteer, and Camoufox to evade detection in web scraping.| www.scrapingbee.com
Learn how to bypass CreepJS and spoof browser fingerprinting using Playwright, Selenium, Puppeteer, and Camoufox to evade detection in web scraping.| www.scrapingbee.com
The Scrapy vs Selenium debate has been ongoing in the web scraping community for years. Both tools have carved out their own territories in the world of data extraction and web automation, but choosing between them can feel like picking between a race car and a Swiss Army knife, they’re both excellent, just for different reasons. If you’ve ever found yourself staring at a website wondering how to extract its data efficiently, you’ve probably encountered these two powerhouses. Scrapy sta...| ScrapingBee – The Best Web Scraping API
Mastering the Python curl request is one of the fastest ways to turn API docs or browser network calls into working code. Instead of rewriting everything by hand, you can drop curl straight into Python, or translate it into Requests or PycURL for cleaner, long-term projects. In this guide, we'll show practical ways to run curl in Python, when to use each method (subprocess, PycURL, Requests), and how ScrapingBee improves reliability with proxies and optional JavaScript rendering, so you can s...| ScrapingBee – The Best Web Scraping API
If you've used Python Selenium for web scraping, you're familiar with its ability to extract data from websites. However, the default webdriver (ChromeDriver) often struggles to bypass anti-bot mechanisms. As a solution, you can use undetected_chromedriver to bypass some of today's most sophisticated anti-bot systems, including those from Cloudflare and Akamai. However, it's important to note that undetected_chromedriver has limitations against advanced anti-bot systems. This is where Nodrive...| ScrapingBee – The Best Web Scraping API
Ever found yourself staring at a website, desperately wanting to extract all that data, but wondering whether you should build a scraper or get an API? The web scraping vs API debate is one of the most common questions in data extraction. Honestly, it’s a fair question that deserves a proper answer. Both approaches have their place in the modern data landscape, but understanding the difference between web scraping and API methods can save you time, money, and countless headaches. In this ar...| ScrapingBee – The Best Web Scraping API
Ever stared at a data-rich website and wondered how to pull it out cleanly and fast? To acomplish this mission, you need to pick the best language for web scraping. But the process can feel a bit confusing. Python’s hype, JavaScript’s ubiquity, and a dozen others languages makes it hard to pick the right one. After years building scrapers, I’ve watched teams burn time by matching the wrong tool to the job. Today’s web is trickier: JavaScript-heavy UIs, dynamic rendering, rate limits, ...| ScrapingBee – The Best Web Scraping API
When scraping websites protected by Cloudflare, encountering Error 1005 — "Access Denied, You Have Been Banned" — is a common challenge. This error signifies that your IP address has been blocked, usually due to Cloudflare's security mechanisms that aim to prevent scraping and malicious activities. However, there are various techniques you can use to bypass this error and continue your scraping operations. In this guide, we'll focus on specific strategies and tools to bypass Cloudflare Er...| ScrapingBee – The Best Web Scraping API
The real estate market moves fast. Property listings appear and disappear within hours, prices fluctuate based on market conditions, and tracking availability across multiple platforms manually becomes an impossible task. For developers, investors, and real estate agents who need to stay ahead of market trends, building a real estate web scraper offers the solution to automate data collection from sites like Redfin, Idealista, or Apartments.com. Instead of spending hours on manual data entry,...| ScrapingBee – The Best Web Scraping API
If you've used Python Selenium for web scraping, you're familiar with its ability to extract data from websites. However, the default webdriver (ChromeDriver) often struggles to bypass the anti-bot mechanisms websites use to detect and block scrapers. With undetected_chromedriver, you can bypass some of today's most sophisticated anti-bot mechanisms, including those from Cloudflare, Akamai, and DataDome. In this blog post, we’ll guide you on how to make your Selenium web scraper less detect...| ScrapingBee – The Best Web Scraping API
Learning how to scrape images from website sources is a skill that can unlock various benefits. Whether you’re extracting product photos for competitive analysis, building datasets or gathering visual content for machine learning projects you need to know how to scrape. In this article, I'll walk you through the process of building website image scraper. But don't worry, you won't have code everything from scratch. ScrapingBee’s web scraping API allows automating content collection with m...| ScrapingBee – The Best Web Scraping API
Top web scraping challenges have evolved dramatically from the simple days of parsing static HTML. I’ve been building scrapers for years, and let me tell you – even simple tasks have turned into a complex chess match between developers and websites. From sophisticated CAPTCHAs, to JavaScript, the obstacles continue to multiply. In this article, I’ll break down the major hurdles you’ll face when scraping data in 2025 and show you how ScrapingBee can help you jump over these barriers wi...| ScrapingBee – The Best Web Scraping API
