AI Risk & Reliability - MLCommons
Support community development of AI risk and reliability tests and organize definition of research- and industry-standard AI safety benchmarks based on those tests.| MLCommons
Support community development of AI risk and reliability tests and organize definition of research- and industry-standard AI safety benchmarks based on those tests.| MLCommons

Methodology The MLCommons v0.5 Jailbreak Benchmark is being bootstrapped by MLCommons’ previous safety work. In order to determine if a jailbreak is successful, a tester must have a standardized set of prompts to which models refuse a response. The safety prompts provide this set. Establishing the Safety Baseline As such, we begin by characterizing a SUT’s behavior under standard conditions — those in use by a naïve, non-adversarial user — to establish a reference point for vulnerabi...| MLCommons
Stay UpdatedGet the latest MLCommons updates delivered fresh to your inbox| MLCommons
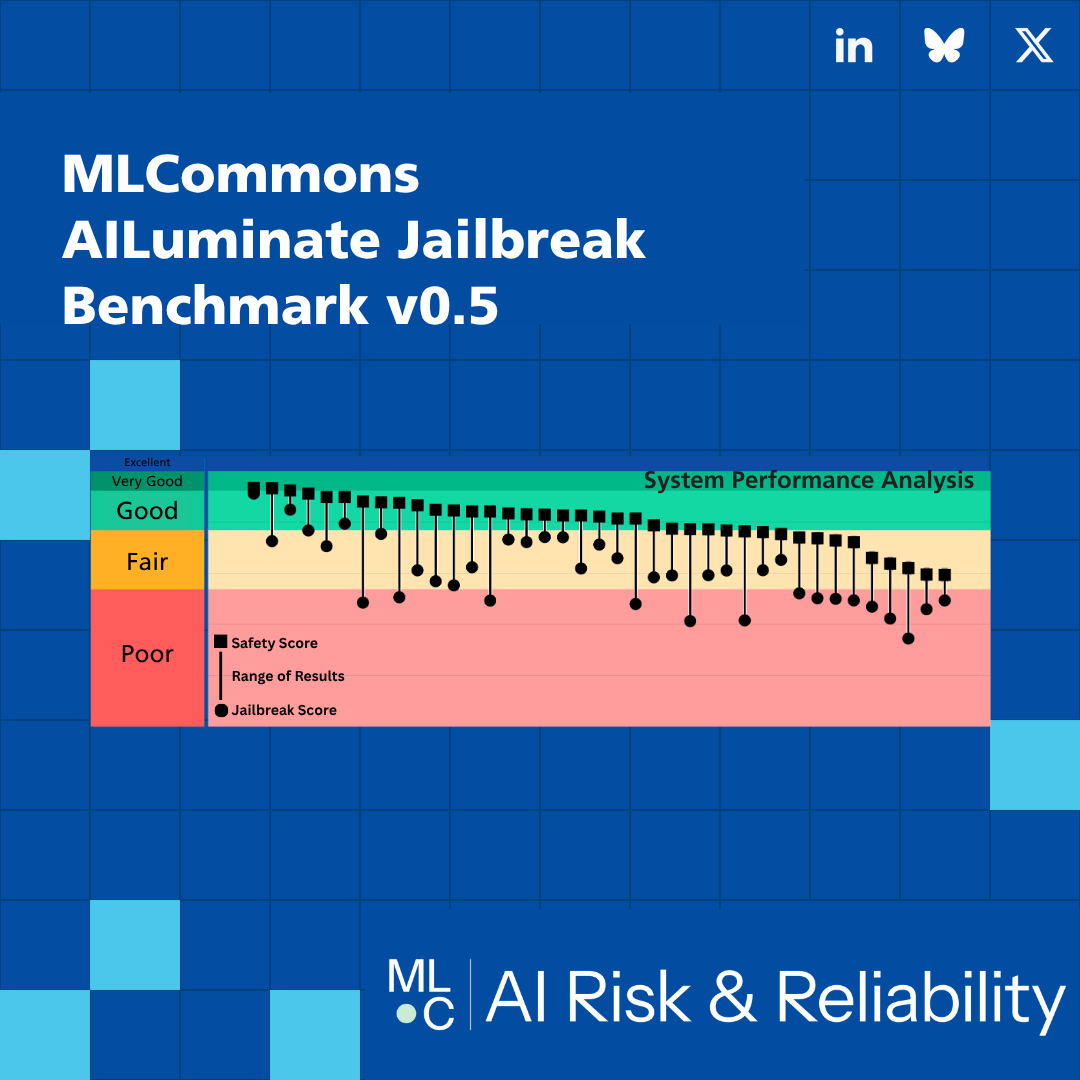
MLCommons AI jailbreak benchmark introduces the Resilience Gap metric, the first industry standard to measure AI safety under attack. Learn how it protects critical systems.| MLCommons

