
siboehm
Simon Boehm's technical blog| siboehm.com
At my job, I’m refactoring a 30k LOC codebase that simulates learning in the mammal brain. The emergent behavior of these large brain models is hard to test for, so we opted to take the safe route and preserve bit-equality in the weights of the trained model to guarantee that we are not breaking anything.The main downside of hash-based regression testing during refactoring is that it doesn’t check numerical stability. The most common change we applied was inlining many small functions to ...| siboehm
Pipeline parallelism makes it possible to train large models that don’t fit into a single GPU’s memory.Example: Huggingface’s BLOOM model is a 175B parameter Transformer model. Storing the weights as bfloat16 requires 350GB, but the GPUs they used to train BLOOM ‘only’ have 80GB of memory, and training requires much more memory than just loading the model weights. So their final training was distributed across 384 GPUs. This is made possible by assigning different layers of the mode...| siboehm
In this post, I want to have a look at a common technique for distributing model training: data parallelism. It allows you to train your model faster by replicating the model among multiple compute nodes, and dividing the dataset among them. Data parallelism works particularly well for models that are very parameter efficientMeaning a high ratio of FLOPS per forward pass / #parameters., like CNNs. At the end of the post, we’ll look at some code for implementing data parallelism efficiently,...| siboehm
Numpy can multiply two 1024x1024 matrices on a 4-core Intel CPU in ~8ms. This is incredibly fast, considering this boils down to 18 FLOPs / core / cycle, with a cycle taking a third of a nanosecond. Numpy does this using a highly optimized BLAS implementation.BLAS is short for Basic Linear Algebra Subprograms. These are libraries providing fast implementations of eg Matrix multiplications or dot-products. They are sometimes tailored to one specific (family of) CPUs, like Intel’s MKL or Appl...| siboehm
A list of (mostly software) tools that I use more than once a week. I recommend these to friends so often that I decided to write them up.| siboehm
I’m interested in strategies to improve deliberately and continuously as a programmer.I wrote up this post as a rough working note to get thoughts on it from others. I’ve thought about this on and off for the last two years, and have talked to ~25 experienced programmers about it. Mostly, it feels like “programmer training” is not a topic that is taken very seriously, probably because this skill is hard to quantify. As there are no established strategies, the potential returns to thin...| siboehm
Gradient-boosted decision trees are a commonly used machine learning algorithm that performs well on real-world tabular datasets. There are many libraries available for training them, most commonly LightGBM and XGBoost. Sadly few of the popular libraries are optimized for fast prediction & deployment. As a remedy, I spent the last few months building lleaves, an open-source decision tree compiler and Python package.| siboehm
A tool for searching through every document I've ever read, locally and within seconds.| siboehm
Mimetic theory is a simple but immensely powerful concept. It explains how humans learn, why laws exist, and why too many people want to go into Finance. The idea was developed by René Girard, a french philosopher, member of the Académie Française and professor at Stanford. In the last few years, independent of Girard’s research, studies into imitation, formation of desire, and mirror neurons have been published that bring forward empirical justification for the theory. Let’s start by ...| siboehm
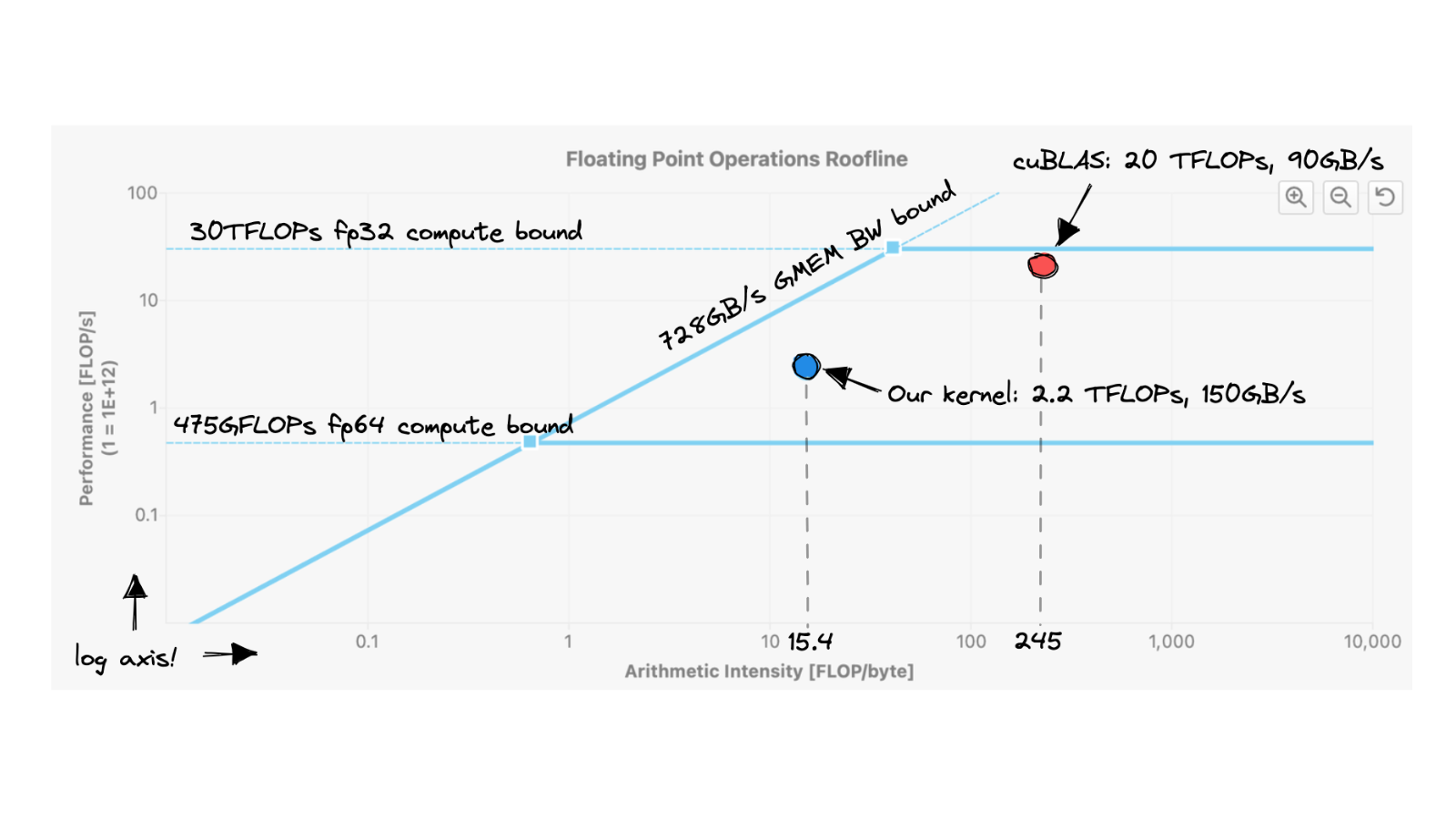
In this post, I’ll iteratively optimize an implementation of matrix multiplication written in CUDA.My goal is not to build a cuBLAS replacement, but to deepl...| siboehm.com