Looking for the best SERP API in 2025? You've come to the right place. In my experience working with various search engine data projects, choosing the right API can make or break your entire operation. Some search scraping APIs can be frustrating, as they often yield inconsistent data. Others extract data so smoothly you’ll wonder how they make web scraping so easy. The search engine API market has evolved significantly in 2025, with new players entering the field and established providers ...| ScrapingBee – The Best Web Scraping API
The best web scraping services in USA had made manual data collection obsolete. Today, web scapers have become essential infrastructure for modern businesses, transforming what used to be weeks of into automated processes that run with a few lines of code. However, the scraping landscape has evolved dramatically and what worked in 2020 barely scratches the surface today. Modern websites throw everything at automated data collectors: sophisticated JavaScript rendering, complex bot detection sy...| ScrapingBee – The Best Web Scraping API
If you've ever tried to send requests through a proxy in Node.js, chances are you've searched for how to set up an Axios proxy. Whether you're scraping the web, checking geo-restricted content, or just hiding your real IP, proxies are a common part of the toolkit. This guide walks through the essentials of using Axios with proxies: setting up a basic proxy, adding username/password authentication, rotating proxies to avoid bans, working with SOCKS5, plus a few fixes for common errors. We'll a...| ScrapingBee – The Best Web Scraping API
Web scraping raises a lot of questions, but “is web scraping legal” is the one I hear the most. The legality of web scraping depends on three critical factors: what data you’re collecting, how you’re collecting it, and where you’re operating. Think of it like driving a car, the act itself isn’t illegal, but speeding, running red lights, or driving without a license can land you in serious trouble. This guide breaks down the complex world of web scraping legality across different j...| ScrapingBee – The Best Web Scraping API
Search engine scraping has become an essential method for many businesses, digital marketers, and researchers to gather information. It is an excellent data extraction method when you need to analyze a large number of competitor websites. With web scraping, you can extract information on market trends and make informed decisions on pricing strategies using the data extracted from SERPs. In this tutorial, I’ll show you how to perform search engine scraping safely and efficiently using Scrapi...| ScrapingBee – The Best Web Scraping API
Want to learn how to scrape Baidu? As China’s largest search engine, Baidu is an attractive target for web scraping because it is similar to Google in function but tailored for local regulations. For those wanting to tap into China's digital ecosystem, it is the best source of public data that displays relevant, location-based search trends, plus everything you need to conduct market research. This guide will teach you how to extract information from Baidu HTML code with the most beginner-f...| ScrapingBee – The Best Web Scraping API
Python web scraping stock price techniques have become essential for traders and financial analysts who need near real-time market data analysis without paying thousands for premium API access. Becoming a pro at scraping stock market data allows you to build a personal investment dashboard for real time stock data monitoring. It also helps you to extract data for market research, or developing a trading algorithm. Whatever you decide to use all the data for, having direct access to stock pric...| ScrapingBee – The Best Web Scraping API
Booking.com is one of the biggest travel platforms, and a go-to choice for millions of users planning their trips and vacations. By accessing the platform using automated tools, we can collect hotel data, including names, ratings, prices, and locations, for research or comparison purposes. However, the platform’s strict anti-bot systems make direct extractions nearly impossible. Fortunately, our API and implementation of Python tools eliminate these challenges by providing automatic JavaScr...| ScrapingBee – The Best Web Scraping API
Please brace yourselves, we'll be going deep into the world of Unix command lines and shells today, as we are finding out more about how to use the Bash for scraping websites. Let's fasten our seatbelts and jump right in 🏁 Why Scraping With Bash? If you happened to have already read a few of our other articles (e.g. web scraping in Python or using Chrome from Java), you'll be probably already familiar with the level of convenience those high-level languages provide when it comes to crawlin...| ScrapingBee – The Best Web Scraping API
Introduction CAPTCHA - Completely Automated Public Turing test to tell Computers and Humans Apart! All these little tasks and riddles you need to solve before a site lets you proceed to the actual content. 💡 Want to skip ahead and try to avoid CAPTCHAs? At ScrapingBee, it is our goal to provide you with the right tools to avoid triggering CAPTCHAs in the first place. Our web scraping API has been carefully tuned so that your requests are unlikely to get stopped by a CAPTCHA, give it a go.| ScrapingBee – The Best Web Scraping API
Artificial Intelligence (AI) is rapidly becoming a part of everyday life, and with it, the demand for training custom models has increased. Many people these days would like to train their very own... AI, not dragon, duh! One crucial step in training any language model (LLM) is gathering a significant amount of text data. In this article, I'll show you how to collect text data from all pages of a website using web scraping techniques. We'll build a custom Python script to automate this proces...| ScrapingBee – The Best Web Scraping API