The MLPerf Tiny working group develops Tiny ML benchmarks to evaluate inference performance on ultra-low-power systems.| MLCommons
Eclair and Beyond: Revolutionizing Dataset Discovery and Use with LLMs The post Metadata, Meet Datasets: Croissant and MCP in Action appeared first on MLCommons.| MLCommons

A New TinyML Streaming Benchmark for MLPerf Tiny v1.3| MLCommons
The v1.0 AILuminate benchmark from the MLCommons AI Risk & Reliability working group is the first AI risk assessment benchmark developed with broad involvement from leading AI companies, academia, and civil society. It is a significant step towards standard risk assessment for “chat” style systems.| MLCommons
The MLPerf Inference: Datacenter benchmark suite measures how fast systems can process inputs and produce results using a trained model.| MLCommons
New data reveals advances in tiny neural network performance The post MLCommons New MLPerf Tiny 1.3 Benchmark Results Released appeared first on MLCommons.| MLCommons
New results highlight AI industry’s latest technical advances The post MLCommons Releases New MLPerf Inference v5.1 Benchmark Results appeared first on MLCommons.| MLCommons
Benchmarking the Next Generation of Reasoning LLMs with Long Output Sequences The post DeepSeek Reasoning for MLPerf Inference v5.1 appeared first on MLCommons.| MLCommons
MLCommons introduces a new small language model benchmark based on established industry methods such as Llama3.1-8B, vLLM, and the CNN-DailyMail dataset. The post MLPerf Inference 5.1: Benchmarking Small LLMs with Llama3.1-8B appeared first on MLCommons.| MLCommons

MLCommons introduces a new speech-to-text benchmark based on established industry methods such as Whisper-Large-V3 and the LibriSpeech dataset.| MLCommons

The MLPerf Automotive benchmark suite measures the performance of computers intended for automotive, both for Advanced Driving Assistance System/Autonomous Driving (ADAS/AD) and In-Vehicle Infotainment (IVI) embedded systems.| MLCommons

AVCC® and MLCommons® announced new results for their new MLPerf® Automotive v0.5 benchmark| MLCommons
New checkpoint benchmarks provide “must-have” information for optimizing AI training The post New MLPerf Storage v2.0 Benchmark Results Demonstrate the Critical Role of Storage Performance in AI Training Systems appeared first on MLCommons.| MLCommons

MLCommons, MLPerf Storage v2.0 Addressing Backup and Recovery Speed for Training Large Language Models on Scale-Out Clusters| MLCommons

MLCommons Releases MLPerf Client v1.0 with Expanded Models, Prompts, and Hardware Support, Standardizing AI PC Performance.| MLCommons

The MLCommons Croissant working group standardizes how ML datasets are described to make them easily discoverable and usable across tools and platforms.| MLCommons

MLCommons AAAI 2025 standardization collaboration evaluation in ai safety| MLCommons
The website from which you got to this page is protected by Cloudflare. Email addresses on that page have been hidden in order to keep them from being accessed by malicious bots. You must enable Javascript in your browser in order to decode the e-mail address.| mlcommons.org

CKAN supports the MLCommons Croissant metadata standard| MLCommons

Research funded through a grant by MLCommons and published by the Open Data Institute and the Pratt School of Engineering at Duke University explores the motivations driving data sharing throughout the AI ecosystem.| MLCommons
MLPerf Inference Datacenter Round 4.0 Date of Change Result ID Submitter Type of Change Reason for Change 8/28/24 4.0-0038 Dell Results invalidated Submitted as “preview,” but validation results were not submitted to “available” in the subsequent round. 8/28/24 4.0-0050 HPE Results invalidated Submitted as “preview,” but validation results were not submitted to “available” in the subsequent round. 8/28/24 4.0-0059 Lenovo Results invalidated Submitted as “preview,” but vali...| MLCommons

Announcing the release of the MLComons AI Safety v0.5 benchmark proof-of-concept focusing on measuring the safety of LLMs| MLCommons

The MLPerf Benchmark Suites measures how fast machine learning systems can train models to a target quality metric using v2.0 results.| MLCommons