Collecting data from websites and organizing it into a structured format like Excel can be super handy. Maybe you're building reports, doing research, or just want a neat spreadsheet with all the info you need. But copying and pasting manually? That's a time sink no one enjoys. In this guide, we'll discuss a few ways to scrape data from websites and save it directly into Excel. Together we'll talk about methods for both non-techies and devs, using everything from built-in Excel tools to codin...| ScrapingBee – The Best Web Scraping API
Artifical intelligence is everywhere in tech these days, and it's wild how it's become a go-to tool, for example, in stuff like web scraping. Let's dive into how Scrapegraph AI can totally simplify your scraping game. Just tell it what you need in simple English, and watch it work its magic. I'm going to show you how to get Scrapegraph AI up and running, how to set up a language model, how to process JSON, scrape websites, use different AI models, and even turning your data into audio. Sounds...| ScrapingBee – The Best Web Scraping API

We help you get better at web-scraping: detailed tutorials, case studies and writings by industry experts.| www.scrapingbee.com
In today's article we are going to take a closer look at CSS selectors, where they originated from, and how they can help you in extracting data when scraping the web. ℹ️ If you already read the article "Practical XPath for Web Scraping", you'll probably recognize more than just a few similarities, and that is because XPath expressions and CSS selectors actually are quite similar in the way they are being used in data extraction.| ScrapingBee – The Best Web Scraping API
XPath is a technology that uses path expressions to select nodes or node-sets in an XML document (or in our case an HTML document). Even if XPath is not a programming language in itself, it allows you to write an expression which can directly point to a specific HTML element, or even tag attribute, without the need to manually iterate over any element lists. It looks like the perfect tool for web scraping right? At ScrapingBee we love XPath! ❤️| ScrapingBee – The Best Web Scraping API
chromedp is a Go library for interacting with a headless Chrome or Chromium browser. The chromedp package provides an API that makes controlling Chrome and Chromium browsers simple and expressive, allowing you to automate interactions with websites such as navigating to pages, filling out forms, clicking elements, and extracting data. It's useful for simplifying web scraping as well as testing, performance monitoring, and developing browser extensions. This article provides an overview of chr...| ScrapingBee – The Best Web Scraping API
Web scraping is a powerful tool for gathering data from websites, and Playwright is one of the best tools out there to get the job done. In this tutorial, I'll walk you through how to scrape with Playwright for Python. We'll start with the basics and gradually move to more advanced techniques, ensuring you have a solid grasp of the entire process. Whether you're new to web scraping or looking to refine your skills, this guide will help you use Playwright for Python effectively to extract data...| ScrapingBee – The Best Web Scraping API
Web scraping uses automated software tools or scripts to extract and parse data from websites into structured formats for storage or processing. Many data-driven initiatives—including business intelligence, sentiment analysis, and predictive analytics—rely on web scraping as a method for gathering information. However, some websites have implemented anti-scraping measures as a precaution against the misuse of content and breaches of privacy. One such measure is IP blocking, where IPs with...| ScrapingBee – The Best Web Scraping API
Your web page may sometimes need to use information from other web pages that do not provide an API. For instance, you may need to fetch stock price information from a web page in real time and display it in a widget of your web page. However, some of the stock price aggregation websites don’t provide APIs. In such cases, you need to retrieve the source HTML of the web page and manually find the information you need. This process of retrieving and manually parsing HTML to find specific info...| ScrapingBee – The Best Web Scraping API
Web crawling is often confused with web scraping, which is simply extracting specific data from web pages. A web crawler is an automated program that helps you find and catalog relevant data sources. Typically, a crawler first makes requests to a list of known web addresses and, from their content, identifies other relevant links. It adds these new URLs to a queue, iteratively takes them out, and repeats the process until the queue is empty. The crawler stores the extracted data—like web pa...| ScrapingBee – The Best Web Scraping API
In this tutorial, you will learn how to learn how to scrape websites using Visual Basic. Don't worry—you won't be using any actual scrapers or metal tools. You'll just be using some good old-fashioned code. But you might be surprised at just how messy code can get when you're dealing with web scraping! You will start by scraping a static HTML page with an HTTP client library and parsing the result with an HTML parsing library. Then, you will move on to scraping dynamic websites using Puppet...| ScrapingBee – The Best Web Scraping API
For any project that pulls content from the web in C# and parses it to a usable format, you will most likely find the HTML Agility Pack. The Agility Pack is standard for parsing HTML content in C#, because it has several methods and properties that conveniently work with the DOM. Instead of writing your own parsing engine, the HTML Agility Pack has everything you need to find specific DOM elements, traverse through child and parent nodes, and retrieve text and properties (e.g., HREF links) wi...| ScrapingBee – The Best Web Scraping API
Are you a data analyst thirsty for social media insights and trends? A Python developer looking for a practical social media scraping project? Maybe you're a social media manager tracking metrics or a content creator wanting to download and analyze your TikTok data? If any of these describe you, you're in the right place! TikTok, the social media juggernaut, has taken the world by storm. TikTok's global success is reflected in its numbers:| ScrapingBee – The Best Web Scraping API
The value of unstructured data has never been more prominent than with the recent breakthrough of large language models such as ChatGPT and Google Bard. Your organization can also capitalize on this success by building your own expert models. And what better way to collect droves of unstructured data than by scraping it? This article outlines how to scrape the web using R and a package known as RSelenium. RSelenium is a binding for the Selenium WebDriver, a popular web scraping tool with unma...| ScrapingBee – The Best Web Scraping API
The introduction of the Fetch API changed how Javascript developers make HTTP calls. This means that developers no longer have to download third-party packages just to make an HTTP request. While that is great news for frontend developers, as fetch can only be used in the browser, backend developers still had to rely on different third-party packages. Until node-fetch came along, which aimed to provide the same fetch API that browsers support. In this article, we will take a look at how node-...| ScrapingBee – The Best Web Scraping API
It's a fine Sunday morning, and suddenly an idea for your next big project hits you: "How about I take the data provided by company X and build a frontend for it?" You jump into coding and realize that company X doesn't provide an API for their data. Their website is the only source for their data. It's time to resort to good old web scraping, the automated process to parse and extract data from the HTML source code of a website.| ScrapingBee – The Best Web Scraping API
The web is becoming an incredible data source. There are more and more data available online, from user-generated content on social media and forums, E-commerce websites, real-estate websites or media outlets... Many businesses are built on this web data, or highly depend on it. Manually extracting data from a website and copy/pasting it to a spreadsheet is an error-prone and time consuming process. If you need to scrape millions of pages, it's not possible to do it manually, so you should au...| ScrapingBee – The Best Web Scraping API
Go is a versatile language with packages and frameworks for doing almost everything. Today you will learn about one such framework called Colly that has greatly eased the development of web scrapers in Go. Colly provides a convenient and powerful set of tools for extracting data from websites, automating web interactions, and building web scrapers. In this article, you will gain some practical experience with Colly and learn how to use it to scrape comments from Hacker News.| ScrapingBee – The Best Web Scraping API
Scrapy is the most popular Python web scraping framework. In this tutorial we will see how to scrape an E-commerce website with Scrapy from scratch.| www.scrapingbee.com

Learn how to use Python wget with subprocess to automate file downloads. This guide covers installing wget, basic and advanced commands, saving files with custom names or folders, resuming interrupted downloads, and optional flags for speed and stability.| www.scrapingbee.com

Simple, transparent pricing for ScrapingBee web scraping API. Choose from Freelance, Startup, Business, or Enterprise plans. Cancel anytime.| www.scrapingbee.com
ScrapingBee is the best web scraping API that handles proxies and headless browsers for you — so you can focus on extracting the data you need.| www.scrapingbee.com
ScrapingBee is the best web scraping API that handles proxies and headless browsers for you — so you can focus on extracting the data you need.| www.scrapingbee.com
Web scraping woes? Slay blockades & bypass bots with the ultimate proxy API selection guide. Scrape smarter, not harder.| www.scrapingbee.com
How to extract content from a Shadow DOM Certain websites may hide all of their page content inside a shadow root, which makes scraping them quite challenging. This is because most scrapers cannot directly access HTML content embedded within a shadow root. Here is a guide on how you can extract such data via ScrapingBee. --- We will use a quite popular site as an example: www.msn.com If you inspect any article on this page, let’s use this one. You can see that all of its contents are inside...| ScrapingBee – The Best Web Scraping API

In this tutorial we'll show how to use a proxy with the Python Requests library and how to choose the right proxy provider.| www.scrapingbee.com
Effortlessly extract Google Finance data with our scraper. Access real-time financial information and automate data collection with a single API call.| www.scrapingbee.com
Tired of getting blocked when web scraping? Learn essential tips to stay undetected and gather the data you need. Plus, discover an easy solution!| www.scrapingbee.com

In this tutorial, we will learn how to scrape the web using BeautifulSoup and CSS selectors with step-by-step instructions.| www.scrapingbee.com
Learning how to scrape Amazon prices is a great way to access real-time product data for market research, competitor analysis, and price tracking. However, as the biggest retailer in the world, Amazon imposes many scraping restrictions to keep automated connections away from its sensitive price intelligence. The Amazon page uses dynamic JavaScript elements, aggressive anti-bot systems, and geo-based restrictions that make it difficult to extract price data. This tutorial will show you how to ...| ScrapingBee – The Best Web Scraping API
Scraping Yahoo search results and finance data is a powerful way to collect real-time insights on market trends, stock performance, and company profiles. With ScrapingBee, you can extract this information easily — even from JavaScript-heavy pages that typically block traditional scrapers. Yahoo’s dynamic content and anti-bot protections make it difficult to scrape using basic tools. But ScrapingBee handles these challenges out of the box. Our API automatically renders JavaScript, rotates ...| ScrapingBee – The Best Web Scraping API
Learning how to scrape Yellow Pages can unlock access to a rich database of business listings. With minimal technical knowledge, our approach to scraping HTML content extracts data that you can use for lead generation, market research, or local SEO. Like most online platforms rich with useful coding data, Yellow Pages present JavaScript-rendered content and anti-scraping measures, which often stop traditional scraping efforts. Our HTML API is built to export data while automatically handling ...| ScrapingBee – The Best Web Scraping API

Learn effective techniques for scraping Google Finance data efficiently. Enhance your data collection skills and start optimizing your research today!| www.scrapingbee.com
An easy way to get all relevant links of a website is by fetching links from its sitemap. In this blog post we will create an n8n workflow that uses scrapingbee to extract links from sitemap.| www.scrapingbee.com
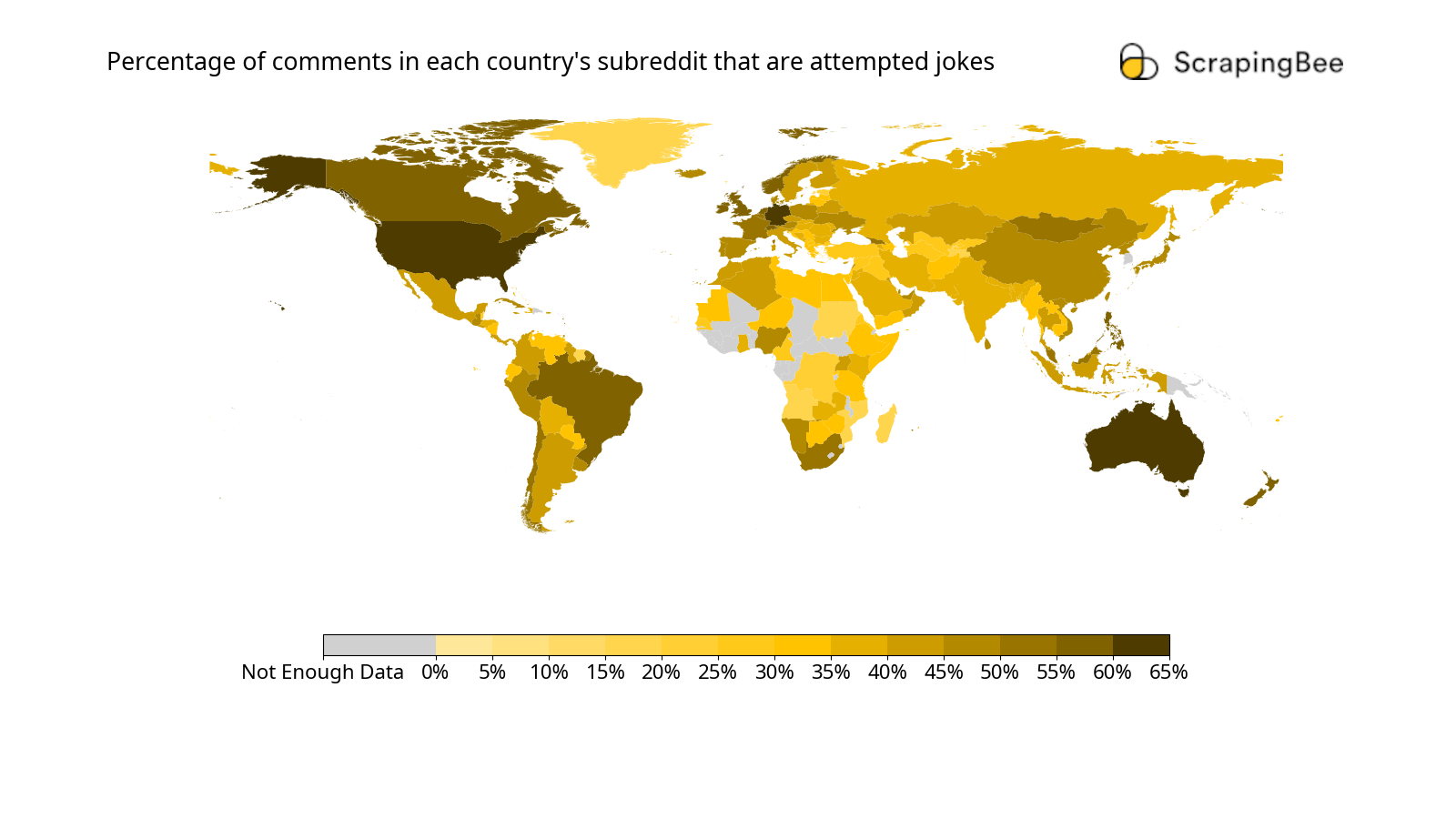
Explore global humor on Reddit! AI analyzes which nations joke most in this intriguing study of subreddit comments. Discover which countries try to be the funniest!| www.scrapingbee.com
Nowadays, most websites use different methods and techniques to decrease the load and data served to their clients’ devices. One of these techniques is the infinite scroll. In this tutorial, we will see how we can scrape infinite scroll web pages using a js_scenario, specifically the scroll_y and scroll_x features. And we will use this page as a demo. Only 9 boxes are loaded when we first open the page, but as soon as we scroll to the end of it, we will load 9 more, and that will kee...| ScrapingBee – The Best Web Scraping API
Here is a quick tutorial on how you may add items to a shopping cart on eCommerce websites using ScrapingBee API via a JS scenario on Python. 1. You would need to identify any CSS selector that uniquely identifies the button or 'add to cart' element you wish to click. This can be done via the inspect element option on any browser, more details can be found on this tutorial: https://www.scrapingbee.com/tutorials/how-to-extract-css-selectors-using-chrome/| ScrapingBee – The Best Web Scraping API
One of the most important features of ScrapingBee, is the ability to extract exact data without need to post-process the request’s content using external libraries. We can use this feature by specifying an additional parameter with the name extract_rules. We specify the label of elements we want to extract, their CSS Selectors and ScrapingBee will do the rest! Let’s say that we want to extract the title & the subtitle of the data extraction documentation page. Their CSS selectors are h...| ScrapingBee – The Best Web Scraping API
Open the Network tab in the DevTools Right click (or Ctrl-click) a request Click "Copy" → "Copy as cURL" You can now paste it in the relevant curl converter to translate it in the language you want| ScrapingBee – The Best Web Scraping API
Open the Network Monitor tab in the Developer Tools Right click (or Ctrl-click) a request Click "Copy" → "Copy as cURL" You can now paste it in the relevant curl converter to translate it in the language you want| ScrapingBee – The Best Web Scraping API
Open the Network tab in the Developer Tools Right click (or Ctrl-click or two-finger click) a request Click "Copy as cURL" in the dropdown menu You can now paste it in the relevant curl converter to translate it in the language you want| ScrapingBee – The Best Web Scraping API
Sometimes you may need to remove specific HTML elements from the page's content, either to get cleaner results for your data extraction rules, or to simply delete unnecessary content from your response. To achieve that using ScrapingBee, you can use aJavaScript Scenario, with an evaluate instruction and execute this custom JS code: document.querySelectorAll("ELEMENT-CSS-SELECTOR").forEach(function(e){e.remove();}); For example, to remove all of the <style> elements from the response, you c...| ScrapingBee – The Best Web Scraping API
Certain websites may require you to scroll in order to load more results on the page or within a specific element. This is a quick guide on how to achieve different scrolling behaviors using JavaScript scenario. *Note that the JavaScript Scenario has a maximum execution time limit of 40 seconds. Requests exceeding this limit will result in a timeout:https://www.scrapingbee.com/documentation/js-scenario/#timeout --- 1. Scrolling a Specific Element Some page elements, such as tables or graphs, ...| ScrapingBee – The Best Web Scraping API
Some pages load more content only after you click “Load more results” or scroll and wait. In reality, the page often fetches additional results from its own API. If ScrapingBee can’t load those results, you can target the site’s API URL directly. Here’s how to do that using this URL as an example: https://www.reuters.com/technology *Note that the JavaScript Scenario has a maximum execution time limit of 40 seconds. Requests exceeding this limit will result in a timeout:https://www.s...| ScrapingBee – The Best Web Scraping API
Our API is designed to allow you to have multiple concurrent scraping operations. That means you can speed up scraping for hundreds, thousands or even millions of pages per day, depending on your plan. The more concurrent requests limit you have the more calls you can have active in parallel, and the faster you can scrape. using System; using System.IO; using System.Net; using System.Web; using System.Threading; namespace test { class test{ private static string BASE_URL = "https://app.scrapi...| ScrapingBee – The Best Web Scraping API
Our API is designed to allow you to have multiple concurrent scraping operations. That means you can speed up scraping for hundreds, thousands or even millions of pages per day, depending on your plan. The more concurrent requests limit you have the more calls you can have active in parallel, and the faster you can scrape. Making concurrent requests in GoLang is as easy as adding a “go” keyword before our scraping functions! The code below will make two concurrent requests to ScrapingBee...| ScrapingBee – The Best Web Scraping API
Our API is designed to allow you to have multiple concurrent scraping operations. That means you can speed up scraping for hundreds, thousands or even millions of pages per day, depending on your plan. The more concurrent requests limit you have the more calls you can have active in parallel, and the faster you can scrape. Making concurrent requests in NodeJS is very straightforward using Cluster module. The code below will make two concurrent requests to ScrapingBee’s pages, and save the c...| ScrapingBee – The Best Web Scraping API
Our API is designed to allow you to have multiple concurrent scraping operations. That means you can speed up scraping for hundreds, thousands or even millions of pages per day, depending on your plan. The more concurrent requests limit you have the more calls you can have active in parallel, and the faster you can scrape. Making concurrent requests in PHP is as easy as creating threads for our scraping functions! The code below will make two concurrent requests to ScrapingBee’s pages and d...| ScrapingBee – The Best Web Scraping API
Our API is designed to allow you to have multiple concurrent scraping operations. That means you can speed up scraping for hundreds, thousands or even millions of pages per day, depending on your plan. The more concurrent requests limit you have the more calls you can have active in parallel, and the faster you can scrape. import concurrent.futures import time from scrapingbee import ScrapingBeeClient # Importing SPB's client client = ScrapingBeeClient(api_key='YOUR-API-KEY') # Initialize the...| ScrapingBee – The Best Web Scraping API
Our API is designed to allow you to have multiple concurrent scraping operations. That means you can speed up scraping for hundreds, thousands or even millions of pages per day, depending on your plan. The more concurrent requests limit you have the more calls you can have active in parallel, and the faster you can scrape. Making concurrent requests in Ruby is as easy as creating threads for our scraping functions! The code below will make two concurrent requests to ScrapingBee’s pages and ...| ScrapingBee – The Best Web Scraping API
For most websites, your first requests will always be successful, however, it’s inevitable that some of them will fail. For these failed requests, the API will return a 500 status code and won’t charge you for the request. In this case, we can make our code retry to make the requests until we reach a maximum number of retries that we set: using System; using System.IO; using System.Net; using System.Web; using System.Collections.Generic; namespace test { class test{ private static string ...| ScrapingBee – The Best Web Scraping API
For most websites, your first requests will always be successful, however, it’s inevitable that some of them will fail. For these failed requests, the API will return a 500 status code and won’t charge you for the request. In this case, we can make our code retry to make the requests until we reach a maximum number of retries that we set: package main import ( "fmt" "io" "net/http" "os" ) const API_KEY = "YOUR-API-KEY" const SCRAPINGBEE_URL = "https://app.scrapingbee.com/api/v1" func save...| ScrapingBee – The Best Web Scraping API
For most websites, your first requests will always be successful, however, it’s inevitable that some of them will fail. For these failed requests, the API will return a 500 status code and won’t charge you for the request. In this case, we can make our code retry to make the requests until we reach a maximum number of retries that we set: <?php // Get cURL resource $ch = curl_init(); // Set base url & API key $BASE_URL = "https://app.scrapingbee.com/api/v1/?"; $API_KEY = "YOUR-API-KEY"; /...| ScrapingBee – The Best Web Scraping API
For most websites, your first requests will always be successful, however, it’s inevitable that some of them will fail. For these failed requests, the API will return a 500 status code and won’t charge you for the request. In this case, we can make our code retry to make the requests until we reach a maximum number of retries that we set: from scrapingbee import ScrapingBeeClient # Importing SPB's clientclient = ScrapingBeeClient(api_key='YOUR-API-KEY') # Initialize the client with your A...| ScrapingBee – The Best Web Scraping API
For most websites, your first requests will always be successful, however, it’s inevitable that some of them will fail. For these failed requests, the API will return a 500 status code and won’t charge you for the request. In this case, we can make our code retry to make the requests until we reach a maximum number of retries that we set: require 'net/http' require 'net/https' require 'addressable/uri' # Classic (GET) def send_request(user_url) uri = Addressable::URI.parse("https://app.sc...| ScrapingBee – The Best Web Scraping API
In this tutorial, we will see how you can use ScrapingBee’s API with C#, and use it to scrape web pages. As such, we will cover these topics: General structure of an API request Create your first API request. Let’s get started! 1. General structure of an API request The general structure of an API request made in C# will always look like this: using System; using System.IO; using System.Net; using System.Web; namespace test { class test{ private static string BASE_URL = @"https://app.scra...| ScrapingBee – The Best Web Scraping API
In this tutorial, we will see how you can use ScrapingBee’s API with GoLang, and use it to scrape web pages. As such, we will cover these topics: General structure of an API request Create your first API request. Let’s get started! 1. General structure of an API request The general structure of an API request made in Go will always look like this: package main import ( "fmt" "io/ioutil" "net/http" "net/url" ) func get_request() *http.Response { // Create client client := &http.Client{} my...| ScrapingBee – The Best Web Scraping API
In this tutorial, we will see how you can use ScrapingBee’s API with PHP, and use it to scrape web pages. As such, we will cover these topics: General structure of an API request Create your first API request. Let’s get started! 1. General structure of an API request The general structure of an API request made in PHP will always look like this: <?php // Get cURL resource $ch = curl_init(); // Set base url & API key $BASE_URL = "https://app.scrapingbee.com/api/v1/?"; $API_KEY = "YOUR-API-...| ScrapingBee – The Best Web Scraping API
In this tutorial, we will see how you can use ScrapingBee’s API with Ruby, and use it to scrape web pages. As such, we will cover these topics: General structure of an API request Create your first API request. Let’s get started! 1. General structure of an API request The general structure of an API request made in Ruby will always look like this: require 'net/http' require 'net/https' # Classic (GET) def send_request api_key = "YOUR-API-KEY" user_url = "YOUR-URL" uri = URI('https://app.s...| ScrapingBee – The Best Web Scraping API
In this tutorial, we will see how you can integrate ScrapingBee’s API with NodeJS using our Software Development Kit (SDK), and use it to scrape web pages. As such, we will cover these topics: Install ScrapingBee’s NodeJS SDK Create your first API request. Let’s get started! 1. Install the SDK Before using an SDK, we will have to install the SDK. And we can do that using this command: npm install scrapingbee.| ScrapingBee – The Best Web Scraping API
In this tutorial, we will see how you can integrate ScrapingBee’s API with Python using our Software Development Kit (SDK), and use it to scrape web pages. As such, we will cover these topics: Install ScrapingBee’s Python SDK Create your first API request. Let's get started! 1. Install the SDK Before using an SDK, we will have to install the SDK. And we can do that using this command: pip install scrapingbee| ScrapingBee – The Best Web Scraping API
In this tutorial, I’ll show you how to scrape Pinterest using ScrapingBee’s API. Whether you want to scrape Pinterest data for trending images, individual pins, Pinterest profiles, or entire boards, this guide explains how to build a web scraper that works. Scraping Pinterest can be tough. Its anti-bot protection often trips up typical web scrapers. That's why I prefer using ScrapingBee. With this tool, you won't need to run a headless browser or wait for page elements to load manually. Y...| ScrapingBee – The Best Web Scraping API
Trying to learn how to scrape Glassdoor data? You're at the right place. In this guide, I’ll show you exactly how to extract job title descriptions, salaries, and company information using ScrapingBee’s powerful API. You may already know this – Glassdoor is a goldmine of information, but scraping it can be a challenging task. The site utilizes dynamic content loading and sophisticated bot protection. As a result, the Glassdoor website is out of reach for an average web scraper. I’ve s...| ScrapingBee – The Best Web Scraping API
Learning how to scrape Bing search results can feel like navigating a minefield of anti-bot measures and IP blocks. Microsoft's Bing search engine has sophisticated protection systems to detect traditional scraping attempts faster than you can debug your first request failure. That’s exactly why I use ScrapingBee. Instead of wrestling with proxy rotations, JavaScript rendering, and constantly changing anti-bot methods, this web scraper handles all the complexity. It allows you to scrape sea...| ScrapingBee – The Best Web Scraping API
Want to learn how to scrape TripAdvisor? Tired of overpaying for your trips? As one of the biggest online travel platforms, it has tons of valuable information that can help you save money and enjoy your time abroad. Scraping TripAdvisor is a great way to keep an eye on price changes, customer sentiment, and other details that can impact your trips and vacations. In this tutorial, we will explain how to extract hotel names, prices, ratings, and reviews from TripAdvisor using our web scraping ...| ScrapingBee – The Best Web Scraping API
If you want to learn how to scrape IMDb data, you’re in the right place. This step-by-step tutorial shows you how to extract data, including movie details, ratings, actors, and review dates, using a Python script. You’ll see how to set up the required libraries, process the HTML content, and store your results in a CSV file for further analysis using ScrapingBee’s API. Why ScrapingBee? Here's the thing – if you want to scrape IMDb data, you need an infrastructure of proxies, JavaScrip...| ScrapingBee – The Best Web Scraping API
In this guide, I'll teach you how to scrape Etsy, one of the most popular marketplaces for handmade and vintage items. If you've ever tried scraping Etsy before, you know it's not exactly a walk in the park. The website's anti-bot protections, such as CAPTCHA, IP address flagging, and constant updates, make web scraping Etsy product data a challenge. That’s why ScrapingBee's Etsy scraper is the best tool to get the job done. It's a reliable web scraper that helps you capture real-time data ...| ScrapingBee – The Best Web Scraping API
In this guide, we'll dive into how to scrape Indeed job listings without getting blocked. The first time I tried to extract job data from this website, it was tricky. I thought a simple requests.get() would do the trick, but within minutes I was staring at a CAPTCHA wall. That’s when I realized I needed a proper web scraper with proxy rotation and headers baked in to scrape job listing data.| ScrapingBee – The Best Web Scraping API
Ever wanted to extract valuable insights and data from largest encyclopedias online? Then it is it to learn how to scrape Wikipedia pages! As one of the biggest treasuries of structured content, it is constantly reviewed and fact-checked by fellow users, or at least provide valuable insights and links to sources. Wikipedia has structured content but scraping can be tricky due to rate limiting, which restricts repeated connection requests to websites. Fortunately, our powerful tools can overco...| ScrapingBee – The Best Web Scraping API
Have you ever tried learning how to scrape Craigslist and run into a wall of CAPTCHAs and IP blocks? Trust me, my first web scraping attempt was just as rocky. Craigslist is a gold mine of data. It contains everything from job ads, housing, items for sale, to various services. But it's not an easy nut to crack for beginners in scraping. Just like in any other web scraping project, you won't get anywhere without proxy rotation, JavaScript rendering, and solving CAPTCHAs. Fortunately, ScrapingB...| ScrapingBee – The Best Web Scraping API
Welcome to a guide on how to scrape Google images. We’ll dive into the exact process of extracting image URLs, titles, and source links from Google Images search results. By the end of this guide, you'll be able to get all the image data from multiple search pages. Here's the catch, though: to scrape data, you'll need a reliable tool, such as ScrapingBee. Since Google Images implements strong anti-scraping measures, you won't be able to get images without a strong infrastructure.| ScrapingBee – The Best Web Scraping API
As the the key source of information on the internet, Google contains a lot of valuable public data. Just like with most industries, for many, it is the main source for tracking flight prices plus departure and arrival locations for trips. As you already know, automation plays a vital role here, as everyone wants an optimal setup to compare multiple airlines and their pricing strategies to save money. Even better, collecting data with your own Google Flights scraper saves a lot of time and pr...| ScrapingBee – The Best Web Scraping API
Learning how to scrape Costco can be incredibly valuable for gathering product information, monitoring prices, or conducting market research. In my experience, while there are several approaches to utilize coding tools for scraping Costco's website, our robust HTML API offers the most straightforward solution that handles JavaScript rendering, proxy rotation, and other key elements that tend to overcomplicate data extraction. In this guide, we will cover how you can extract data from retailer...| ScrapingBee – The Best Web Scraping API
Learning how to scrape data from eBay efficiently requires the right tools and techniques. eBay’s complex structure and anti-scraping measures make it challenging to extract data reliably. In this guide, I’ll walk you through the entire process of setting up and running an eBay scraper that actually works. Whether you’re tracking prices, researching products, or gathering seller data, you’ll discover how to extract the information you need without getting blocked| ScrapingBee – The Best Web Scraping API
Expedia scraping is a great strategy for tracking of hotel prices, travel trends, and comparison of deals with real-time data. It’s especially useful for building tools that rely on dynamic hotel details like location, rating, and pricing strategies, but accessing these platforms is a lot harder with automated tools. The main challenge is that Expedia loads its content using JavaScript, so simple scrapers can’t see the hotel listings without rendering the page. On top of that, the site of...| ScrapingBee – The Best Web Scraping API
Want to extract app names, ratings, reviews, and install counts from Google Play? Scraping is one of the fastest ways to collect valuable mobile app data from Google Play, but dynamic content and anti-bot systems make traditional scrapers unreliable In this guide, we will teach you to scrape Google Play using Python and our beloved ScrapingBee API. Here you will find the basic necessities for your collection goals, helping you export data in clean, structured formats. Let’s make scraping si...| ScrapingBee – The Best Web Scraping API
Did you know that learning how to scrape Google Scholar can supercharge your research papers? This search engine is a gold mine of citations and scholarly articles that you could be analyzing at scale with a web scraper. With a reliable scraping service like ScrapingBee and some basic Python, you can automate repetitive research tasks more efficiently. Why ScrapingBee, you may ask? Well, let’s get one thing straight – Google Scholar has tight anti-scraping measures. It means that you need...| ScrapingBee – The Best Web Scraping API
Scraping Home Depot’s product data requires handling JavaScript rendering and potential anti-bot measures. With ScrapingBee’s API, you can extract product information from Home Depot without managing headless browsers, proxies, or CAPTCHAs Simply set up a request with JavaScript rendering enabled, target the correct URLs, and extract structured data using your preferred HTML parser. Our API handles all the complex parts of web scraping, letting you focus on using the data. In this guide, ...| ScrapingBee – The Best Web Scraping API
